溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“python數學建模之Numpy和Pandas應用實例分析”,內容詳細,步驟清晰,細節處理妥當,希望這篇“python數學建模之Numpy和Pandas應用實例分析”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
# Numpy的基本使用 ''' Numpy提供了兩種基本的對象:ndarray存儲單一數據類型的多維數組; ufunc是能夠對數組進行處理的函數 1-導入函數 import numpy as np 2-數組創建 2-1 array 可將列表或元組轉化為ndarray數組 2-2 arange 在給定區間內創建等差數組,格式: arange(start=None, stop=None, step=None,dtype=None) 【step表示步長間隔】 2-3 linspace 在給定區間內創建間隔相等的數組,格式: linspace(start, stop, num=50, endpoint=True) 【間隔相等的num個數據,其num默認值是50】 2-4 logspace 在給定區間內生成等比數組,格式: logspace(start, stop, num=50, endpoint=True, base=10.0) 【默認生成區間[10start(次方), 10stop()次方]上的num個數據的等比數組】 以及 ones、zeros、empty和ones_like等系列函數的運用: '''
# numpy.array
# array()函數,括號內可以是列表、元組、數組、迭代對象、生成器
import numpy as np
print(np.array([6, 6, 6])) # 列表
print(np.array((8, 8, 8))) # 元組
print(np.array(np.array([9, 9, 9]))) # 數組
print(np.array(range(10))) # 迭代對象 / 整型
print(np.array([i**2 for i in range(10)])) # 生成器
# 創建10以內的奇數的數組:
print(np.array([i for i in range(1, 10, 2)]))
print(np.array([i for i in range(10) if i % 2 != 0]))
# 創建10以內的偶數的數組:
print(np.array([i for i in range(0, 10, 2)]))
print(np.array([i for i in range(10) if i % 2 == 0]))
# 列表中元素類型不相同
print(np.array([5, 2, '0'])) # ['5' '2' '0']
# 浮點型
print(np.array([3, 4, 5.2]))
# 二維數組:【嵌套序列(列表、元組均可)】
print(np.array([[6, 7, 8], ('lxw', 'cw', 'wl')]))
print(np.array([[6, 7, 8], ('lxw', 'cw', 'wl')]).ndim) # ndim(維度): 2
# 嵌套數量不一致:【強制轉化為一維,推薦不用】
print(np.array([[6, 7, 8], ('lxw', 'cw', 'wl', 'npy')], dtype=object))
print(np.array([[6, 7, 8], ('lxw', 'cw', 'wl', 'npy')], dtype=object).ndim) # ndim(維度):1
print(np.array([[6, 7, 8], ('lxw', 'cw', 'wl', 'npy')], dtype=object).shape) # 運行結果:(2,)
print(np.array([[6, 7, 8], [9, 9, 6, 9]], dtype=object))
print(np.array([[6, 7, 8], [9, 9, 6, 9]], dtype=object).ndim) # ndim(維度):1
print(np.array([[6, 7, 8], [9, 9, 6, 9]], dtype=object).shape) # 運行結果:(2,) -> 代表兩行一列# numpy.empty ''' numpy.empty 方法用來創建一個指定形狀(shape)、數據類型(dtype)且未初始化的數組 numpy.empty(shape, dtype = float, order = 'C') 參數說明: 參數 描述 shape 數組形狀 dtype 數據類型,可選 order 有"C"和"F"兩個選項,分別代表,行優先和列優先,在計算機內存中的存儲元素的順序 ''' import numpy as np lxw = np.empty([3, 4], dtype=int) print(lxw) # 注意:數組元素為隨機值,因為它們未初始化
# numpy.zeros
'''
創建指定大小的數組,數組元素以 0 來填充:
numpy.zeros(shape, dtype = float, order = 'C')
參數說明:
order : 'C' 用于 C 的行數組,或者 'F' 用于 FORTRAN 的列數組
'''
import numpy as np
lxw = np.zeros(6) # 默認為浮點數
print(lxw)
lxw2 = np.zeros((6, ), dtype=int) # 設置類型為整數
print(lxw2)
# 自定義類型
lxw3 = np.zeros((2, 2), dtype=[('lxw', 'i2'), ('lxw2', 'i4')])
print(lxw3)# numpy.ones '''創建指定形狀的數組,數組元素以 1 來填充: numpy.ones(shape, dtype = None, order = 'C') ''' import numpy as np lxw4 = np.ones(8) # 默認浮點數 print(lxw4) lxw5 = np.ones([2, 2], dtype=int) print(lxw5)
# numpy.asarray ''' numpy.asarray 類似 numpy.array,但 numpy.asarray 參數只有三個,比 numpy.array 少兩個。 numpy.asarray(a, dtype = None, order = None) 參數說明: 參數 描述 a 任意形式的輸入參數,可以是,列表, 列表的元組, 元組, 元組的元組, 元組的列表,多維數組 ''' # 將列表轉換為 ndarray: import numpy as np x = [5, 2, 0] lxw6 = np.asarray(x) print(lxw6) # 將元組轉換為 ndarray import numpy as np x2 = (1, 3, 1, 4) lxw7 = np.asarray(x2) print(lxw7) # 設置了 dtype 參數 import numpy as np x4 = [6, 6, 9] lxw9 = np.asarray(x4, dtype=float) print(lxw9)
# numpy.frombuffer ''' numpy.frombuffer 用于實現動態數組;接受 buffer 輸入參數,以流的形式讀入轉化成 ndarray 對象。 格式如下: numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0) 注:buffer 是字符串的時候,Python3 默認 str 是 Unicode 類型,所以要轉成 bytestring 在原 str 前加上 b。 參數說明: 參數 描述 buffer 可以是任意對象,會以流的形式讀入。 dtype 返回數組的數據類型,可選 count 讀取的數據數量,默認為-1,讀取所有數據。 offset 讀取的起始位置,默認為0 ''' import numpy as np s = b'lxw_pro' lxw10 = np.frombuffer(s, dtype='S1') print(lxw10)
# numpy.fromiter ''' numpy.fromiter 方法從可迭代對象中建立 ndarray 對象,返回一維數組。 numpy.fromiter(iterable, dtype, count=-1) ''' import numpy as np lst = range(6) it = iter(lst) lxw11 = np.fromiter(it, dtype=float) print(lxw11)
# numpy.arange ''' numpy 包中的使用 arange 函數創建數值范圍并返回 ndarray 對象,函數格式如下: numpy.arange(start, stop, step, dtype) 根據 start 與 stop 指定的范圍以及 step 設定的步長,生成一個 ndarray。 參數說明: 參數 描述 start 起始值,默認為0 stop 終止值(不包含) step 步長,默認為1 dtype 返回ndarray的數據類型,如果沒有提供,則會使用輸入數據的類型 ''' # 生成0和5的數組 import numpy as np a = np.arange(6) print(a) # 設置返回類型位 float import numpy as np a2 = np.arange(6, dtype=float) print(a2) # 設置了起始值、終止值及步長 import numpy as np a3 = np.arange(20, 52, 5) print(a3)
# numpy.linspace ''' numpy.linspace 函數用于創建一個一維數組,數組是一個等差數列構成的,格式如下: np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) 參數說明: 參數 描述 start 序列的起始值 stop 序列的終止值,如果endpoint為true,該值包含于數列中 num 要生成的等步長的樣本數量,默認為50 endpoint 該值為 true 時,數列中包含stop值,反之不包含,默認是True。 retstep 如果為 True 時,生成的數組中會顯示間距,反之不顯示。 dtype ndarray 的數據類型 ''' # 類似等差數列 import numpy as np a4 = np.linspace(1, 10, 5) print(a4) # 設置元素全部是1的等差數列 import numpy as np a5 = np.linspace(1, 1, 10) print(a5) # 將 endpoint 設為 false,不包含終止值 import numpy as np a6 = np.linspace(8, 22, 4, endpoint=False) print(a6) # 注:將 endpoint 設為 true,則會包含 22 a6 = np.linspace(8, 22, 4, endpoint=True) print(a6) # 設置間距 import numpy as np a7 = np.linspace(5, 10, 5).reshape([5, 1]) print(a7)
# numpy.logspace ''' numpy.logspace 函數用于創建一個于等比數列。格式如下: np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None) base 參數意思是取對數的時候 log 的下標。 參數 描述 start 序列的起始值為:base ** start stop 序列的終止值為:base ** stop。如果endpoint為true,該值包含于數列中 num 要生成的等步長的樣本數量,默認為50 endpoint 該值為 true 時,數列中中包含stop值,反之不包含,默認是True。 base 對數 log 的底數。 dtype ndarray 的數據類型 ''' import numpy as np a8 = np.logspace(1, 2, num=10) # 默認底數是 10 print(a8) # 將對數的底數設置為 2 import numpy as np a9 = np.logspace(0, 8, 9, base=2) print(a9)
# 綜合運用 import numpy as np ltw = np.array([3, 3, 4, 4]) # 生成整型數組 ltw2 = ltw.astype(float) # 轉為浮點數 ltw3 = np.array([5, 2, 1], dtype=float) # 浮點數 print(ltw) print(ltw2) print(ltw3) # 比較類型 print(ltw.dtype, ltw2.dtype, ltw3.dtype) aa = np.array([ [2, 5, 8], [9, 6, 2] ]) print(aa) bb = np.arange(2, 9) print(bb) # 運行結果為:[2 3 4 5 6 7 8] cc = np.linspace(2, 5, 4) print(cc) # 運行結果為:[2. 3. 4. 5.] dd = np.logspace(1, 4, 4, base=2) # base控制的是幾次方 print(dd) # 運行結果為:[ 2. 4. 8. 16.]
# 綜合運用【ones、zeros、empty、ones_like】 import numpy as np a = np.ones(6, dtype=int) print(a) # 運行結果為:[1 1 1 1 1 1] b = np.ones((6,), dtype=int) print(b) # 運行結果為:[1 1 1 1 1 1] c = np.ones((3, 1)) print(c) # 輸出3行一列的數組 # 運行結果為: # [[1.] # [1.] # [1.]] d = np.zeros(4) print(d) # 運行結果為:[0. 0. 0. 0.] e = np.empty(3) print(e) # 生成3個元素的空數組行向量 # 運行結果為:[1. 1. 1.] f = np.eye(3) print(f) # 生成3階單位陣 # 運行結果為: # [[1. 0. 0.] # [0. 1. 0.] # [0. 0. 1.]] g = np.eye(3, k=1) print(g) # 生成第k對角線的元素為1,其他元素為0的3階方陣 # 運行結果為: # [[0. 1. 0.] # [0. 0. 1.] # [0. 0. 0.]] h = np.zeros_like(b) print(h) # 生成與a同維數的全0數組 # 運行結果為:[0 0 0 0 0 0]
# NumPy 切片和索引 ''' ndarray對象的內容可以通過索引或切片來訪問和修改,與 Python 中 list 的切片操作一樣。 ndarray 數組可以基于 0 - n 的下標進行索引, 切片對象可以通過內置的 slice 函數,并設置 start, stop 及 step 參數進行,從原數組中切割出一個新數組 ''' import numpy as np # 通過 arange() 函數創建 ndarray 對象 a = np.arange(10) lxw = slice(2, 9, 3) # 索引從2到9,間隔為3 print(a[lxw]) # [2 5 8] # 通過切片操作 a = np.arange(10) lxw2 = a[2:9:3] # 這里的切片操作和Python中list的操作是一樣的 print(lxw2) # [2 5 8] # 比如: import numpy as np lxw3 = np.arange(10) print(lxw3[6]) # 6 print(lxw3[6:]) # [6 7 8 9] print(lxw3[2:7]) # [2 3 4 5 6] # 多維數組同樣適用上述索引提取方法 import numpy as np lxw4 = np.array([ [6, 6, 6], [5, 2, 0], [5, 8, 9] ]) print(lxw4) print(lxw4[1:]) # 切片還可以包括省略號 …,來使選擇元組的長度與數組的維度相同。 # 如果在行位置使用省略號,它將返回包含行中元素的 ndarray import numpy as np lxw5 = np.array([ [1, 2, 9], [2, 5, 4], [3, 4, 8] ]) print(lxw5[1, ...]) # [2 5 4] 第二行元素 print(lxw5[..., 2]) # [9 4 8] 第三列元素 print(lxw5[1:, ...]) # 第二行及剩下元素 print(lxw5[..., 1:]) # 第二列及剩下元素
Numpy中的array數組與Python基礎數據結構列表(list)的區別是:
列表中的元素可以是不同的數據類型array數組只允許存儲相同的數據類型
NumPy 比一般的 Python 序列提供更多的索引方式。
除了之前看到的用整數和切片的索引外,數組可以由
整數數組索引布爾索引花式索引
# 1-整數數組索引 import numpy as np b = np.array([ [6, 2, 9], [4, 3, 9], [5, 2, 3] ]) lxw6 = b[ [0, 1, 2], [1, 2, 1] ] print(lxw6) # 輸出 [2 9 2] # 獲取四個角元素 import numpy as np aq = np.array([ [1, 2, 3, 4], [2, 3, 4, 5], [3, 4, 5, 6], [4, 5, 6, 7] ]) print(aq) hj = np.array([[0, 0], [3, 3]]) lj = np.array([[0, 3], [0, 3]]) yq = aq[hj, lj] print(yq) print() # 可借助切片 : 或 … 與索引數組組合: import numpy as np jz = np.array([ [3, 5, 9], [5, 2, 6], [2, 9, 8] ]) jz1 = jz[:2, :2] print(jz1) jz2 = jz[:2, [0, 1]] print(jz2) jz3 = jz[..., 1:] print(jz3)
# 布爾索引 # 布爾索引可通過布爾運算(如:比較運算符)來獲取符合指定條件的元素的數組 # 獲取大于5的元素: import numpy as np br = np.array([ [6, 7, 8], [5, 2, 1], [6, 6, 9], [2, 4, 5] ]) print(br) print(br[br > 5]) # 輸出 [6 7 8 6 6 9] # 使用 ~(取補運算符)來過濾 NaN: import numpy as np bu = np.array([5, np.nan, 2, 0, np.nan, np.nan, 5, 8]) print(bu[~np.isnan(bu)]) # 輸出 [5. 2. 0. 5. 8.] # 從數組中過濾掉非復數元素: import numpy as np lv = np.array([2+2.9j, 4, 9, 2+8.2j, 8]) print(lv[np.iscomplex(lv)]) # 輸出 [2.+2.9j 2.+8.2j]
# 花式索引【利用整數數組進行索引】 # 花式索引根據索引數組的值作為目標數組的某個軸的下標來取值。 # 對于使用一維整型數組作為索引,如果目標是一維數組,那么索引的結果就是對應下標的行, # 如果目標是二維數組,那么就是對應位置的元素。 # 注:花式索引跟切片不一樣,它總是將數據復制到新數組中。 # 1.傳入順序索引數組 import numpy as np sx = np.arange(32).reshape(8, 4) print(sx[[5, 2, 1, 6]]) # 2.傳入倒序索引數組 import numpy as np dx = np.arange(32).reshape(8, 4) print(dx[[-5, -2, -1, -6]]) # 3.傳入多個索引數組(要使用np.ix_) import numpy as np dg = np.arange(32).reshape(8, 4) print(dg[np.ix_([2, 3, 5, 1], [3, 2, 0, 1])])
三個實用小方法:
條件加小括號
使用np.logical_and方法
使用np.all方法
import numpy as np sy = np.array([ [3, 5, 6], [2, 6, 2], [5, 2, 0], [3, 3, 4] ]) # 原數組 print(sy) # 1- print(sy[(sy > 3) & (sy < 6)]) # 條件記得加小括號 # 2- print(sy[np.logical_and(sy > 3, sy < 6)]) # 3- print(sy[np.all([sy > 3, sy < 6], axis=0)])
相關代碼如下:
import numpy as np x = np.arange(16).reshape(4, 4) print(x) # 生成4行4列的數組 x2 = x[2][1] print(x2) # 輸出 9 x3 = x[2, 1] print(x3) # 輸出 9 x4 = x[1:2, 2:4] print(x4) # 輸出 [[6 7]] xx = np.array([0, 1, 2, 1]) print(x[xx == 1]) # 輸出x的第2、4行元素
# Pandas學習(續) # Pandas庫是在Numpy庫基礎上開發的一種數據分析工具 ''' Pandas主要提供了三種數據結構: 1-Series: 帶標簽的一維數組 2-DataFrame: 帶標簽且大小可變得二維表格結構 3-Panel: 帶標簽且大小可變得三維數組 ''' # 生成二維數組 # 生成服從標準正態分布的24*4隨機數矩陣,并保存為DataFrame數據結構。 import pandas as pd import numpy as np dates = pd.date_range(start='20220622', end='20220707', freq='D') print(dates)
運行效果如下:
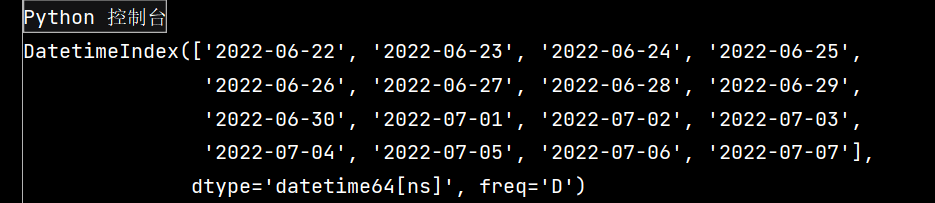
lxw1 = pd.DataFrame(np.random.randn(16, 4), index=dates, columns=list('ABCD'))
lxw2 = pd.DataFrame(np.random.randn(16, 4))
print(lxw1)
print(lxw2)運行結果如下:
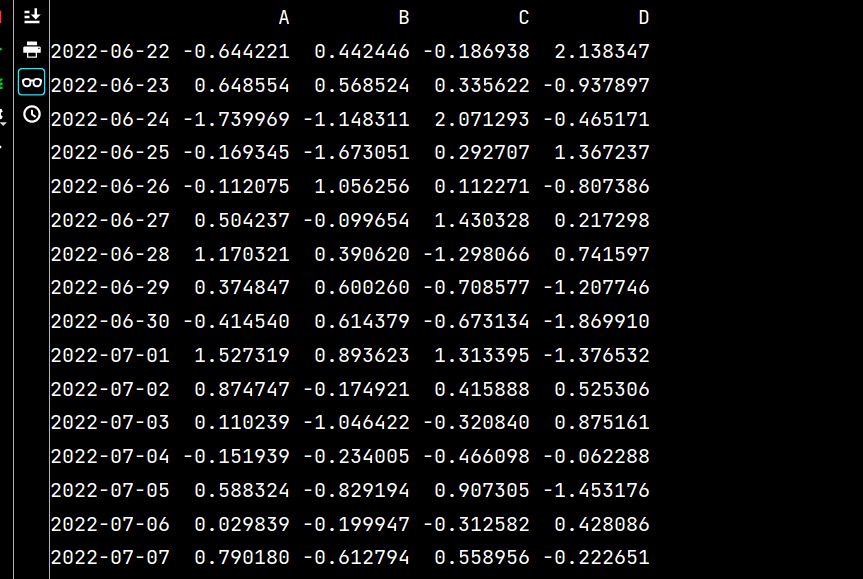
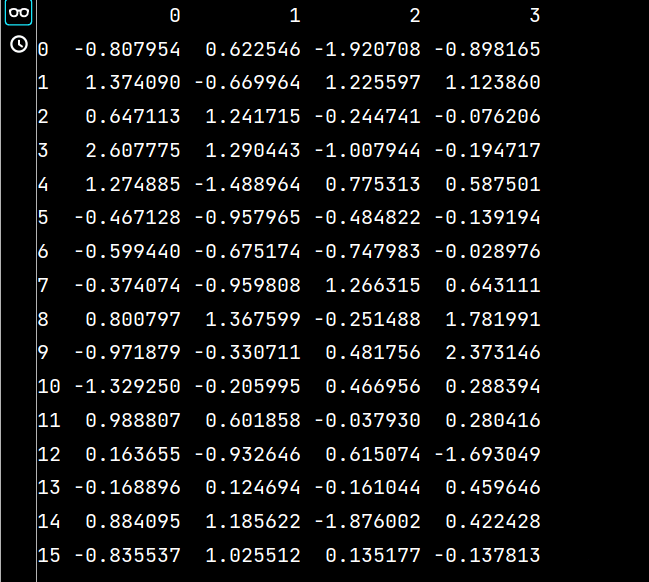
# 將lxw1的數據寫入excel文件
lxw1.to_excel('假期培訓時間.xlsx')
lxw1.to_excel("時間任意.xlsx", index=False) # 不包含行索引
# 將lxw2的數據寫入csv文件
lxw2.to_csv('假期培訓時間.csv')
lxw2.to_csv("時間隨意.csv", index=False) # 不包含行索引
# 創建文件對象
f = pd.ExcelWriter('培訓時間(格式).xlsx')
# 把lxw1寫入Excel文件
lxw1.to_excel(f, "Shell1")
# 把lxw2寫入Excel文件
lxw2.to_excel(f, "Sheet2")
f.save()部分效果圖如下:
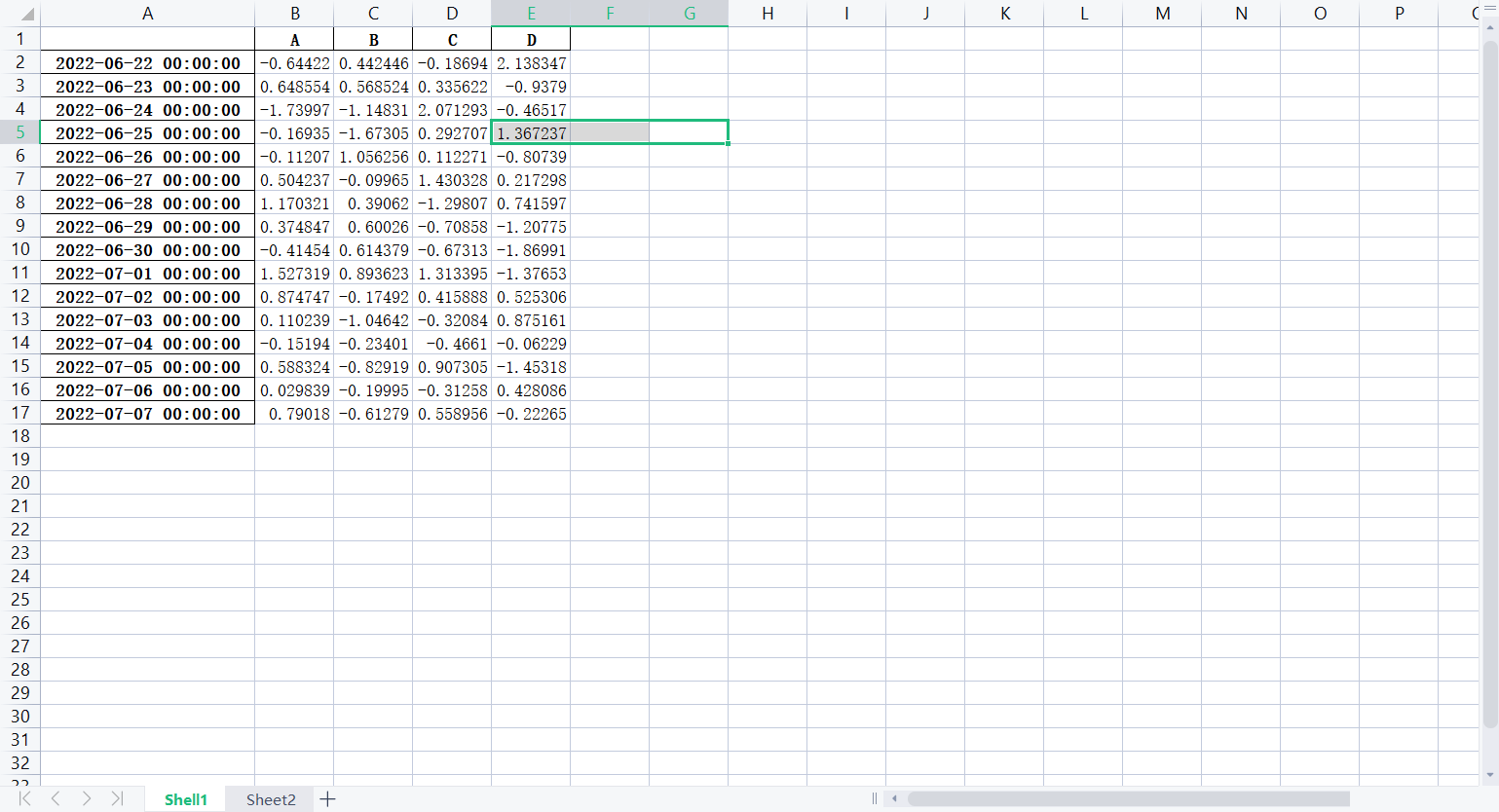
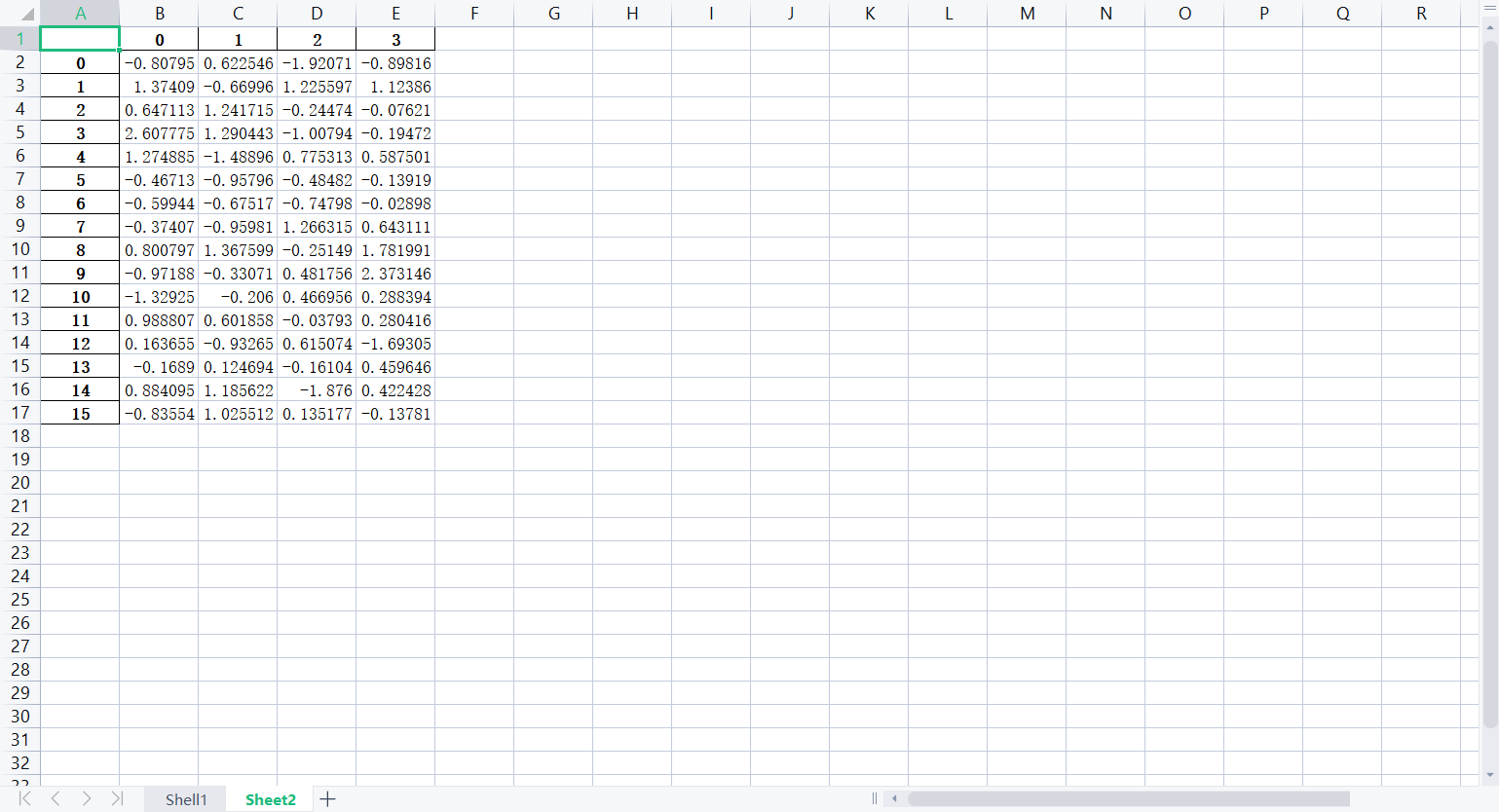
# 從文件中讀入數據:
import pandas as pd
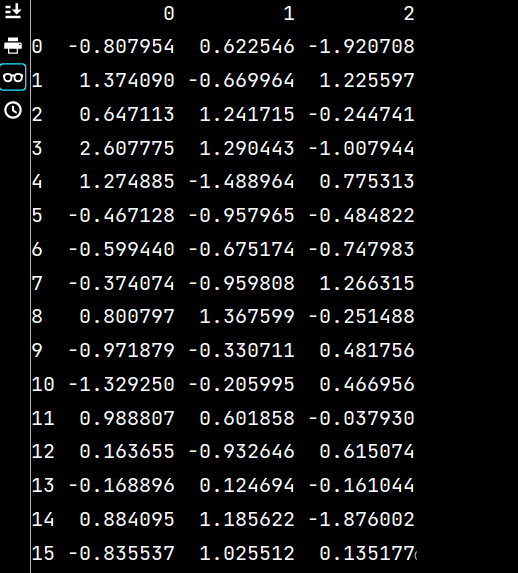
lxw3 = pd.read_csv("假期培訓時間.csv", usecols=range(1, 4))
print(lxw3)運行結果如下:
lxw4 = pd.read_excel("培訓時間(格式).xlsx", "Sheet2", usecols=range(1, 3))
print(lxw4)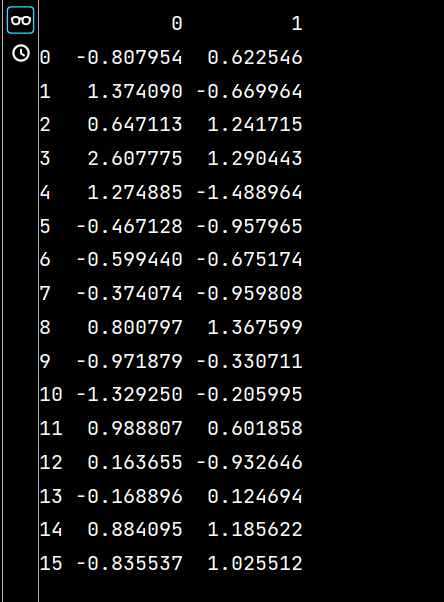
# 數據的一些預處理
# DataFrame數據的拆分、合并和分組計算:
import pandas as pd
import numpy as np
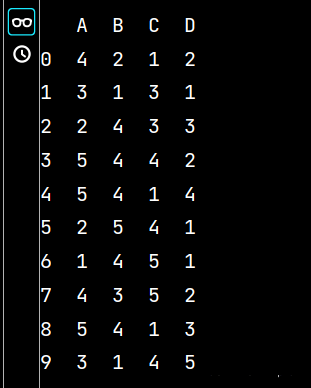
lxw5 = pd.DataFrame(np.random.randint(1, 6, (10, 4)), columns=list('ABCD'))
print(lxw5)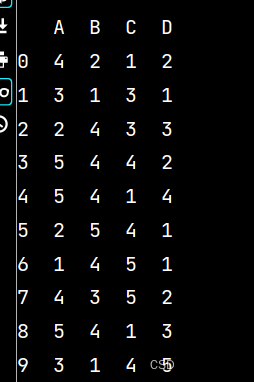
lxww = lxw5[:5] # 獲取前五行數據 print(lxww)

lxwy = lxw5[5:] # 獲取第六行以后的數據 print(lxwy)

wy = pd.concat([lxww, lxwy]) # 數據行合并 print(wy)
q1 = lxw5.groupby('A').mean() # 數據分組求均值
print(np.around(q1, decimals=2)) # decimals表示保留幾位小數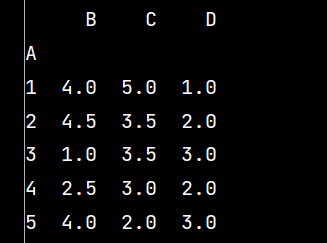
q2 = lxw5.groupby('A').apply(sum) # 數據分組求和
print(q2)
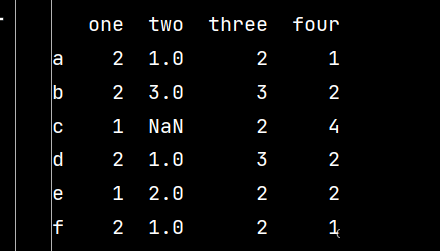
# 數據的選取與操作 ''' 對DataFrame進行選取,要從3個層次考慮:行列、區域、單元格 1-選用中括號[]選取行列 2-使用行和列的名稱進行標簽定位的df.loc[] 3-使用整型索引(絕對位置索引)的df.iloc[] 當然,在數據預處理中,需要對缺失值等進行一些特殊處理 ''' # 數據操作: import pandas as pd import numpy as np qq = pd.DataFrame(np.random.randint(1, 5, (6, 4)), index=['a', 'b', 'c', 'd', 'e', 'f'], columns=['one', 'two', 'three', 'four']) qq.loc['c', 'two'] = np.nan # 修改第三行第二列的數據 print(qq)
ww = qq.iloc[1:4, 0:2] # 提取第二、三、四行,第一、二列數據 print(ww)

qq['five'] = 'lxw' # 增加第五列數據 print(qq)
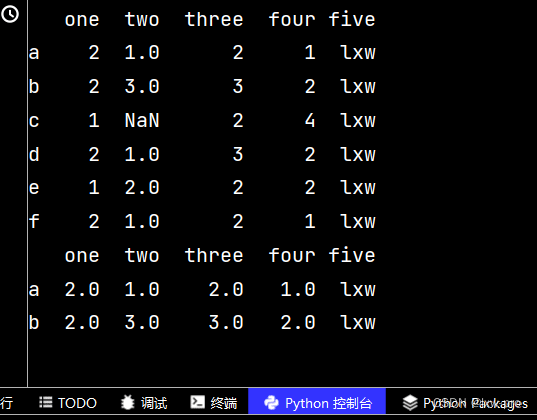
qq2 = qq.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g']) # 增加行名 print(qq2)
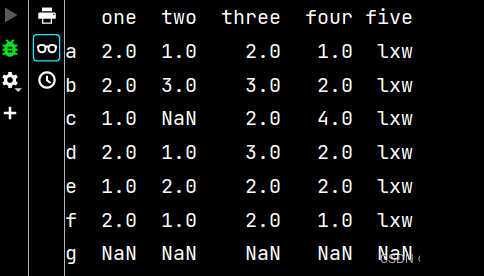
qq3 = qq2.dropna() # 刪除有不確定值的行 print(qq3) # 從輸出不難看出,刪除了c行和g行
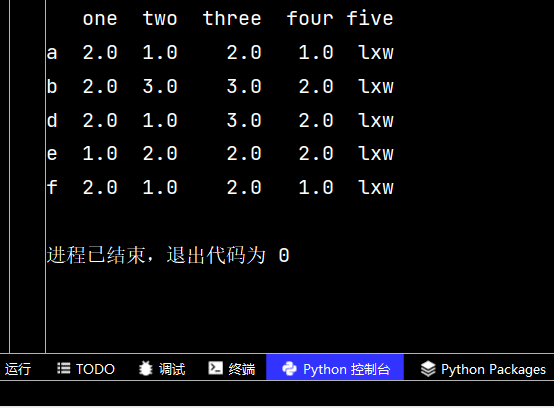
讀到這里,這篇“python數學建模之Numpy和Pandas應用實例分析”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





