溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Caffe卷積神經網絡視覺層Vision Layers及參數實例分析”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Caffe卷積神經網絡視覺層Vision Layers及參數實例分析”文章吧。
就是卷積層,是卷積神經網絡(CNN)的核心層。
層類型:Convolution
lr_mult: 學習率的系數,最終的學習率是這個數乘以solver.prototxt配置文件中的base_lr。
如果有兩個lr_mult, 則第一個表示權值的學習率,第二個表示偏置項的學習率。一般偏置項的學習率是權值學習率的兩倍。
在后面的convolution_param中,我們可以設定卷積層的特有參數。
必須設置的參數:
num_output: 卷積核(filter)的個數
kernel_size: 卷積核的大小。如果卷積核的長和寬不等,需要用kernel_h和kernel_w分別設定
其它參數:
stride: 卷積核的步長,默認為1。也可以用stride_h和stride_w來設置。
pad: 擴充邊緣,默認為0,不擴充。 擴充的時候是左右、上下對稱的,比如卷積核的大小為5*5,那么pad設置為2,則四個邊緣都擴充2個像素,即寬度和高度都擴充了4個像素,這樣卷積運算之后的特征圖就不會變小。也可以通過pad_h和pad_w來分別設定。
weight_filler: 權值初始化。 默認為“constant",值全為0,很多時候我們用"xavier"算法來進行初始化,也可以設置為”gaussian"
bias_filler: 偏置項的初始化。一般設置為"constant",值全為0。
bias_term: 是否開啟偏置項,默認為true, 開啟
group: 分組,默認為1組。如果大于1,我們限制卷積的連接操作在一個子集內。如果我們根據圖像的通道來分組,那么第i個輸出分組只能與第i個輸入分組進行連接。
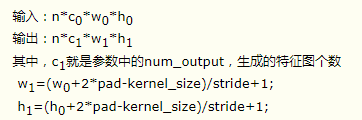
如果設置stride為1,前后兩次卷積部分存在重疊。如果設置pad=(kernel_size-1)/2,則運算后,寬度和高度不變。
示例:
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}也叫池化層,為了減少運算量和數據維度而設置的一種層。
層類型:Pooling
必須設置的參數:
kernel_size: 池化的核大小。也可以用kernel_h和kernel_w分別設定。
其它參數:
pool: 池化方法,默認為MAX。目前可用的方法有MAX, AVE, 或STOCHASTIC
pad: 和卷積層的pad的一樣,進行邊緣擴充。默認為0
stride: 池化的步長,默認為1。一般我們設置為2,即不重疊。也可以用stride_h和stride_w來設置。
示例:
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}pooling層的運算方法基本是和卷積層是一樣的。

如果設置stride為2,前后兩次卷積部分不重疊。100*100的特征圖池化后,變成50*50.
此層是對一個輸入的局部區域進行歸一化,達到“側抑制”的效果。可去搜索AlexNet或GoogLenet,里面就用到了這個功能
層類型:LRN
參數:全部為可選,沒有必須
local_size: 默認為5。如果是跨通道LRN,則表示求和的通道數;如果是在通道內LRN,則表示求和的正方形區域長度。
alpha: 默認為1,歸一化公式中的參數。
beta: 默認為5,歸一化公式中的參數。
norm_region: 默認為ACROSS_CHANNELS。有兩個選擇,ACROSS_CHANNELS表示在相鄰的通道間求和歸一化。WITHIN_CHANNEL表示在一個通道內部特定的區域內進行求和歸一化。與前面的local_size參數對應。
歸一化公式:對于每一個輸入, 去除以
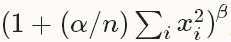
得到歸一化后的輸出
示例:
layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}如果對matlab比較熟悉的話,就應該知道im2col是什么意思。它先將一個大矩陣,重疊地劃分為多個子矩陣,對每個子矩陣序列化成向量,最后得到另外一個矩陣。
看一看圖就知道了:
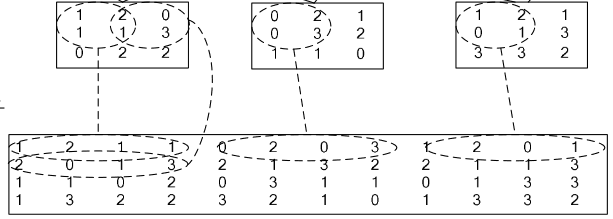
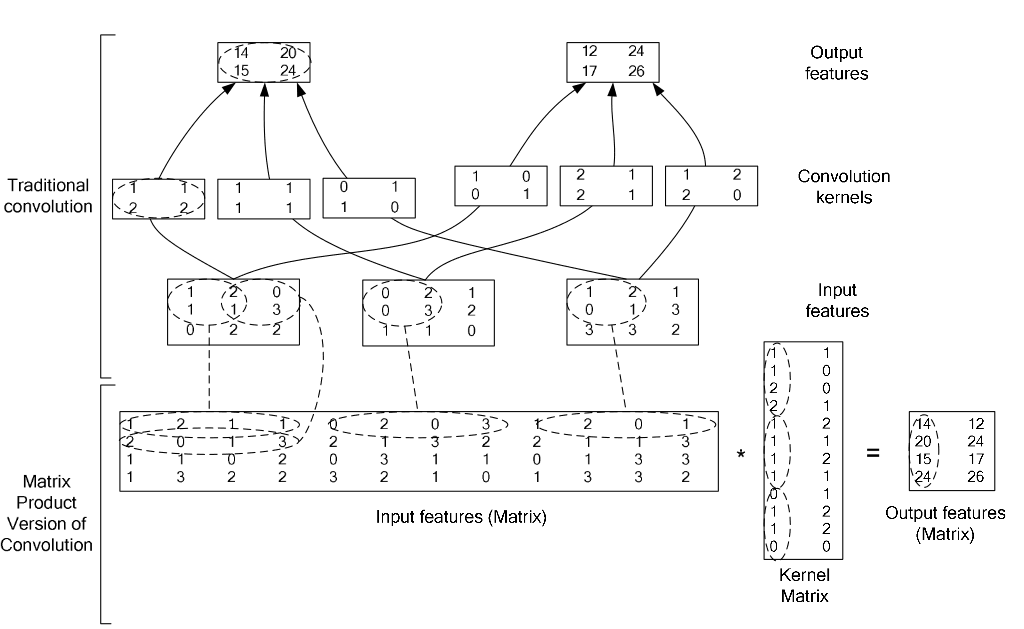
在caffe中,卷積運算就是先對數據進行im2col操作,再進行內積運算(inner product)。這樣做,比原始的卷積操作速度更快。
看看兩種卷積操作的異同:
以上就是關于“Caffe卷積神經網絡視覺層Vision Layers及參數實例分析”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





