溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“怎么利用python實現Simhash算法”,內容詳細,步驟清晰,細節處理妥當,希望這篇“怎么利用python實現Simhash算法”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
傳統相似度算法:文本相似度的計算,一般使用向量空間模型(VSM),先對文本分詞,提取特征,根據特征建立文本向量,把文本之間相似度的計算轉化為特征向量距離的計算,如歐式距離、余弦夾角等。
缺點:大數據情況下復雜度會很高。
Simhash應用場景:計算大規模文本相似度,實現海量文本信息去重。
Simhash算法原理:通過hash值比較相似度,通過兩個字符串計算出的hash值,進行異或操作,然后得到相差的個數,數字越大則差異越大。
詞頻(TF):一個詞語在整篇文章中出現的次數與詞語總個數之比;
逆向詞頻(IDF):一個詞語,在所有文章中出現的頻率都非常高,這個詞語不具有代表性,就可以降低其作用,也就是賦予其較小的權值。
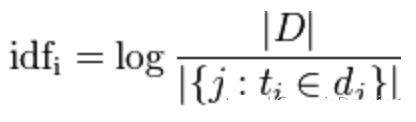
分子代表文章總數,分母表示該詞語在這些文章出現的篇數。一般會采取分母加一的方法,防止分母為0的情況出現,在這個比值之后取對數,就是IDF了。
最終用tf*idf得到一個詞語的權重,進而計算一篇文章的關鍵詞。然后根據每篇文章對比其關鍵詞的方法來對文章進行去重。simhash算法對效率和性能進行平衡,既可以很少的對比(關鍵詞不能取太多),又能有好的代表性(關鍵詞不能過少)。
Simhash是一種局部敏感hash。即假定A、B具有一定的相似性,在hash之后,仍然能保持這種相似性,就稱之為局部敏感hash。
得到一篇文章關鍵詞集合,通過hash的方法把關鍵詞集合hash成一串二進制,直接對比二進制數,其相似性就是兩篇文檔的相似性,在查看相似性時采用海明距離,即在對比二進制的時候,看其有多少位不同,就稱海明距離為多少。
將文章simhash得到一串64位的二進制,根據經驗一般取海明距離為3作為閾值,即在64位二進制中,只要有三位以內不同,就可以認為兩個文檔是相似的,這里的閾值也可以根據自己的需求來設置。也就是把一個文檔hash之后得到一串二進制數的算法,稱這個hash為simhash。
simhash具體實現步驟如下:
1. 將文檔分詞,取一個文章的TF-IDF權重最高的前20個詞(feature)和權重(weight)。即一篇文檔得到一個長度為20的(feature:weight)的集合。
2. 對其中的詞(feature),進行普通的哈希之后得到一個64為的二進制,得到長度為20的(hash : weight)的集合。
3. 根據(2)中得到一串二進制數(hash)中相應位置是1是0,對相應位置取正值weight和負值weight。例如一個詞進過(2)得到(010111:5)進過步驟(3)之后可以得到列表[-5,5,-5,5,5,5]。由此可以得到20個長度為64的列表[weight,-weight...weight]代表一個文檔。
4. 對(3)中20個列表進行列向累加得到一個列表。如[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]進行列向累加得到[-7,1,-9,9,3,9],這樣,我們對一個文檔得到,一個長度為64的列表。
5. 對(4)中得到的列表中每個值進行判斷,當為負值的時候去0,正值取1。例如,[-7,1,-9,9,3,9]得到010111,這樣就得到一個文檔的simhash值了。
6. 計算相似性。兩個simhash取異或,看其中1的個數是否超過3。超過3則判定為不相似,小于等于3則判定為相似。
Simhash整體流程圖如下:
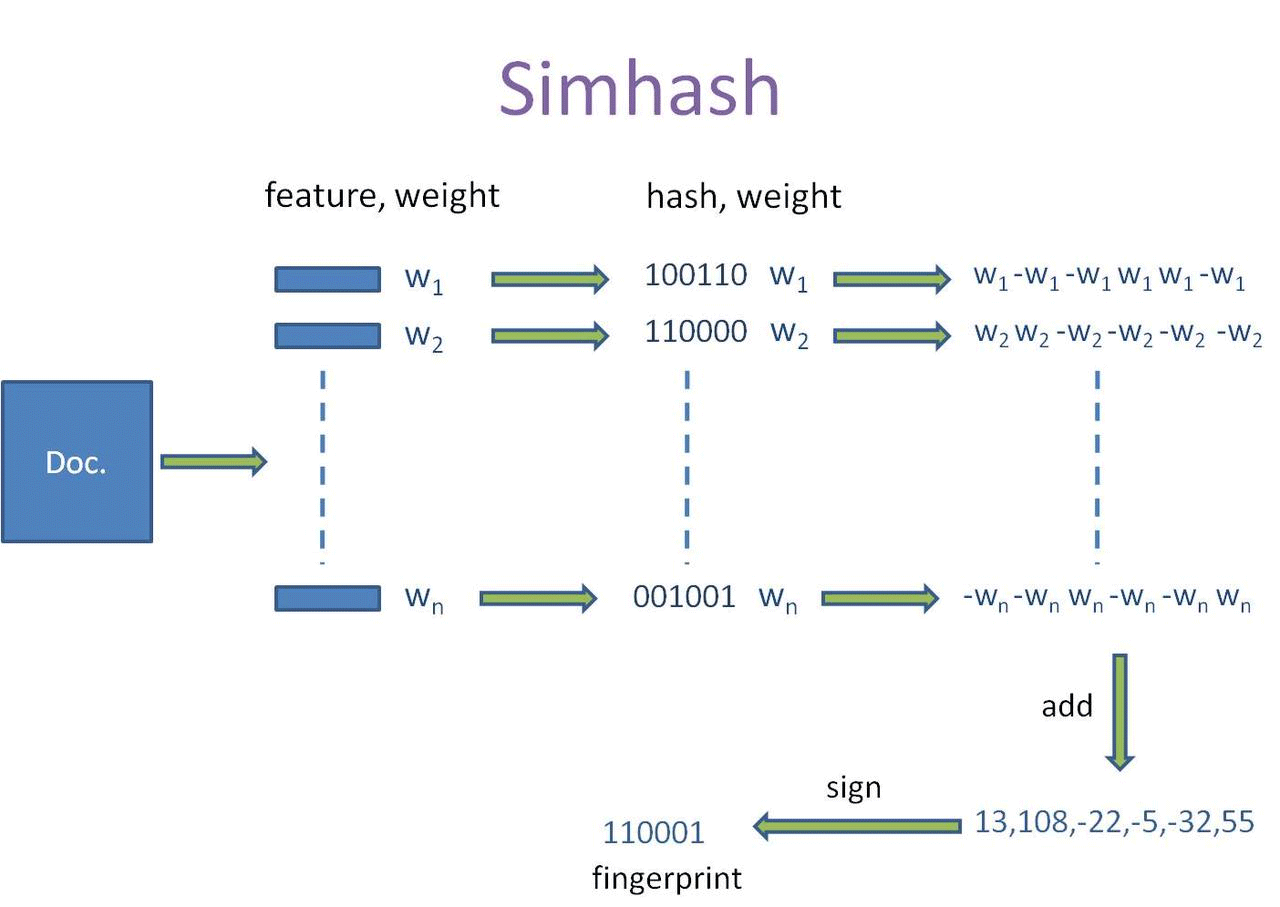
完全無關的文本正好對應成了相同的simhash,精確度并不是很高,而且simhash更適用于較長的文本,但是在大規模語料進行去重時,simhash的計算速度優勢還是很不錯的。
# !/usr/bin/python # coding=utf-8 class Simhash: def __init__(self, tokens='', hashbits=128): self.hashbits = hashbits self.hash = self.simhash(tokens) def __str__(self): return str(self.hash) # 生成simhash值 def simhash(self, tokens): v = [0] * self.hashbits for t in [self._string_hash(x) for x in tokens]: # t為token的普通hash值 for i in range(self.hashbits): bitmask = 1 << i if t & bitmask: v[i] += 1 # 查看當前bit位是否為1,是的話將該位+1 else: v[i] -= 1 # 否則的話,該位-1 fingerprint = 0 for i in range(self.hashbits): if v[i] >= 0: fingerprint += 1 << i return fingerprint # 整個文檔的fingerprint為最終各個位>=0的和 # 求海明距離 def hamming_distance(self, other): x = (self.hash ^ other.hash) & ((1 << self.hashbits) - 1) tot = 0 while x: tot += 1 x &= x - 1 return tot # 求相似度 def similarity(self, other): a = float(self.hash) b = float(other.hash) if a > b: return b / a else: return a / b # 針對source生成hash值 def _string_hash(self, source): if source == "": return 0 else: x = ord(source[0]) << 7 m = 1000003 mask = 2 ** self.hashbits - 1 for c in source: x = ((x * m) ^ ord(c)) & mask x ^= len(source) if x == -1: x = -2 return x
測試:
if __name__ == '__main__': s = 'This is a test string for testing' hash2 = Simhash(s.split()) s = 'This is a string testing 11' hash3 = Simhash(s.split()) print(hash2.hamming_distance(hash3), " ", hash2.similarity(hash3))
讀到這里,這篇“怎么利用python實現Simhash算法”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





