溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Mysql優化問題有哪些的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Mysql優化問題有哪些文章都會有所收獲,下面我們一起來看看吧。

對于大部分程序員來說,在開發過程中排查SQL基本是空白。但隨著行業的內卷,對一開發過程越來越重視和專業,其中一項就是開發過程中盡可能解決掉SQL問題,避免生產才暴露SQL問題。那么在開發過程中如何方便的進行程序的SQL排查呢?
其思路還是使用Mysql的慢日志來實現:
首先在開發過程中也需要開啟數據庫Mysql的慢查詢
SET GLOBAL slow_query_log='on';
其次設置慢SQL的最小時間
注意:這里時間單位是s秒但是有6位小數因此可以表示到微妙的時間力度,一般單表SQL執行時間在20ms之內為宜,反之理解就是在開發過程中,如果你執行的sql語句超過了20ms則你需要去關注它。
SET GLOBAL long_query_time=0.02;
為方便操作可以把慢SQL記錄到表中而不是文件中
SET GLOBAL log_output='TABLE';
最后通過mysql.slow_log表就可以查詢到記錄的慢SQL

在勇哥給大家開發的軟件中,也提供了圖形化的界面來一鍵幫助大家快速實現上述功能。

生成SQL問題的排查就相對復雜一點點,但是整體的思路還是通過慢SQL來排查,具體思路如下:
首先開啟數據庫Mysql的慢查詢
SET GLOBAL slow_query_log='on';
其次設置慢SQL的最小時間
SET GLOBAL long_query_time=0.02;
一般生成時把慢SQL放到文件
SET GLOBAL log_output='FILE';
下載慢SQL日志文件到本地
最后關閉數據庫Mysql的慢查詢
著重注意:生產的慢SQL最好在使用時,才去開啟,用完后關閉,避免日志記錄影響到業務性能
SET GLOBAL slow_query_log='off';
SQL調優融合多方面的知識,總體來說常見從表結構、表索引、兩方面來優化。
舉個例子來理解:就一個性別字段,用tinyint(1)存儲占用1字節,用int(1)存儲占用4個字節,如果有100W條記錄,那么用int存儲的表就比tinyint存儲的表文件大小多2.8M左右,因此在讀取int類型存儲的表時文件大,讀速度相比讀tinyint的慢。這其實就是為什么說要合理使用字段類型長度的本質:就是減少存儲的文件大小,以提供讀性能。
當然有的朋友就可能說2.8M并不影響大局,因此可以忽略。對于此想法勇哥要補充一嘴:一個表假設有10個字段,你的系統一共有30個表,那么再看一下多出的文件大小是多少?(2.8Mx10x30=840M,840M你用迅雷超級下載也要花好幾秒,這個時間在計算機里面算是很慢了...)
2.1、冗余設計背景——臨時表
Mysql內部存在一種特殊且輕量級的臨時表,它是被Mysql自動創建和刪除的。主要在SQL的執行過程中使用臨時表來存儲某些操作的中間結果,該過程由 MySQL 自動完成,用戶無法手工干預,且這種內部表對用戶來說是不可見的。
內部臨時表在 SQL 語句的優化過程中非常重要,MySQL 中的很多操作都要依賴于內部臨時表來進行優化操作。但是使用內部臨時表需要創建表以及中間數據的存取代價,所以在寫 SQL 語句的時候應該盡量去避免使用臨時表。
那么場景的那些場景Mysql內部會使用臨時表呢?
多表關聯查詢(JOIN)中,order by 或group by使用的列不是第一個表的列
group by 的列不是索引列時
distinct和group by 聯合使用
order by 語句中使用了distinct關鍵字
group by 的列時索引列,但數據量過大時
2.2、如何查看是否使用內部臨時表?
通過Explain關鍵字或者工具的功能按鈕,查看SQL的執行過程,在結果中的Extra列中如果出現Using temporary關鍵字,則說明你的SQL語句在執行時使用了臨時表。
如下圖,角色Role表和角色組Role_Group是多對1的關系,在關聯查詢的時候,排序使用role_group的id排序則會使用臨時表(見下圖1),如果排序使用role的id則不會使用臨時表(見圖2)。
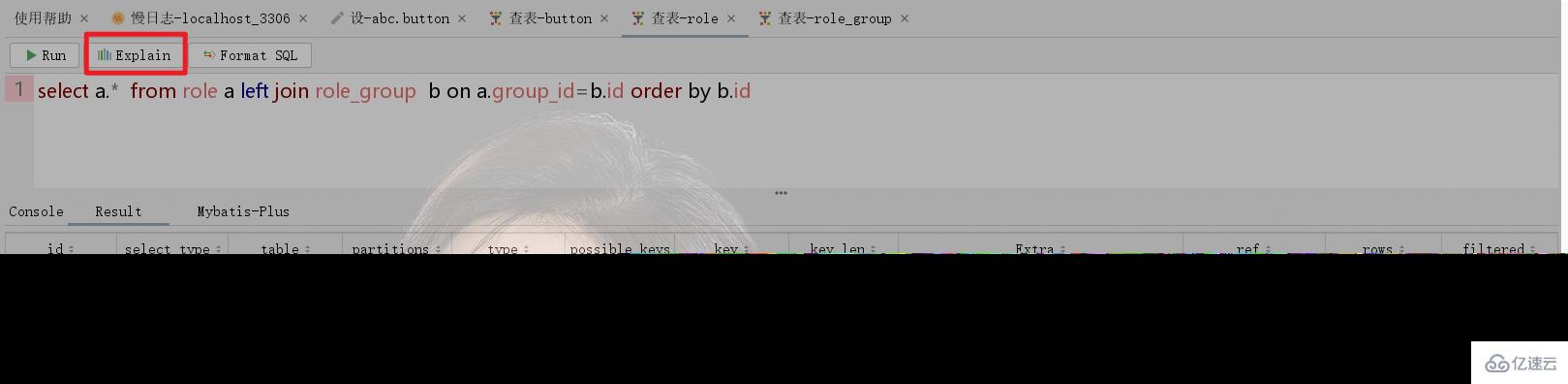
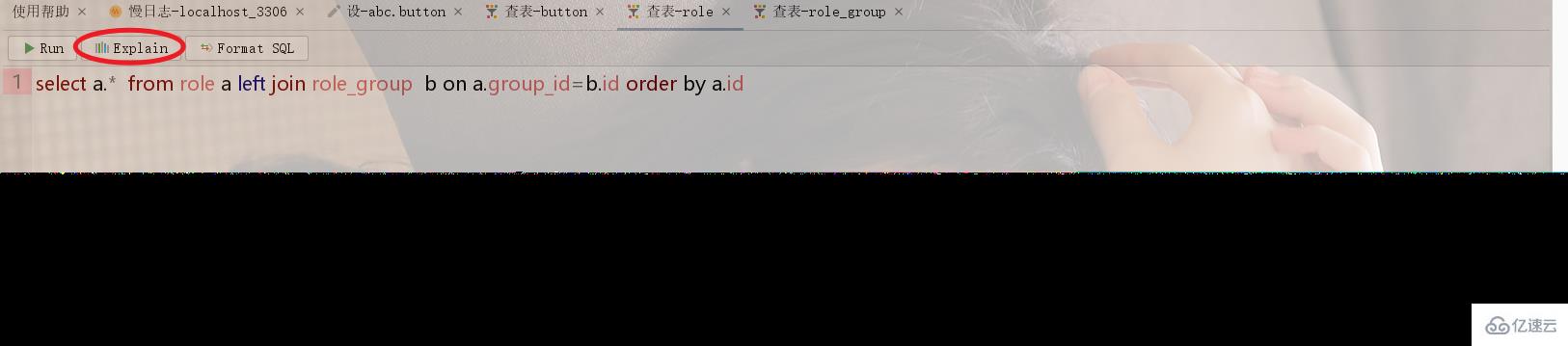
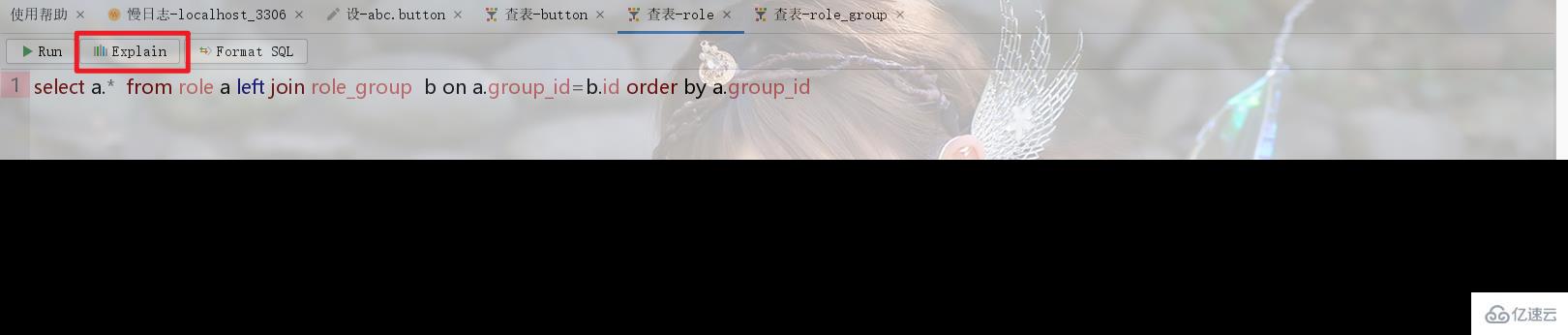
2.3、如何解決不使用內部臨時表?
這個問題解決有兩個方案,一是調整SQL語句避免使用臨時表,另外一個方案就是在表中冗余存儲。比如2.2中的圖一例子如果一定要按照role_group的id排序,則可以按照role表中的group_id排序,而這列正是冗余存儲的role_group表中id列值。
分庫分表不僅用于大數量情況下的優化,其中垂直分表還可以使用到SQL調優下。(這里我就不去解釋垂直和水平分表了,感興趣的私信我)
例如:一個文章表一般設計不會包括文章內容這個大字段。
文章內容這個大字段是單獨放置到一張表中

為什么文章表要采用以上設計而不把字段合并到一表中呢?
我們先來計算一道數學題,假設一篇文章總共1M大小,其中文章內容,824KB,其余字段200KB,這樣的文章一共有100W條,則:
方案一,如果用一個表存儲,則這個表大小是100W*1M=100WM
方案二,如果用垂直分表存儲,則基本表時200KBx100W,內容表824KBx100W
我們在前端有文章列表和文章詳情兩個頁面,分別要直接從數據庫中查詢相關內容,則:
方案一,文章列表和文章詳情的查詢都會從100WM數據中查詢
方案二,文章列表會從200KBx100W中查詢,文章詳情會從824KBx100W中查詢(當前也可能還需要從200KBx100W中查詢)
說到這里,相信大家心中應該有一個清晰的答案了吧!垂直拆表可以讓不同業務場景的查詢的數據量不同,常常這個數據量往往小于總表數據量,這就比從固定很大小的量中查詢更靈活和高效率。
大多數人對應索引的理解層次都在“索引可以加快查詢的速度”,然而這句話勇哥要補充下半句“索引可以加快查詢的速度,也可以減慢數據插入或修改的速度”。
如果一個表有5個索引,那么可以簡單的把一個索引當成一個表,則這就會有1張表+6張索引表=相當于有6張表,那么這6張表在什么時候會操作呢?我們來計算一下:
insert操作,數據插入后,需要去對5張索引表插入索引數據
delete操作,數據刪除后,需要去把5張索引表中的索引刪除
update操作
如果修改了索引列的數據,則先修改數據,還需要修改索引表中的索引
如果沒有修改索引列的數據,則只修改數據表
select操作
如果命中查詢索引,則先查詢索引,再查數據表
如果沒命中查詢索引,則直接查數據表
通過以上的計算,你會神奇的發現,索引個數越多,對于insert、delete、update操作是有影響的,而且是負影響。所以對于索引竟可能評估其帶來的影響小于查詢的收益,才去添加,而不是盲目的添加。
復合索引指的是包括有多個列的索引,它能有效的減少表的索引個數,平衡了多個字段需要多個索引直接的性能平衡,但是再使用復合索引的時候,需要注意索引列個數和順序的問題。
先說列個數的問題,指的是一個復合索引中包括的列字段太多影響性能的問題,主要是對update操作的性能影響,如下紅字:
如果修改了索引列的數據,則先修改數據,還需要修改索引表中的索引,如果索引列個數越多則修改該索引的概率越大
如果沒有修改索引列的數據,則只修改數據表
再說復合索引中列順序的問題,是指索引的最左匹配原則,即最左優先,在檢索數據時從聯合索引的最左邊開始匹配,這個比較容易理解,就不多做闡述。
索引無法存儲null值,當使用is null或is not nulli時會全表掃描
like查詢以"%"開頭
對于復合索引,查詢條件中沒有給出索引中第一列的值時
mysql內部評估全表掃描比索引快時
or、!=、<>、in、not in等查詢也可能引起索引失效
表達是與否概念的字段,必須使用 is_xxx 的方式命名,數據類型為 unsigned tinyint。 說明:任何字段如果為非負數,則必須是 unsigned。
字段允許適當冗余,以提高查詢性能,但必須考慮數據一致。e.g. 商品類目名稱使用頻率高,字段長度短,名稱基本一成不變,可在相關聯的表中冗余存儲類目名稱,
避免關聯查詢
。冗余字段遵循:
不是頻繁修改的字段;
不是 varchar 超長字段,更不能是 text 字段。
在 varchar 字段上建立索引時,必須指定索引長度,沒必要對全字段建立索引,根據實際文本區分度決定索引長度即可。
頁面搜索嚴禁左模糊或者全模糊,如果需要請通過搜索引擎來解決。 說明:索引文件具有 B-Tree 的最左前綴匹配特性,如果左邊的值未確定,那么無法使用此索引。
如果有 order by 的場景,請注意利用索引的有序性。order by 最后的字段是組合索引的一部分,并且放在索引組合順序的最后,避免出現 file_sort 的情況,影響查詢性能。
正例:where a=? and b=? order by c; 索引: a_b_c。
反例:索引中有范圍查找,那么索引有序性無法利用,如 WHERE a>10 ORDER BY b; 索引 a_b 無法排序。
利用延遲關聯或者子查詢優化超多分頁場景。 說明:MySQL 并不是跳過 offset 行,而是取 offset+N 行,然后返回放棄前 offset 的行,返回 N 行。當 offset 特別大的時候,效率會非常的低下,要么控制返回的總頁數,要么對超過閾值的頁數進行 SQL 改寫。
建組合索引的時候,區分度最高的在最左邊。
SQL 性能優化的目標,至少要達到 range 級別,要求是 ref 級別,最好是 consts。
不要使用 count(列名) 或 count(常量) 來替代 count(),count() 是 SQL92 定義的標準統計行數的語句,跟數據庫無關,跟 NULL 和非 NULL 無關。 說明:count(*) 會統計值為 NULL 的行,而 count(列名) 不會統計此列為 NULL 值的行。
count(distinct column) 計算該列除 NULL 外的不重復行數。注意,count(distinct column1,column2) 如果其中一列全為 NULL,那么即使另一列用不同的值,也返回為 0。
當某一列的值全為 NULL 時,count(column) 的返回結果為 0,但 sum(column) 的返回結果為 NULL,因此使用 sum() 時需注意 NPE 問題。 可以使用如下方式來避免 sum 的 NPE 問題。
SELECT IF(ISNULL(SUM(g), 0, SUM(g))) FROM table;
使用 ISNULL() 來判斷是否為 NULL 值。 說明:NULL 與任何值的直接比較都為 NULL。
不得使用外鍵與級聯,一切外鍵概念必須在應用層解決。 說明:以學生和成績的關系為例,學生表的 student_id 是主鍵,成績表的 student_id 則為外鍵。如果更新學生表中的 student_id,同時觸發成績表中的 student_id 更新,即為級聯更新。外鍵與級聯更新適用于單機低并發,不適合分布式、高并發集群;級聯更新是強阻塞,存在數據庫更新風暴的風險;外鍵影響數據庫的插入速度。
禁止使用存儲過程。存儲過程難以調試和擴展,更沒有移植性。
in 操作能避免則避免。若實在避免不了,需要仔細評估 in 后面的集合元素數量,控制在 1000 個之內。
POJO 類的布爾屬性不能加 is,而數據庫字段必須加 is_,要求在 resultMap 中進行字段與屬性的映射。
sql.xml 配置參數使用:#{}, #param#,不要使用 ${},此種方式容易出現 SQL 注入。
@Transactional 事務不要濫用。事務會影響數據庫的 QPS。另外,使用事務的地方需要考慮各方面的回滾方案,包括緩存回滾、搜索引擎回滾、消息補償、統計修正等。
關于“Mysql優化問題有哪些”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Mysql優化問題有哪些”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





