溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下如何利用python實現簡單的情感分析的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
# 數據導入
import pandas as pd
data = pd.read_csv('../data/京東評論數據.csv')
data.head()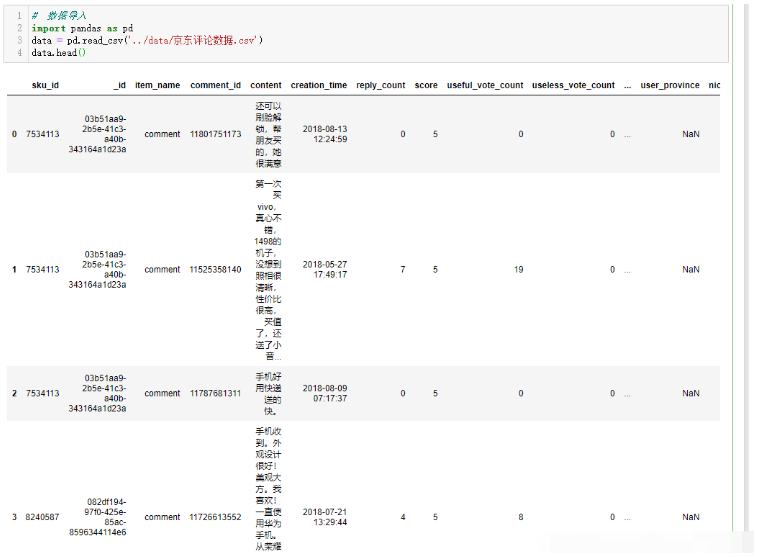
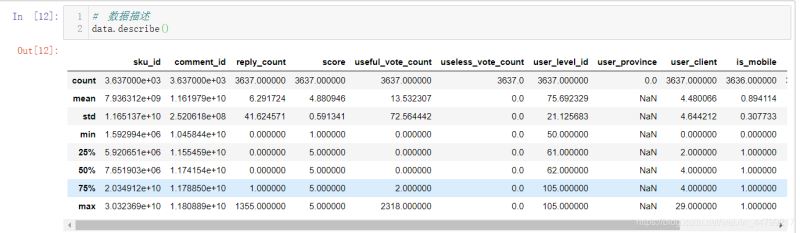
# 數據描述 data.describe()
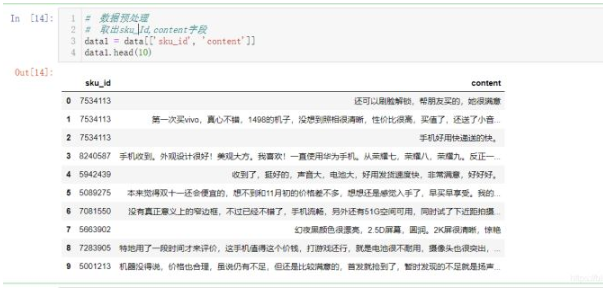
# 數據預處理 # 取出sku_Id,content字段 data1 = data[['sku_id', 'content']] data1.head(10)
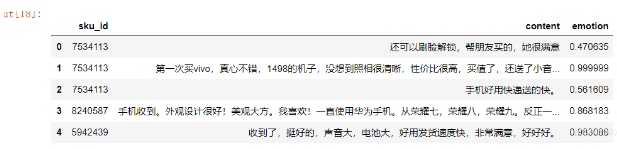
# 情感分析 from snownlp import SnowNLP data1['emotion'] = data1['content'].apply(lambda x: SnowNLP(x).sentiments) data1.head()
# 情感數據描述 data1.describe()
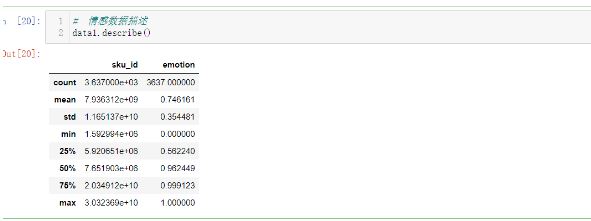
emotion平均值為0.74,中位數為0.96,25%分位數為0.56,可見不到25%的數據造成了整體均值的較大下移。
# 繪制情感分直方圖
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
bins = np.arange(0, 1.1, 0.1)
plt.hist(data1['emotion'], bins, color = '#4F94CD', alpha=0.9)
plt.xlim(0, 1)
plt.xlabel('情感分')
plt.ylabel('數量')
plt.title('情感分直方圖')
plt.show()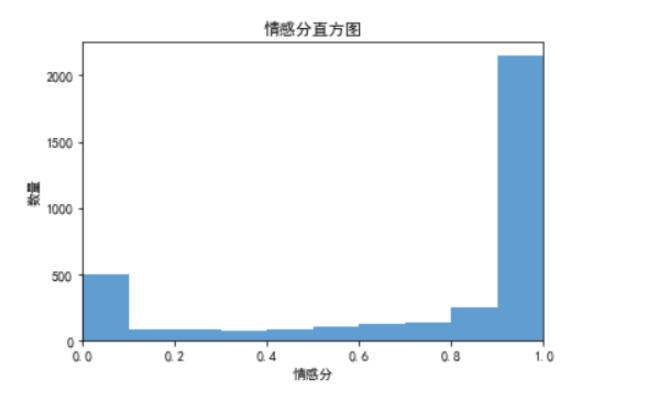
由直方圖可見,評論內容兩級分化較為嚴重;
3637條評論中有約2200條評論情感分在[0.9,1]區間內;同時,有約500條評論情感分在[0,0.1]區間內。
# 繪制詞云圖(這兒沒有做停用詞處理)
from wordcloud import WordCloud
import jieba
myfont = myfont = r'C:\Windows\Fonts\simhei.ttf'
w = WordCloud(font_path=myfont)
text = ''
for i in data['content']:
text += i
data_cut = ' '.join(jieba.lcut(text))
w.generate(data_cut)
image = w.to_file('詞云圖.png')
image
# 關鍵詞提取top10 # 這兒直接寫import jieba運行會顯示沒有analyse屬性 from jieba import analyse key_words = jieba.analyse.extract_tags(sentence=text, topK=10, withWeight=True, allowPOS=()) key_words
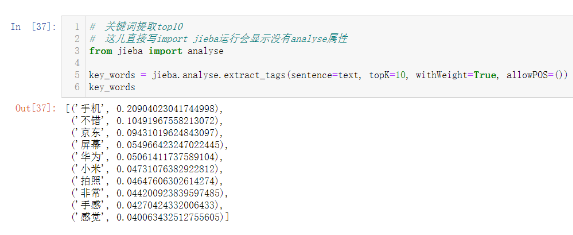
以上關鍵詞顯示,消費者比較在意手機的“屏幕”“拍照”“手感”等特性,“華為”“小米”是出現頻次最高的兩個手機品牌。
參數說明 :
sentence 需要提取的字符串,必須是str類型,不能是list
topK 提取前多少個關鍵字
withWeight 是否返回每個關鍵詞的權重
allowPOS是允許的提取的詞性,默認為allowPOS=‘ns’, ‘n’, ‘vn’, ‘v’,提取地名、名詞、動名詞、動詞
# 計算積極評論與消極評論各自的數目
pos, neg = 0, 0
for i in data1['emotion']:
if i >= 0.5:
pos += 1
else:
neg += 1
print('積極評論數目為:', pos, '\n消極評論數目為:', neg)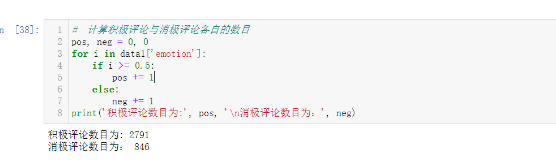
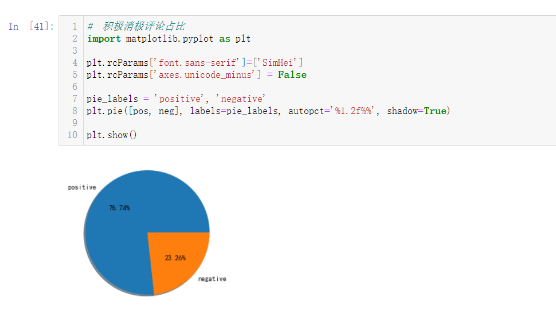
# 積極消極評論占比 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False pie_labels = 'positive', 'negative' plt.pie([pos, neg], labels=pie_labels, autopct='%1.2f%%', shadow=True) plt.show()
# 獲取消極評論的數據 data2 = data1[data1['emotion'] < 0.5] data2.head()
#消極評論詞云圖(這兒沒有做停用詞處理)
text2 = ''
for s in data2['content']:
text2 += s
data_cut2 = ' '.join(jieba.lcut(text2))
w.generate(data_cut2)
image = w.to_file('消極評論詞云.png')
image
#消極評論關鍵詞top10 key_words = jieba.analyse.extract_tags(sentence=text2, topK=10, withWeight=True, allowPOS=()) key_words
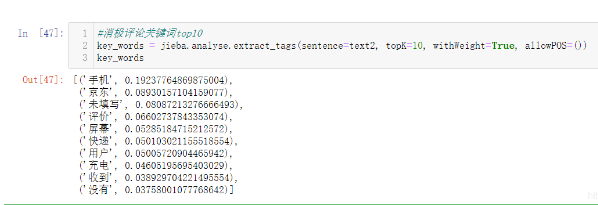
消極評論關鍵詞顯示,“屏幕”“快遞”“充電”是造成用戶體驗不佳的幾個重要因素;屏幕和充電問題有可能是手機不良品率過高或快遞壓迫;
因此平臺應注重提高手機品控,降低不良品率;另外應設法提升發貨,配送,派件的效率和質量。
以上就是“如何利用python實現簡單的情感分析”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





