溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python并行加速的技巧有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
我們在日常使用Python進行各種數據計算處理任務時,若想要獲得明顯的計算加速效果,最簡單明了的方式就是想辦法將默認運行在單個進程上的任務,擴展到使用多進程或多線程的方式執行。
而對于我們這些從事數據分析工作的人員而言,以最簡單的方式實現等價的加速運算的效果尤為重要,從而避免將時間過多花費在編寫程序上。
而今天我就來帶大家學習如何利用joblib這個非常簡單易用的庫中的相關功能,來快速實現并行計算加速效果。
作為一個被廣泛使用的第三方Python庫(譬如scikit-learn項框架中就大量使用joblib進行眾多機器學習算法的并行加速),我們可以使用pip install joblib對其進行安裝,安裝完成后,下面我們來學習一下joblib中有關并行運算的常用方法:
joblib中實現并行計算只需要使用到其Parallel和delayed方法即可,使用起來非常簡單方便
下面我們直接以一個小例子來演示:
joblib實現并行運算的思想是將一組通過循環產生的串行計算子任務,以多進程或多線程的方式進行調度,而我們針對自定義的運算任務需要做的僅僅是將它們封裝為函數的形式即可,譬如:
import time def task_demo1(): time.sleep(1) return time.time()
接著只需要像下面的形式一樣,為Parallel()設置相關參數后,銜接循環創建子任務的列表推導過程,其中利用delayed()包裹自定義任務函數,再銜接()傳遞任務函數所需的參數即可,其中n_jobs參數用于設置并行任務同時執行的worker數量,因此在這個例子中可以看到進度條是按照4個一組遞增的,
可以看到最終時間開銷也達到了并行加速效果:
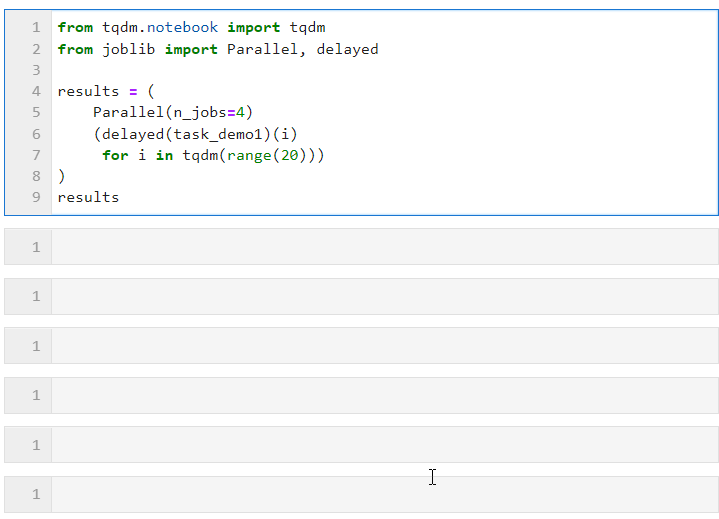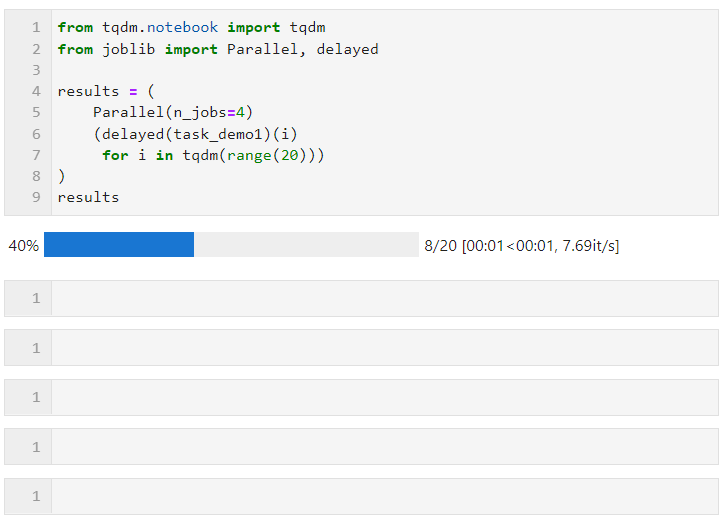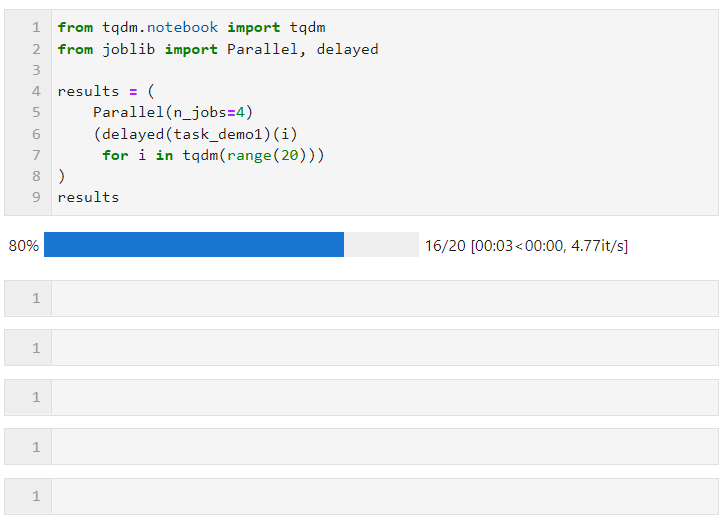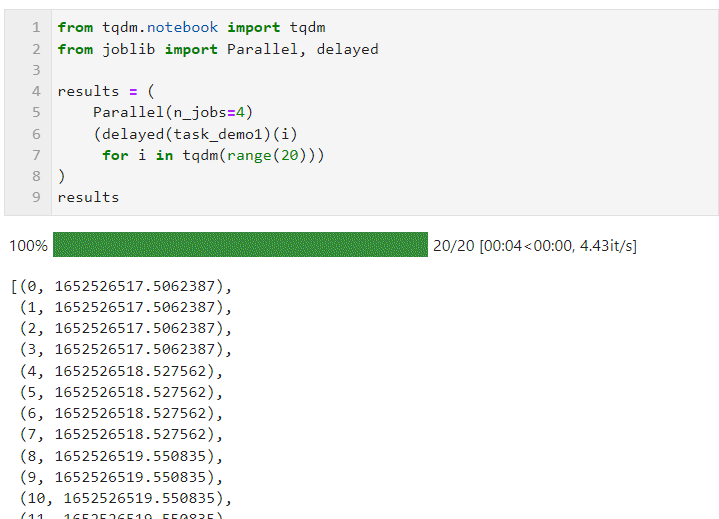
其中可以根據計算任務以及機器CPU核心數具體情況為Parallel()調節參數,核心參數有:
backend:用于設置并行方式,其中多進程方式有'loky'(更穩定)和'multiprocessing'兩種可選項,多線程有'threading'一種選項。默認為'loky'
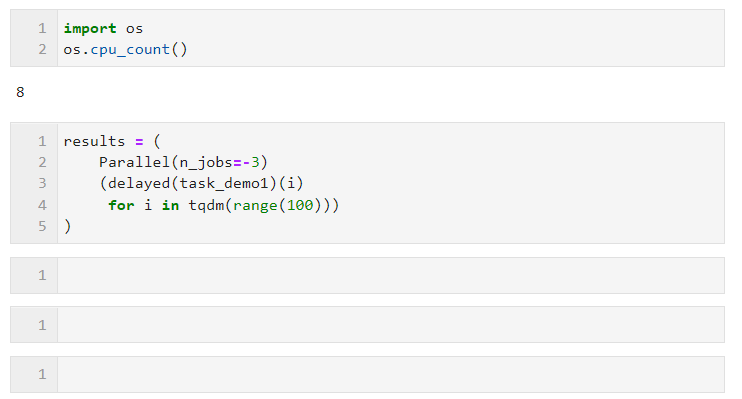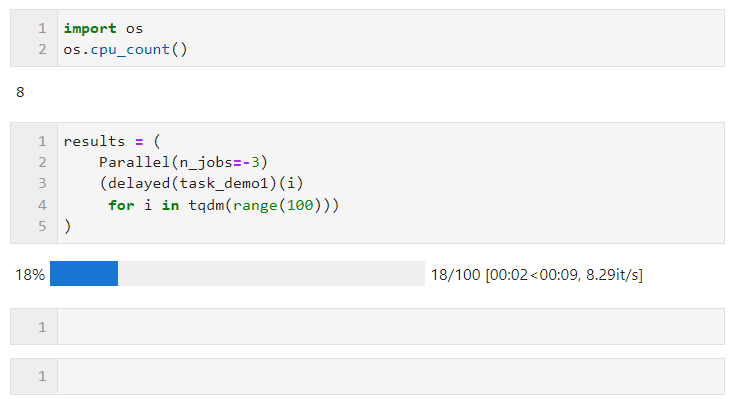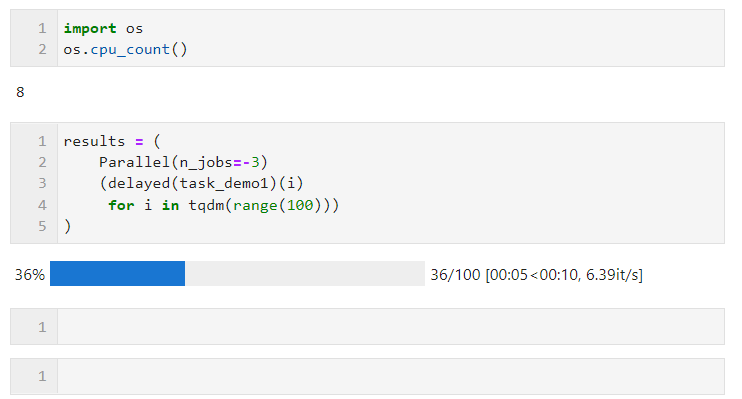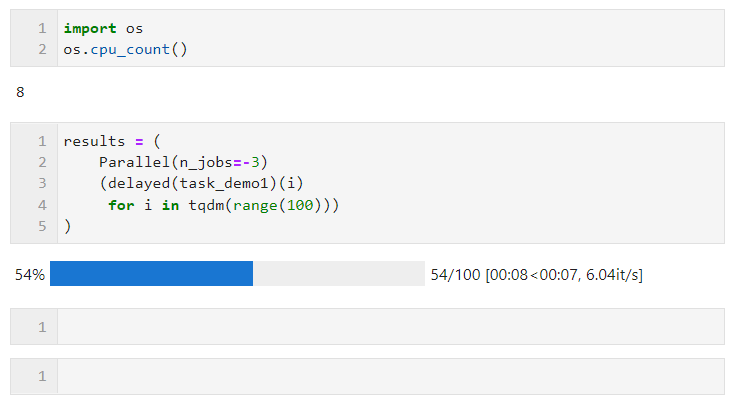
n_jobs:用于設置并行任務同時執行的worker數量,當并行方式為多進程時,n_jobs最多可設置為機器CPU邏輯核心數量,超出亦等價于開啟全部核心,你也可以設置為-1來快捷開啟全部邏輯核心,若你不希望全部CPU資源均被并行任務占用,則可以設置更小的負數來保留適當的空閑核心,譬如設置為-2則開啟全部核心-1個核心,設置為-3則開啟全部核心-2個核心
譬如下面的例子,在我這臺邏輯核心數為8的機器上,保留兩個核心進行并行計算:
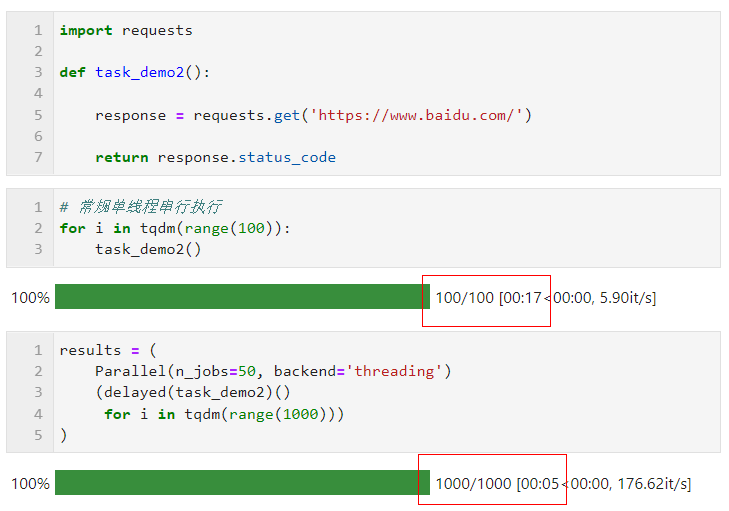
關于并行方式的選擇上,由于Python中多線程時全局解釋器鎖的限制,如果你的任務是計算密集型,則推薦使用默認的多進程方式加速,如果你的任務是IO密集型譬如文件讀寫、網絡請求等,則多線程是更好的方式且可以將n_jobs設置的很大,舉個簡單的例子,可以看到,通過多線程并行,我們在5秒的時間里完成了1000次請求,遠快于單線程17秒請求100次的成績
我們可以根據自己實際任務的不同,好好利用joblib來加速你的日常工作。
“Python并行加速的技巧有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





