溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Pytorch怎么搭建SRGAN平臺提升圖片超分辨率”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
SRGAN出自論文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network。
如果將SRGAN看作一個黑匣子,其主要的功能就是輸入一張低分辨率圖片,生成高分辨率圖片。

該文章提到,普通的超分辨率模型訓練網絡時只用到了均方差作為損失函數,雖然能夠獲得很高的峰值信噪比,但是恢復出來的圖像通常會丟失高頻細節。
SRGAN利用感知損失(perceptual loss)和對抗損失(adversarial loss)來提升恢復出的圖片的真實感。
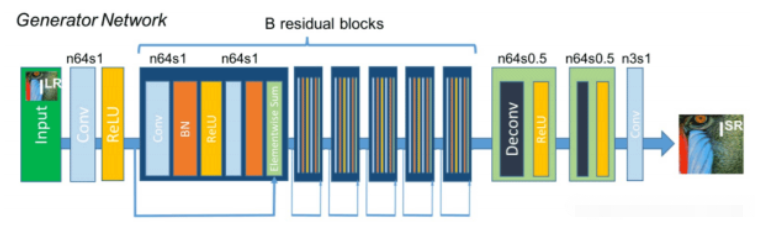
生成網絡的構成如上圖所示,生成網絡的作用是輸入一張低分辨率圖片,生成高分辨率圖片。:
SRGAN的生成網絡由三個部分組成。
1、低分辨率圖像進入后會經過一個卷積+RELU函數。
2、然后經過B個殘差網絡結構,每個殘差結構都包含兩個卷積+標準化+RELU,還有一個殘差邊。
3、然后進入上采樣部分,在經過兩次上采樣后,原圖的高寬變為原來的4倍,實現分辨率的提升。
前兩個部分用于特征提取,第三部分用于提高分辨率。
import math import torch from torch import nn class ResidualBlock(nn.Module): def __init__(self, channels): super(ResidualBlock, self).__init__() self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn1 = nn.BatchNorm2d(channels) self.prelu = nn.PReLU(channels) self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn2 = nn.BatchNorm2d(channels) def forward(self, x): short_cut = x x = self.conv1(x) x = self.bn1(x) x = self.prelu(x) x = self.conv2(x) x = self.bn2(x) return x + short_cut class UpsampleBLock(nn.Module): def __init__(self, in_channels, up_scale): super(UpsampleBLock, self).__init__() self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1) self.pixel_shuffle = nn.PixelShuffle(up_scale) self.prelu = nn.PReLU(in_channels) def forward(self, x): x = self.conv(x) x = self.pixel_shuffle(x) x = self.prelu(x) return x class Generator(nn.Module): def __init__(self, scale_factor, num_residual=16): upsample_block_num = int(math.log(scale_factor, 2)) super(Generator, self).__init__() self.block_in = nn.Sequential( nn.Conv2d(3, 64, kernel_size=9, padding=4), nn.PReLU(64) ) self.blocks = [] for _ in range(num_residual): self.blocks.append(ResidualBlock(64)) self.blocks = nn.Sequential(*self.blocks) self.block_out = nn.Sequential( nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64) ) self.upsample = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)] self.upsample.append(nn.Conv2d(64, 3, kernel_size=9, padding=4)) self.upsample = nn.Sequential(*self.upsample) def forward(self, x): x = self.block_in(x) short_cut = x x = self.blocks(x) x = self.block_out(x) upsample = self.upsample(x + short_cut) return torch.tanh(upsample)
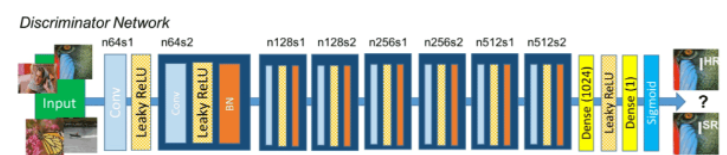
判別網絡的構成如上圖所示:
SRGAN的判別網絡由不斷重復的 卷積+LeakyRELU和標準化 組成。
對于判斷網絡來講,它的目的是判斷輸入圖片的真假,它的輸入是圖片,輸出是判斷結果。
判斷結果處于0-1之間,利用接近1代表判斷為真圖片,接近0代表判斷為假圖片。
判斷網絡的構建和普通卷積網絡差距不大,都是不斷的卷積對圖片進行下采用,在多次卷積后,最終接一次全連接判斷結果。
實現代碼如下:
class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.net = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.LeakyReLU(0.2), nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(64), nn.LeakyReLU(0.2), nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2), nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2), nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.LeakyReLU(0.2), nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(256), nn.LeakyReLU(0.2), nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.BatchNorm2d(512), nn.LeakyReLU(0.2), nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(512), nn.LeakyReLU(0.2), nn.AdaptiveAvgPool2d(1), nn.Conv2d(512, 1024, kernel_size=1), nn.LeakyReLU(0.2), nn.Conv2d(1024, 1, kernel_size=1) ) def forward(self, x): batch_size = x.size(0) return torch.sigmoid(self.net(x).view(batch_size))
SRGAN的訓練可以分為生成器訓練和判別器訓練:
每一個step中一般先訓練判別器,然后訓練生成器。
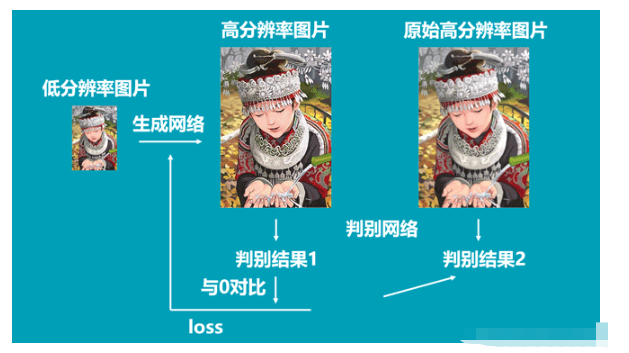
在訓練判別器的時候我們希望判別器可以判斷輸入圖片的真偽,因此我們的輸入就是真圖片、假圖片和它們對應的標簽。
因此判別器的訓練步驟如下:
1、隨機選取batch_size個真實高分辨率圖片。
2、利用resize后的低分辨率圖片,傳入到Generator中生成batch_size個虛假高分辨率圖片。
3、真實圖片的label為1,虛假圖片的label為0,將真實圖片和虛假圖片當作訓練集傳入到Discriminator中進行訓練。
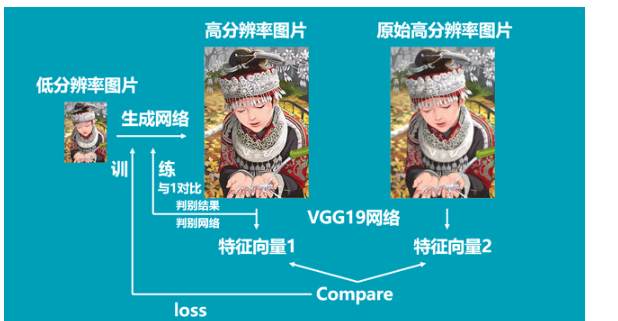
在訓練生成器的時候我們希望生成器可以生成極為真實的假圖片。因此我們在訓練生成器需要知道判別器認為什么圖片是真圖片。
因此生成器的訓練步驟如下:
1、將低分辨率圖像傳入生成模型,得到虛假高分辨率圖像,將虛假高分辨率圖像獲得判別結果與1進行對比得到loss。(與1對比的意思是,讓生成器根據判別器判別的結果進行訓練)。
2、將真實高分辨率圖像和虛假高分辨率圖像傳入VGG網絡,獲得兩個圖像的特征,通過這兩個圖像的特征進行比較獲得loss
SRGAN的庫整體結構如下:
在訓練前需要準備好數據集,數據集保存在datasets文件夾里面。
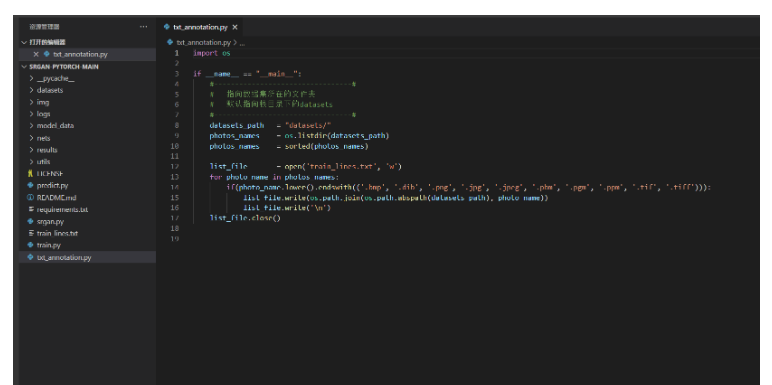
打開txt_annotation.py,默認指向根目錄下的datasets。運行txt_annotation.py。
此時生成根目錄下面的train_lines.txt。
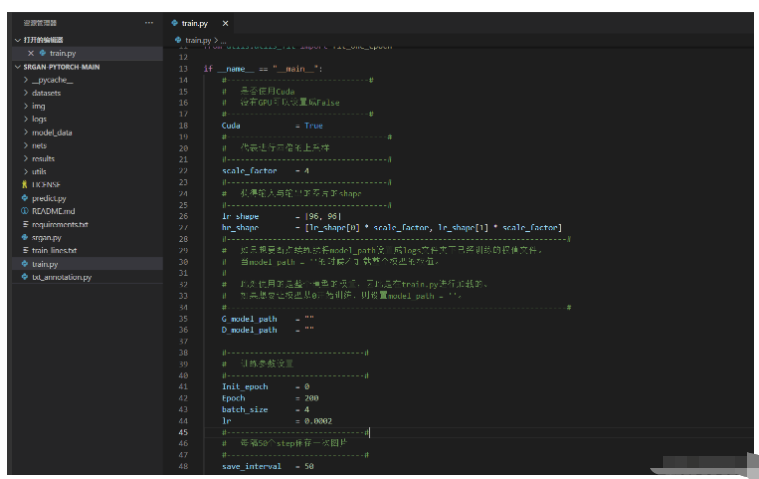
在完成數據集處理后,運行train.py即可開始訓練。
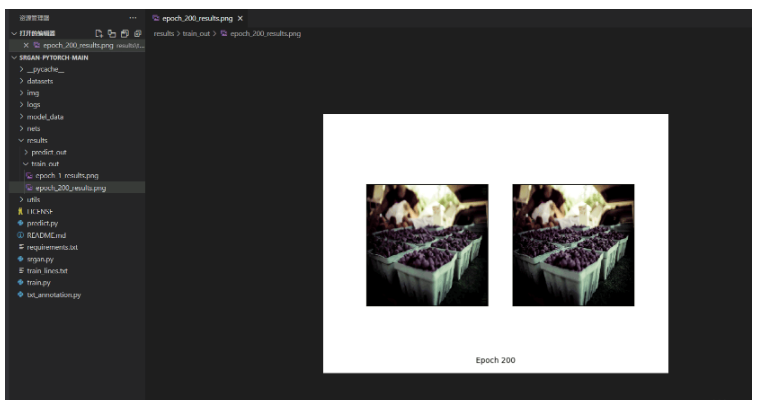
訓練過程中,可在results文件夾內查看訓練效果:
“Pytorch怎么搭建SRGAN平臺提升圖片超分辨率”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





