溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Pandas中常用的七個時間戳處理函數是什么”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Pandas中常用的七個時間戳處理函數是什么”文章能幫助大家解決問題。
在零售、經濟和金融等行業,數據總是由于貨幣和銷售而不斷變化,生成的所有數據都高度依賴于時間。如果這些數據沒有時間戳或標記,實際上很難管理所有收集的數據。Python 程序允許我們使用 NumPy timedelta64 和 datetime64 來操作和檢索時間序列數據。sklern庫中也提供時間序列功能,但 Pandas 為我們提供了更多且好用的函數。
Pandas 庫中有四個與時間相關的概念
日期時間:日期時間表示特定日期和時間及其各自的時區。它在 pandas 中的數據類型是 datetime64[ns] 或 datetime64[ns, tz]。
時間增量:時間增量表示時間差異,它們可以是不同的單位。示例:“天、小時、減號”等。換句話說,它們是日期時間的子類。
時間跨度:時間跨度被稱為固定周期內的相關頻率。時間跨度的數據類型是 period[freq]。
日期偏移:日期偏移有助于從當前日期計算選定日期,日期偏移量在 pandas 中沒有特定的數據類型。
時間序列分析至關重要,因為它們可以幫助我們了解隨著時間的推移影響趨勢或系統模式的因素。在數據可視化的幫助下,分析并做出后續決策。
現在讓我們看幾個使用這些函數的例子
import pandas as pd day = pd.Timestamp(‘2021/1/5') day.day_name()
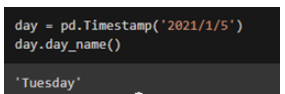
上面的程序是顯示特定日期的名稱。第一步是導入 panda 的并使用 Timestamp 和 day_name 函數。“Timestamp”功能用于輸入日期,“day_name”功能用于顯示指定日期的名稱。
import pandas as pd day = pd.Timestamp(‘2021/1/5') day1 = day + pd.Timedelta(“3 day”) day1.day_name() day2 = day1 + pd.offsets.BDay() day2.day_name()
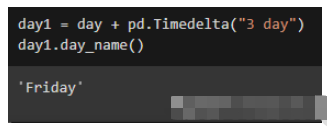
在第一個代碼中,顯示三天后日期名稱。“Timedelta”功能允許輸入任何天單位(天、小時、分鐘、秒)的時差。
在第二個代碼中,使用“offsets.BDay()”函數來顯示下一個工作日。換句話說,這意味著在星期五之后,下一個工作日是星期一。
獲取時區的信息
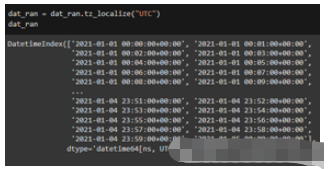
import pandas as pd import numpy as np from datetime import datetime dat_ran = dat_ran.tz_localize(“UTC”) dat_ran
轉換為美國時區
dat_ran.tz_convert(“US/Pacific”)
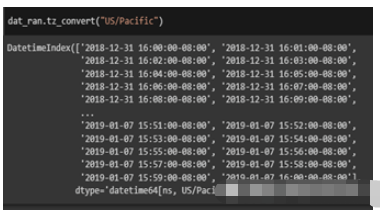
代碼的目標是更改日期的時區。首先需要找到當前時區。這是“tz_localize()”函數完成的。我們現在知道當前時區是“UTC”。使用“tz_convert()”函數,轉換為美國/太平洋時區。
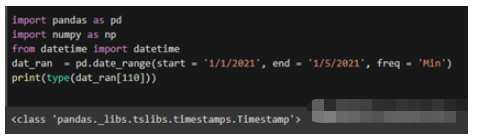
import pandas as pd import numpy as np from datetime import datetime dat_ran = pd.date_range(start = ‘1/1/2021', end = ‘1/5/2021', freq = ‘Min') print(type(dat_ran[110]))
import pandas as pd import numpy as np from datetime import datetime dat_ran = pd.date_range(start = ‘1/1/2021', end = ‘1/5/2021', freq = ‘Min') print(dat_ran)
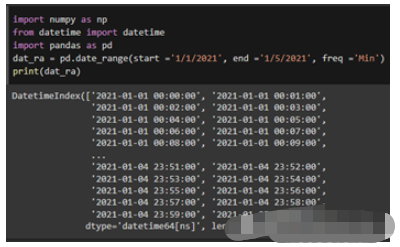
上面的代碼生成了一個日期系列的范圍。使用“date_range”函數,輸入開始和結束日期,可以獲得該范圍內的日期。
import pandas as pd from datetime import datetime import numpy as np dat_ran = pd.date_range(start ='1/1/2019', end ='1/08/2019',freq ='Min') df = pd.DataFrame(dat_ran, columns =[‘date']) df[‘data'] = np.random.randint(0, 100, size =(len(dat_ran))) print(df.head(5))
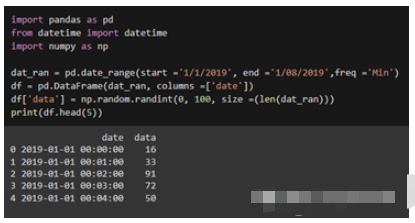
在上面的代碼中,使用“DataFrame”函數將字符串類型轉換為dataframe。最后“np.random.randint()”函數是隨機生成一些假定的數據。
import pandas as pd from datetime import datetime import numpy as np dat_ran = pd.date_range(start ='1/1/2019', end ='1/08/2019', freq ='Min') df = pd.DataFrame(dat_ran, columns =[‘date']) df[‘data'] = np.random.randint(0, 100, size =(len(dat_ran))) string_data = [str(x) for x in dat_ran] print(string_data[1:5])
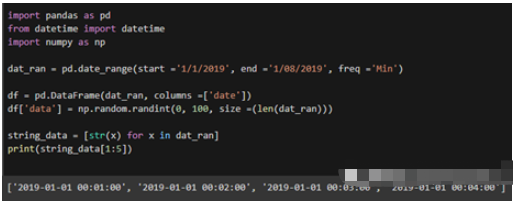
上面代碼是是第6條的的延續。在創建dataframe并將其映射到隨機數后,對列表進行切片。
關于“Pandas中常用的七個時間戳處理函數是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





