溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python怎么使用MapReduce編程模型統計銷量的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Python怎么使用MapReduce編程模型統計銷量文章都會有所收獲,下面我們一起來看看吧。
MapReduce是一種編程模型,用于大規模數據集(大于1TB)的并行運算。概念"Map(映射)"和"Reduce(歸約)",是它們的主要思想,都是從函數式編程語言里借來的,還有從矢量編程語言里借來的特性。它極大地方便了編程人員在不會分布式并行編程的情況下,將自己的程序運行在分布式系統上。 當前的軟件實現是指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組。
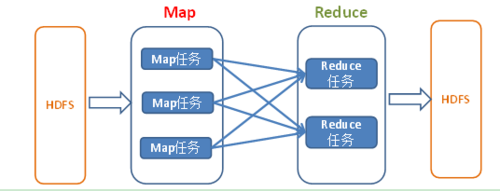
下面就通過手動實現MapReduce編碼統計銷售數量的例子來模擬。
#!/usr/bin/python # -*- coding: utf-8 -*- import random # 模擬商品 stocks = ["HUAWEI Mate40","Apple iphone13","Apple MacBook Pro 14","ThinkBook 14p","RedmiBook Pro14","飛鶴星飛帆幼兒奶粉","愛他美 幼兒奶粉","李寧運動男衛褲","小米踏步機橢圓機","歐萊雅面膜","御泥坊面膜","歐萊雅男士套裝","金六福白酒","牛欄山42度","茅臺飛天"] # 銷售訂單 sales_list = list() # 生成100個買家訂單,每個訂單三個商品 for i in range(100): sstocks = list() for j in range(3): sstocks.append(stocks[random.randint(0,14)]) a = "買家" + str(i+1) + ":" + ",".join(sstocks) print(a)
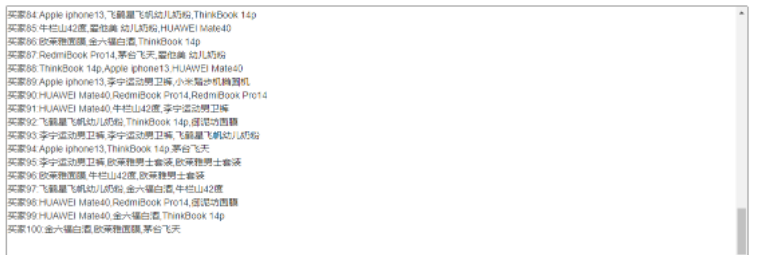
將第一步的結果作為第二步的輸入。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
#從控制臺中讀取數據,循環發送每行數據
for line in sys.stdin:
#對訂單進行拆分
orders = line.strip().split(":")
if len(orders) == 2:
#對訂單中的商品進行拆分
stocks = orders[1].split(",")
for stock in stocks:
#將每一個商品作為key,value進行輸出
print('%s,%s' % (stock,1))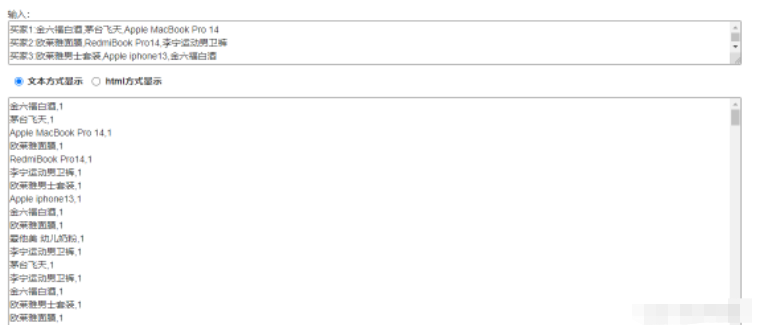
將第二步的結果作為第三步的輸入。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
# 創建一個空的字典用來每一個商品的銷售數據
stock_dict = dict()
for line in sys.stdin:
if len(line.strip()) >= 1:
# 拆分每一行的商品,銷量
stock, sales = line.split(',')
# 判斷當前商品是否在字典中有存放
if stock in stock_dict:
# 如果有,把字典中的商品和銷量取出來,追加當前銷量再放入
stock_dict[stock] = stock_dict[stock] + int(sales)
else:
# 如果沒有,直接把商品和銷量數據放入字典中
stock_dict[stock] = int(sales)
# 遍歷字典列表,獲取每一個商品的銷量
for stock, sales in stock_dict.items():
print('%s\t%s' % (stock, sales))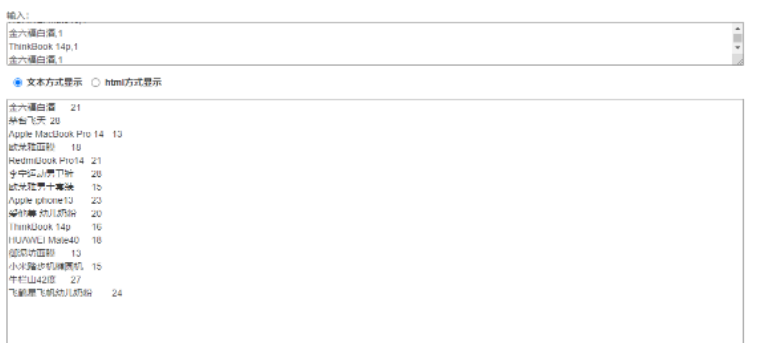
關于“Python怎么使用MapReduce編程模型統計銷量”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Python怎么使用MapReduce編程模型統計銷量”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





