溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python怎么取讀csv文件做dbscan分析”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
讀取csv文件中相應的列,然后進行轉化,處理為本算法需要的格式,然后進行dbscan運算,目前公開的代碼也比較多,本文根據公開代碼修改,
具體代碼如下:
from sklearn import datasets
import numpy as np
import random
import matplotlib.pyplot as plt
import time
import copy
import pandas as pd
# from sklearn.datasets import load_iris
def find_neighbor(j, x, eps):
N = list()
for i in range(x.shape[0]):
temp = np.sqrt(np.sum(np.square(x[j] - x[i]))) # 計算歐式距離
if temp <= eps:
N.append(i)
return set(N)
def DBSCAN(X, eps, min_Pts):
k = -1
neighbor_list = [] # 用來保存每個數據的鄰域
omega_list = [] # 核心對象集合
gama = set([x for x in range(len(X))]) # 初始時將所有點標記為未訪問
cluster = [-1 for _ in range(len(X))] # 聚類
for i in range(len(X)):
neighbor_list.append(find_neighbor(i, X, eps))
if len(neighbor_list[-1]) >= min_Pts:
omega_list.append(i) # 將樣本加入核心對象集合
omega_list = set(omega_list) # 轉化為集合便于操作
while len(omega_list) > 0:
gama_old = copy.deepcopy(gama)
j = random.choice(list(omega_list)) # 隨機選取一個核心對象
k = k + 1
Q = list()
Q.append(j)
gama.remove(j)
while len(Q) > 0:
q = Q[0]
Q.remove(q)
if len(neighbor_list[q]) >= min_Pts:
delta = neighbor_list[q] & gama
deltalist = list(delta)
for i in range(len(delta)):
Q.append(deltalist[i])
gama = gama - delta
Ck = gama_old - gama
Cklist = list(Ck)
for i in range(len(Ck)):
cluster[Cklist[i]] = k
omega_list = omega_list - Ck
return cluster
# X = load_iris().data
data = pd.read_csv("testdata.csv")
x,y=data['Time (sec)'],data['Height (m HAE)']
print(type(x))
n=len(x)
x=np.array(x)
x=x.reshape(n,1)
y=np.array(y)
y=y.reshape(n,1)
X = np.hstack((x, y))
cluster_std=[[.1]], random_state=9)
eps = 0.08
min_Pts = 5
begin = time.time()
C = DBSCAN(X, eps, min_Pts)
end = time.time()
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=C)
plt.show()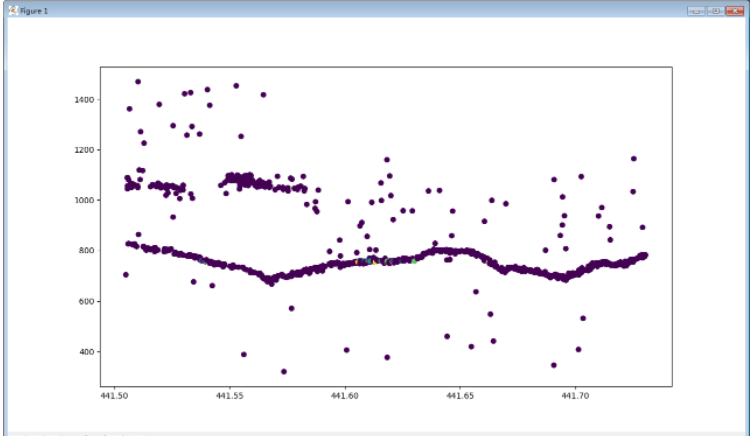
修改參數顯示:
eps = 0.8 min_Pts = 5
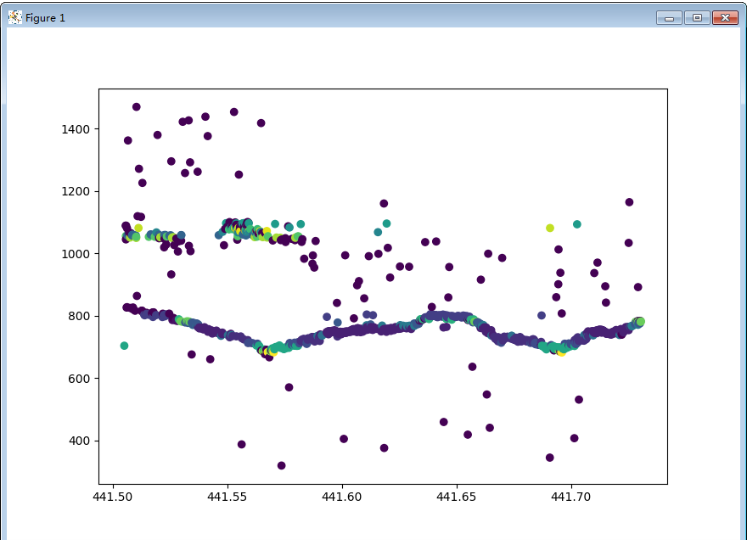
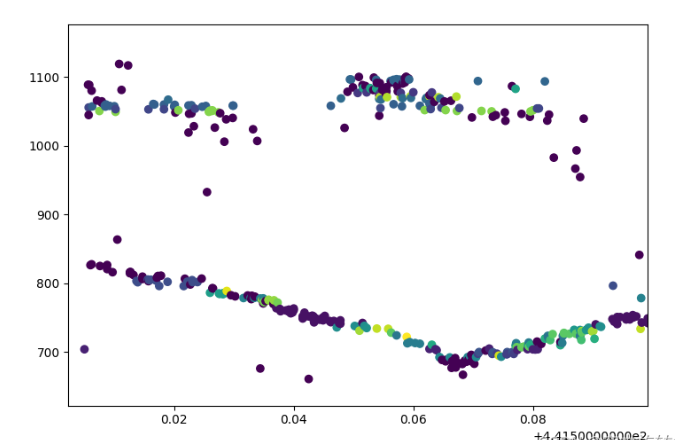
采用少量數據計算的時候效率問題不明顯,隨著數據量增大,計算效率問題就變得尤為明顯,難以滿足大量數據的計算需求了,后期將想辦法優化計算方法或者收集C++代碼進行優化了。
“Python怎么取讀csv文件做dbscan分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





