溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Nebula Graph怎么解決風控業務”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Nebula Graph怎么解決風控業務”文章吧。
有別于傳統銀行的信貸業務十天、半個月的申請審核時長,互聯網金融借貸第一個特點便是申請審核非常快,可能用戶上一秒剛在手機端提交授信申請,下一秒系統便會返回授信申請的結果。此外,互聯網金融借貸還有一個特點:數據信息的真實性難以保證,用戶填寫的信息:年收入、家庭關系、聯系人都會存在信息不實的情況。而這兩個互聯網金融的特點催生了一個產業,就是網絡黑產。通俗來說,網絡黑產就是用戶薅“借貸”羊毛的行為。因為網絡借貸隱匿性強,一旦黑產賬號實施了欺詐行為后,通過互聯網很難追蹤到特定的人。此外,由于借貸審批時效性的關系,黑產賬號能很方便地做到走量、薅到更多的錢。基于此,催生互聯網金融的風控需求,需要系統甄別欺詐場景。
那如何甄別網絡黑產呢?通過用戶與不同實體、設備、GPS 與手機號之間的關聯關系,以及社群發現查看社群中的個體是否有欺詐風險、進行反欺詐的個案調查,能很好地進行借貸風控。目前,眾安保險的風控是基于 Nebula Graph 實現的。

在眾安保險技術選型之初,團隊成員調研過圖數據庫市場的產品,首先篩選出了 JanusGraph、OrientDB。
先來說下 JanusGraph,在眾安金融事業技術團隊內部 JanusGraph 有一大優勢:團隊成員對它熟悉,不少工程師使用過 JanusGraph,這從某種程度上降低了圖數據庫開發、上手成本。使用過 JanusGraph 的研發都知道它是一個分布式圖數據庫,存儲、索引依賴開源組件,例如:HBase(存儲)、Elasticsearch(索引)。而之前公司的某個業務線曾使用過 JanusGraph,底層搭載線上 HBase 存儲服務,而該業務相對獨立和其他核心業務不存在強依賴關系。“不同的國家有不同的國情,一旦相同機制硬搬到不同的國家,可能會出現水土不服問題”,目前眾安保險風控業務的基礎數據存儲在 HBase 中,假如風控系統使用 JanusGraph 的話,將上百億圖數據完全導入 HBase 會對 HBase 集群產生影響、增加查詢毛刺,導致其他業務線受到影響。此外,在大規模寫入速度性能方面,JanusGraph 導入較慢。綜合上述原因,即便 JanusGraph 具有低上手成本,但其強依賴其他組件、導入性能差,所以 JanusGraph pass。
在圖數據庫產品調研過程中,我們發現 OrientDB 在 DB-Engine 排名較前、功能完善。經過性能測試,發現在小規模數據集下使用 OrientDB 體感良好,但一旦 Mock 數據過億,大規模數據集下使用 OrientDB 會遇到 Server 端頻繁報錯問題。查閱 OrientDB 官方文檔無果之后,眾安保險向 OrientDB 官方 GitHub 倉提交了 issue。但是 OrientDB 反饋響應慢,在提交 issue 的過程中,我們還發現大規模數據集 Server 端頻繁報錯問題社區用戶兩年前提交過,issue 仍未解決處于 open 狀態。此外,在大規模數據寫入性能方面,寫入點的速度尚可接受,但寫入邊的 QPS 只有 1-2k,用這個速度開始圖數據建模的話耗時將在天級別,這是不可接受的。綜上,雖然 OrientDB 排名靠前、功能完善,但大規模數據頻繁 Server 報錯、社區 issue 響應慢、大規模寫入速度不佳導致最后我們沒有選擇 OrientDB。
而 Nebula Graph 參與技術選型的契機是,在眾安保險開始圖數據庫選型時,咨詢其他公司(京東、攜程…)從業人員公司所用圖數據庫時,他們一致推薦 Nebula Graph。因此,Nebula Graph 成為眾安保險圖數據庫選型的選項之一。而在實際測試中,我們發現 Nebula Graph 大規模寫入速度非常快,生產環境測試數據能達到 10w+ QPS。此外,Nebula Graph 存儲和索引依賴于本地 RocksDB 庫,不依賴于其他大數據組件,符合業務需求。在大數據生態支持方面,Nebula Graph 支持主流的 Spark(nebula-spark-connector)和 Flink(nebula-flink-connector)。在社區響應和反饋時效上,Nebula Graph 也給了我們比較好的體驗。
這里額外講下社區支持,在整個圖數據庫調研過程中,我們發現相較于成熟的諸如 MySQL、Oracle 此類的 SQL 數據庫,圖數據庫發展時間較短,由此產生的問題是遇到部分圖數據庫產品問題,搜索引擎能提供的信息較少。像之前 OrientDB 的頻繁報錯問題,如果社區未能提供及時的技術反饋,對于使用者來說他可能要花費大量時間來閱讀源碼去 Debug,人力成本便會急劇上升、性價比極低。
而 Nebula Graph 在社區支持跟反饋方面給了眾安保險非常良好的體驗。作為他們的客戶,包括在最早期的 1.0,眾安保險給 Nebula Graph 提交了不少使用問題和 bug,Nebula 研發同學都能及時回復和 fix bug。到 2.0 部署時,我們遇到生產部署問題他們也能及時提供技術支持。這一點相比于其他的圖數據庫廠商,是非常值得推薦的。這也是我們選擇 Nebula Graph 作為圖數據庫來支撐眾安保險業務的根本性原因。
下圖為眾安保險基于 Nebula Graph 的風控系統架構圖,它集數據處理、加工清洗、計算、圖服務應用為一體。
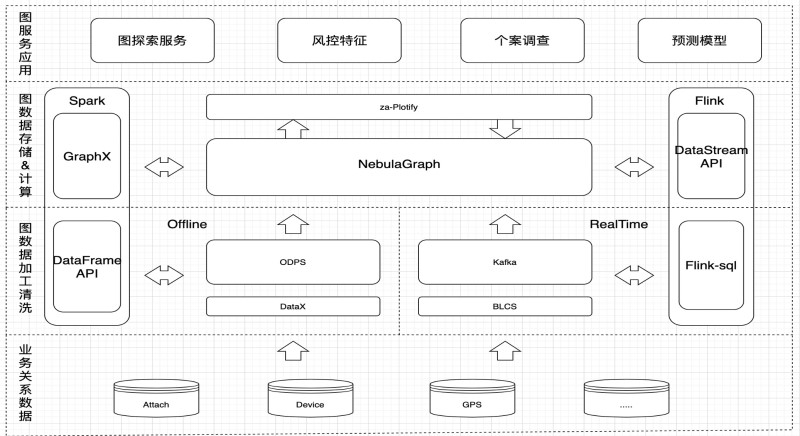
如上圖所示,最底層為業務庫,不同的業務關系數據存在不同的業務庫中,包括用戶附件、設備、 GPS、IP 等等信息。
再上層,是由離線數倉和實時數倉構成的圖數據庫加工清洗層,離線數倉通過 DataX 進行每天 T+1 的數據回流,回流業務庫的數據存到 ODPS 中,Nebula Graph 通過 Spark 來讀取當中數據并寫入到數據庫中。在實時數倉方面,通過眾安保險內部的監聽組件 BLCS 將數據寫到 Kafka,再經過 FlinkSQL 搭建的實時數倉進行數據清洗加工,最后通過 Flink 實時地寫入到 Nebula Graph 中。為了保證數據的一致性,實時數倉每天進行數據校驗,如果數據存在不一致,則會使用離線數據補齊缺失的數據。
數據清洗加工層上面則是存儲 & 計算層,存儲層不用說自然是 Nebula Graph。而計算方面,通過 Nebula Graph 提供的 Spark Connector 組件,將圖數據庫中的數據讀取到 Spark 平臺通過 GraphX 執行預測模型,最后將結果寫回 Nebula Graph 中。
最后,通過眾安保險的微服務系統將圖數據庫存儲 & 計算對接給上層圖應用,提供圖探索服務、風控特征、個案調查、預測模型等圖服務。
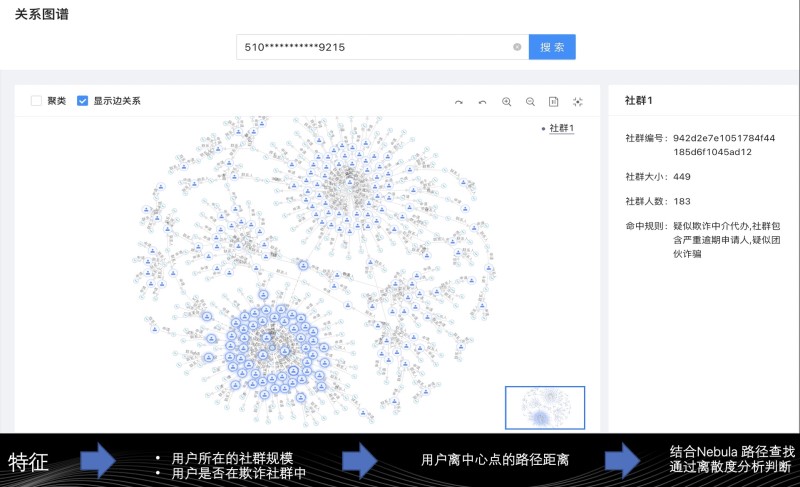
這里簡單講解眾安保險內部的圖社群探索的關系圖譜,通過上圖的關系圖譜講解具象化地介紹眾安是如何利用圖數據庫甄別欺詐場景,如何使用圖數據庫實踐風控特性。
上圖有 2 類節點:
人(藍色節點)
手機(綠色節點)
存在 3 類關系:
人-[申請]->手機
手機-[聯系人]->人
人-[綁卡]->手機
第一眼看到上面的圖,很明顯看到 2 個稠密熱點,熱點手機號被五、六十填為他的家庭聯系人的手機號。按常識來說,當代中國大多獨生子女家庭,加上旁系關系,也很難出現五、六十個人同時將同一個手機號填為他的家庭聯系人的手機號。所以,這個手機號關聯人可能是欺詐團伙分子,黑產團伙可能知曉借貸評分系統中有一環節是對家庭聯系人的手機號進行信用評分,團伙希望通過關聯高信用分的手機號從而提高信用分。
基于上述特征,我們可以查詢用戶所在社群的規模、用戶是否在疑似欺詐社群中對他進行一個初步風控判斷。這里講述下,即便某個用戶處于異常關系網絡中也不代表他是個欺詐用戶,處于異常社群是個判斷用戶是否為欺詐分子的充分不必要條件。因為存在一種可能,用戶本身并非是欺詐分子,但直系親戚參與了中介代辦、團伙欺詐,此時便會出現正常用戶和異常用戶都存在同一關系網絡的情況。
下一步,我們需要深入挖掘用戶和異常中心的“親密”離散度,探尋它們的路徑距離。通過結合 Nebula Graph 本身的路徑查找功能,分析離散度(靠近異常點,還是處于社群邊緣)從而判斷某位用戶是否是有欺詐嫌疑。
這里以手機號為例,來幫助大家理解眾安是如何通過 Nebula 來識別用戶的欺詐場景的。其實眾安保險內部還有設備、IP 等等關系圖譜,這里不展開贅述。

這部分來介紹下圖預測模型,
Connected Component(貸前)
Label Propagation(貸中)
Degree Statistical
剛上面部分介紹的關系圖譜是通過聯通分量(Connected Component)算法計算得出的,主要應用在貸前的用戶授信申請環節。
再來是標簽傳播(Label Propagation),不同于聯通分量,標簽傳播更多地應用于貸中環節。標簽傳播主要是通過一個確定的點 Y 去傳播、衍生出它相關點。舉個例子,貸中用戶名單中某個用戶是嚴重逾期人員,這個人員便是打上逾期標簽的確定點 Y,結合既定的風控規則查看點 Y 關聯延伸的點中哪些點出現相似逾期行為,從而判斷這些點是否屬于嚴重逾期的社群。這便是貸中的標簽傳播算法。
最后一個算法是 Degree Statistical,全圖關系度數,主要供風控人員使用。風控人員在做風控特征時,可能會提出幾十、上百個圖特征,基于這些特征數據需要用歷史的數據去驗證,查看哪些特征可以真正地識別出欺詐用戶或是嚴重逾期用戶。而這個驗證過程,如果使用傳統數倉通過 ODPS 做深度查詢的話,無論在執行效率、耗時,還是在 SQL 代碼編寫方面,都是一個非常低效的過程。但,通過 Nebula Graph 將點數據讀取到 GraphX 中進行全圖關系度計算,將 7 度或者是 10 度關系以行的形式寫回到 ODPS 中,提供給風控人員使用,可以幫助他們更快地完成風控規則制定、完成風控任務。
在主題分享時,眾安保險所用的 Nebula 版本為 2.0.1,后續 Nebula v2.5.0 中新增水位線 watermark 功能去防止查詢遇到稠密熱點占用內存過高拖垮 storage 進程的情況。眾安保險這邊會在測試環境部署 v2.5.0 版本進行驗證,驗證通過之后,業務線逐步切到 v2.5.0 版本中。
后續 Nebula 可能應用在數倉的表與字段的血緣依賴、調度平臺任務關系的管理中,眾安保險基礎平臺部的同學正在動手用 Nebula Graph 去替換已有的傳統實現方案。
以上就是關于“Nebula Graph怎么解決風控業務”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





