溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“java的Stream API終端操作示例分析”,在日常操作中,相信很多人在java的Stream API終端操作示例分析問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”java的Stream API終端操作示例分析”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
在本號之前寫過的文章中,曾經給大家介紹過 Java Stream管道流是用于簡化集合類元素處理的java API。在使用的過程中分為三個階段。在開始本文之前,我覺得仍然需要給一些新朋友介紹一下這三個階段,如圖:
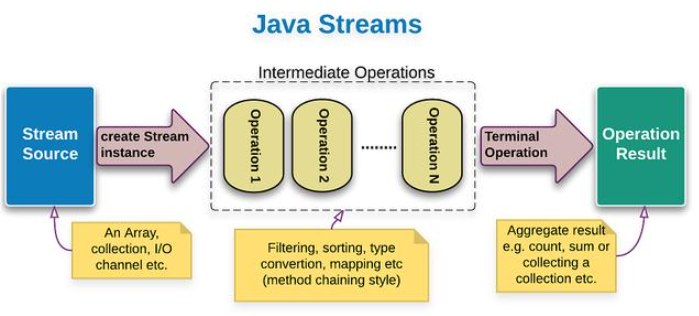
第一階段(圖中藍色):將集合、數組、或行文本文件轉換為java Stream管道流
第二階段(圖中虛線部分):管道流式數據處理操作,處理管道中的每一個元素。上一個管道中的輸出元素作為下一個管道的輸入元素。
第三階段(圖中綠色):管道流結果處理操作,也就是本文的將介紹的核心內容。
在開始學習之前,仍然有必要回顧一下我們之前給大家講過的一個例子:
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);首先使用stream()方法將字符串List轉換為管道流Stream
然后進行管道數據處理操作,先用fliter函數過濾所有大寫L開頭的字符串,然后將管道中的字符串轉換為大寫字母toUpperCase,然后調用sorted方法排序。這些API的用法在本號之前的文章有介紹過。其中還使用到了lambda表達式和函數引用。
最后使用collect函數進行結果處理,將java Stream管道流轉換為List。最終list的輸出結果是:[LEMUR, LION]
如果你不使用java Stream管道流的話,想一想你需要多少行代碼完成上面的功能呢?回到正題,這篇文章就是要給大家介紹第三階段:對管道流處理結果都可以做哪些操作呢?下面開始吧!
如果我們只是希望將Stream管道流的處理結果打印出來,而不是進行類型轉換,我們就可以使用forEach()方法或forEachOrdered()方法。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEachOrdered(System.out::println);parallel()函數表示對管道中的元素進行并行處理,而不是串行處理,這樣處理速度更快。但是這樣就有可能導致管道流中后面的元素先處理,前面的元素后處理,也就是元素的順序無法保證
forEachOrdered從名字上看就可以理解,雖然在數據處理順序上可能無法保障,但是forEachOrdered方法可以在元素輸出的順序上保證與元素進入管道流的順序一致。也就是下面的樣子(forEach方法則無法保證這個順序):
Monkey
Lion
Giraffe
Lemur
Lion
java Stream 最常見的用法就是:一將集合類轉換成管道流,二對管道流數據處理,三將管道流處理結果在轉換成集合類。那么collect()方法就為我們提供了這樣的功能:將管道流處理結果在轉換成集合類。
通過Collectors.toSet()方法收集Stream的處理結果,將所有元素收集到Set集合中。
Set<String> collectToSet = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .collect(Collectors.toSet()); //最終collectToSet 中的元素是:[Monkey, Lion, Giraffe, Lemur],注意Set會去重。
同樣,可以將元素收集到List使用toList()收集器中。
List<String> collectToList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toList()); // 最終collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
上面為大家介紹的元素收集方式,都是專用的。比如使用Collectors.toSet()收集為Set類型集合;使用Collectors.toList()收集為List類型集合。那么,有沒有一種比較通用的數據元素收集方式,將數據收集為任意的Collection接口子類型。 所以,這里就像大家介紹一種通用的元素收集方式,你可以將數據元素收集到任意的Collection類型:即向所需Collection類型提供構造函數的方式。
LinkedList<String> collectToCollection = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toCollection(LinkedList::new)); //最終collectToCollection中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
注意:代碼中使用了LinkedList::new,實際是調用LinkedList的構造函數,將元素收集到Linked List。當然你還可以使用諸如LinkedHashSet::new和PriorityQueue::new將數據元素收集為其他的集合類型,這樣就比較通用了。
通過toArray(String[]::new)方法收集Stream的處理結果,將所有元素收集到字符串數組中。
String[] toArray = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .toArray(String[]::new); //最終toArray字符串數組中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
使用Collectors.toMap()方法將數據元素收集到Map里面,但是出現一個問題:那就是管道中的元素是作為key,還是作為value。我們用到了一個Function.identity()方法,該方法很簡單就是返回一個“ t -> t ”(輸入就是輸出的lambda表達式)。另外使用管道流處理函數distinct()來確保Map鍵值的唯一性。
Map<String, Integer> toMap = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.distinct()
.collect(Collectors.toMap(
Function.identity(), //元素輸入就是輸出,作為key
s -> (int) s.chars().distinct().count()// 輸入元素的不同的字母個數,作為value
));
// 最終toMap的結果是: {Monkey=6, Lion=4, Lemur=5, Giraffe=6}Collectors.groupingBy用來實現元素的分組收集,下面的代碼演示如何根據首字母將不同的數據元素收集到不同的List,并封裝為Map。
Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根據元素首字母分組,相同的在一組
// counting() // 加上這一行代碼可以實現分組統計
));
// 最終groupingByList內的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,結果是: {G=1, L=3, M=1}這是該過程的說明:groupingBy第一個參數作為分組條件,第二個參數是子收集器。
boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判斷管道中是否包含2,結果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素數據總計結果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素數據累加結果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素數據平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素數據最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的統計結果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}到此,關于“java的Stream API終端操作示例分析”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





