溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關計算機中內存屏障由來及實現思路的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
如果你不了解講內存屏障為什么要講CPU緩存,接著往后看。
學過《計算機組成原理》的同學應該都聽過一個詞:時鐘周期。什么是時鐘周期呢?通俗點來講就是CPU完成一個基本動作需要的時間周期。對硬件有點認識的同學都知道看CPU好不好一定要看的一個參數:多少多少GHZ。這個GHZ跟時鐘周期之間是存在一定的換算關系的,感興趣的同學可以去自行研究。說明一下:不了解這層換算關系不影響你看后面的內容,只要你對時鐘周期有一個基本認知就可以了。
在很早以前,CPU里面是沒有緩存這塊區域的,就是CPU直接讀寫內存。那后面為什么在CPU中增加了緩存呢?因為CPU的運行效率與讀寫內存的效率存在著巨大的鴻溝,在讀寫內存過程中帶來的等待浪費了很大的CPU算力。現在最新的內存是DDR4規格,但是向內存中寫入數據,據權威資料,需要107個CPU時鐘周期,即CPU的運行效率是寫內存的107倍。如果CPU只執行寫操作需要一個時鐘周期,那CPU等待這個寫完成需要等待106個時鐘周期,是不是很浪費CPU算力?那如何解決呢?就跟我們工作中發現MySQL出現讀寫瓶頸如何解決是一樣的思維:加緩存。
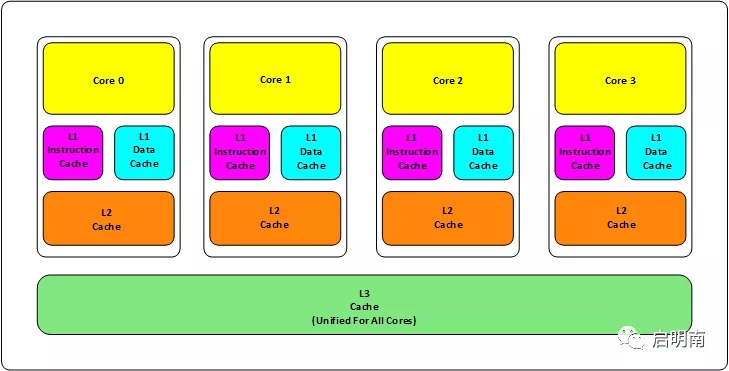
拿我們今天主流的CPU架構來說,現在的CPU主要采用三層緩存:
L1、L2緩存成為本地核心內緩存,即一個核一個。如果你的機器是4核,那就是有4個L1+4個L2
L3緩存是所有核共享的。即不管你的CPU是幾核,這個CPU中只有一個L3
L1緩存的大小是64K,即32K指令緩存+32K數據緩存。L2是256K,L3是2M。這不是絕對的,目前Intel CPU基本是這樣的設計
這里還補充一個知識點:緩存行(Cache-line)。緩存行是CPU緩存存儲數據的最小單位,大小為64B。這塊如果展開來講要講很久很久,本篇文章就不展開講了,有興趣的同學可以自行研究。如果你沒有學習過計算機硬件相關知識,可能看不懂。
根據哲學的矛盾相對論:任何問題的解決方案都是一個利與弊共存的矛盾體。加緩存的確有效提升了CPU的執行效率,但是CPU緩存間的數據一致性、CPU緩存與內存間的數據一致性就是不得不去思考與解決的問題了。而且還得保證解決這兩層數據一致性的效率要高于不加緩存前浪費的CPU算力,不然這個方案就是一套偽方案:聽起來高大上,不解決問題。
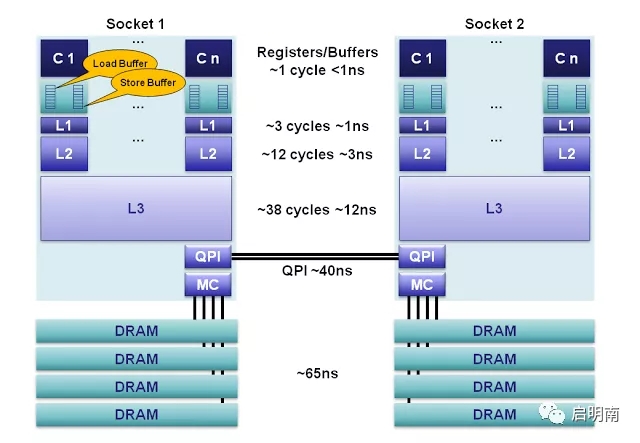
MESI協議就是為了保證CPU各核的緩存、內存間的數據一致性而生的,沒有了解過的可以百度普及一下,這個比較簡單。這里拓展兩點:
一、CPU運算單元與L1緩存間為什么要增加buffer?CPU實現各個核的緩存與內存間的數據一致性的思路有點像socket的三次握手:CPU0修改了某個數據,需要廣播告訴其他CPU,這時候CPU0進入阻塞狀態等待其他CPU修改其緩存中的狀態,待其他CPU都修改完狀態返回應答消息后才進入運行狀態。雖然這個阻塞的時間很短,但是在CPU的世界里就很長了,為了保證這部分阻塞時間也能得到充分利用,于是加入了buffer。將預讀信息存儲進去,這樣CPU解除阻塞后就可以直接從buffer拿出請求處理。
二、MESI協議的實現思路是:如果CPU0修改了某個數據,需要廣播給其他CPU,緩存中沒有這個數據的CPU丟棄這個廣播消息,緩存中有這個數據的CPU監聽到這個廣播后會將相應的緩存行改為invalid狀態,這樣CPU在下次讀取這個數據的時候發現緩存行失效,就去內存中讀取。這里面童鞋們有沒有發現一個問題:只要存在數據修改,CPU就需要去內存取數據,那為什么不實現CPU緩存能共享數據呢?這樣CPU在下次讀取的時候去CPU0的緩存行去讀取就可以啦,而且性能更高。現在的CPU也的確實現了這個思路,對應的協議就是:AMD的MOESI、Intel的MESIF。感興趣的童鞋自己去研究吧。
對于CPU的寫,目前主流策略有兩種:
1、write back:即CPU向內存寫數據時,先把真實數據放入store buffer中,待到某個合適的時間點,CPU才會將store buffer中的數據刷到內存中,而且這兩個操作是異步的。這在多線程環境中,有些情況下是可以接受的,但是有些情況是不可接受的,為了讓程序員有能力根據業務需要達到同步完成,就設計了內存屏障。關于內存屏障,后面會細講。
2、write through:即CPU向內存寫數據時,同步完成寫store buffer與內存。
當前CPU大多數采用的是write back策略。可能有童鞋要問了:為什么呢?因為大多數情況下,CPU異步完成寫內存產生的部分延遲是可以接受的,而且這個延遲極短。只有在多線程環境下需要嚴格保證內存可見等極少數特殊情況下才需要保證CPU的寫在外界看來是同步完成的,需要借助CPU提供的內存屏障實現。如果直接采用策略2:write through,那每次寫內存都需要等待數據刷入內存,極大影響了CPU的執行效率。
為什么要插入屏障?本質是業務層面不能接受寫store buffer與刷回內存這兩個異步操作產生的哪怕是極少的延遲,即對內存可見性的要求極高。
內存屏障到底是什么?內存屏障什么都不是,它只是一個抽象概念,就像OOP。如果這樣說你不理解,那你把他理解成一堵墻,這堵墻正面與反面的指令無法被CPU亂序執行及這堵墻正面與反面的讀寫操作需有序執行。
CPU提供了三個匯編指令串行化運行讀寫指令達到實現保證讀寫有序性的目的:
SFENCE:在該指令前的寫操作必須在該指令后的寫操作前完成
LFENCE:在該指令前的讀操作必須在該指令后的讀操作前完成
MFENCE:在該指令前的讀寫操作必須在該指令后的讀寫操作前完成
何謂串行化?你可以理解成CPU把讀、寫、讀寫請求放入了一個隊列,按照先進先出的順序執行下去;何謂讀操作完成,即CPU執行一次讀操作,把值讀到了寄存器中;何謂寫操作完成,即CPU執行一次寫操作,數據刷到內存中了。
感謝各位的閱讀!關于“計算機中內存屏障由來及實現思路”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





