溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Linux系統驅動開發的知識點有哪些,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
大多數linux的驅動工程師都將文件私有數據private_data指向設備結構體,read等個函數通過調用private_data來訪問設備結構體。這樣做的目的是為了區分子設備,如果一個驅動有兩個子設備(次設備號分別為0和1),那么使用private_data就很方便。 這里有一個函數要提出來:
container_of(ptr,type,member)//通過結構體成員的指針找到對應結構體的的指針 1
其定義如下:
/**
*container_of-castamemberofastructureouttothecontainingstructure
*@ptr: thepointertothemember.
*@type: thetypeofthecontainerstructthisisembeddedin.
*@member: thenameofthememberwithinthestruct.
*
*/
#define container_of(ptr,type,member)({ \
const typeof(((type*)0)->member)*__mptr=(ptr); \
(type*)((char*)__mptr-offsetof(type,member));})可以概括如下圖: 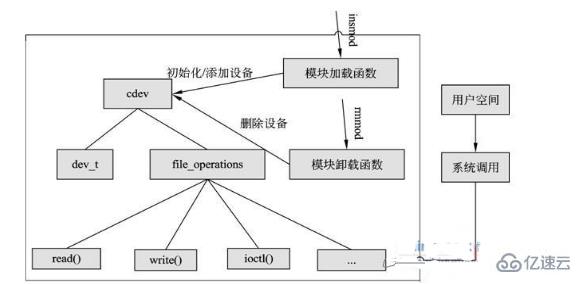 字符設備是3大類設備(字符設備、塊設備、網絡設備)中較簡單的一類設備,其驅動程序中完成的主要工作是初始化、添加和刪除cdev結構體,申請和釋放設備號,以及填充file_operation結構體中操作函數,并實現file_operations結構體中的read()、write()、ioctl()等重要函數。如圖所示為cdev結構體、file_operations和用戶空間調用驅動的關系。
字符設備是3大類設備(字符設備、塊設備、網絡設備)中較簡單的一類設備,其驅動程序中完成的主要工作是初始化、添加和刪除cdev結構體,申請和釋放設備號,以及填充file_operation結構體中操作函數,并實現file_operations結構體中的read()、write()、ioctl()等重要函數。如圖所示為cdev結構體、file_operations和用戶空間調用驅動的關系。
為了避免并發,防止競爭。內核提供了一組同步方法來提供對共享數據的保護。我們的重點不是介紹這些方法的詳細用法,而是強調為什么使用這些方法和它們之間的差別。 Linux使用的同步機制可以說從2.0到2.6以來不斷發展完善。從最初的原子操作,到后來的信號量,從大內核鎖到今天的自旋鎖。這些同步機制的發展伴隨Linux從單處理器到對稱多處理器的過度;伴隨著從非搶占內核到搶占內核的過度。鎖機制越來越有效,也越來越復雜。目前來說內核中原子操作多用來做計數使用,其它情況最常用的是兩種鎖以及它們的變種:一個是自旋鎖,另一個是信號量。
自旋鎖 自旋鎖是專為防止多處理器并發而引入的一種鎖,它在內核中大量應用于中斷處理等部分(對于單處理器來說,防止中斷處理中的并發可簡單采用關閉中斷的方式,不需要自旋鎖)。 自旋鎖最多只能被一個內核任務持有,如果一個內核任務試圖請求一個已被爭用(已經被持有)的自旋鎖,那么這個任務就會一直進行忙循環——旋轉——等待鎖重新可用。要是鎖未被爭用,請求它的內核任務便能立刻得到它并且繼續進行。自旋鎖可以在任何時刻防止多于一個的內核任務同時進入臨界區,因此這種鎖可有效地避免多處理器上并發運行的內核任務競爭共享資源。
自旋鎖的基本形式如下: spin_lock(&mr_lock); //臨界區 spin_unlock(&mr_lock);1234
信號量 Linux中的信號量是一種睡眠鎖。如果有一個任務試圖獲得一個已被持有的信號量時,信號量會將其推入等待隊列,然后讓其睡眠。這時處理器獲得自由去執行其它代碼。當持有信號量的進程將信號量釋放后,在等待隊列中的一個任務將被喚醒,從而便可以獲得這個信號量。 信號量的睡眠特性,使得信號量適用于鎖會被長時間持有的情況;只能在進程上下文中使用,因為中斷上下文中是不能被調度的;另外當代碼持有信號量時,不可以再持有自旋鎖。 信號量基本使用形式為:
static DECLARE_MUTEX(mr_sem);//聲明互斥信號量 if(down_interruptible(&mr_sem)) //可被中斷的睡眠,當信號來到,睡眠的任務被喚醒 //臨界區 up(&mr_sem);12345
信號量和自旋鎖區別 從嚴格意義上說,信號量和自旋鎖屬于不同層次的互斥手段,前者的實現有賴于后者,在信號量本身的實現上,為了保證信號量結構存取的原子性,在多CPU中需要自旋鎖來互斥。 信號量是進程級的。用于多個進程之間對資源的互斥,雖然也是在內核中,但是該內核執行路徑是以進程的身份,代表進程來爭奪進程。鑒于進程上下文切換的開銷也很大,因此,只有當進程占用資源時間比較長時,用信號量才是較好的選擇。 當所要保護的臨界區訪問時間比較短時,用自旋鎖是非常方便的,因為它節省上下文切換的時間,但是CPU得不到自旋鎖會在那里空轉直到執行單元鎖為止,所以要求鎖不能在臨界區里長時間停留,否則會降低系統的效率 由此,可以總結出自旋鎖和信號量選用的3個原則: 1:當鎖不能獲取到時,使用信號量的開銷就是進程上線文切換的時間Tc,使用自旋鎖的開銷就是等待自旋鎖(由臨界區執行的時間決定)Ts,如果Ts比較小時,應使用自旋鎖比較好,如果Ts比較大,應使用信號量。 2:信號量所保護的臨界區可包含可能引起阻塞的代碼,而自旋鎖絕對要避免用來保護包含這樣的代碼的臨界區,因為阻塞意味著要進行進程間的切換,如果進程被切換出去后,另一個進程企圖獲取本自旋鎖,死鎖就會發生。 3:信號量存在于進程上下文,因此,如果被保護的共享資源需要在中斷或軟中斷情況下使用,則在信號量和自旋鎖之間只能選擇自旋鎖,當然,如果一定要是要那個信號量,則只能通過down_trylock()方式進行,不能獲得就立即返回以避免阻塞 自旋鎖VS信號量 需求建議的加鎖方法 低開銷加鎖優先使用自旋鎖 短期鎖定優先使用自旋鎖 長期加鎖優先使用信號量 中斷上下文中加鎖使用自旋鎖 持有鎖是需要睡眠、調度使用信號量
一個驅動當它無法立刻滿足請求應當如何響應?一個對 read 的調用可能當沒有數據時到來,而以后會期待更多的數據;或者一個進程可能試圖寫,但是你的設備沒有準備好接受數據,因為你的輸出緩沖滿了。調用進程往往不關心這種問題,程序員只希望調用 read 或 write 并且使調用返回,在必要的工作已完成后,你的驅動應當(缺省地)阻塞進程,使它進入睡眠直到請求可繼續。 阻塞操作是指在執行設備操作時若不能獲得資源則掛起進程,直到滿足可操作的條件后再進行操作。 一個典型的能同時處理阻塞與非阻塞的globalfifo讀函數如下:
/*globalfifo讀函數*/
static ssize_t globalfifo_read(struct file *filp, char __user *buf, size_t count,
loff_t *ppos)
{
int ret;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
down(&dev->sem); /* 獲得信號量 */
add_wait_queue(&dev->r_wait, &wait); /* 進入讀等待隊列頭 */
/* 等待FIFO非空 */
if (dev->current_len == 0) {
if (filp->f_flags &O_NONBLOCK) {
ret = - EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE); /* 改變進程狀態為睡眠 */
up(&dev->sem);
schedule(); /* 調度其他進程執行 */
if (signal_pending(current)) {
/* 如果是因為信號喚醒 */
ret = - ERESTARTSYS;
goto out2;
}
down(&dev->sem);
}
/* 拷貝到用戶空間 */
if (count > dev->current_len)
count = dev->current_len;
if (copy_to_user(buf, dev->mem, count)) {
ret = - EFAULT;
goto out;
} else {
memcpy(dev->mem, dev->mem + count, dev->current_len - count); /* fifo數據前移 */
dev->current_len -= count; /* 有效數據長度減少 */
printk(KERN_INFO "read %d bytes(s),current_len:%d\n", count, dev->current_len);
wake_up_interruptible(&dev->w_wait); /* 喚醒寫等待隊列 */
ret = count;
}
out:
up(&dev->sem); /* 釋放信號量 */
out2:
remove_wait_queue(&dev->w_wait, &wait); /* 從附屬的等待隊列頭移除 */
set_current_state(TASK_RUNNING);
return ret;
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354使用非阻塞I/O的應用程序通常會使用select()和poll()系統調用查詢是否可對設備進行無阻塞的訪問。select()和poll()系統調用最終會引發設備驅動中的poll()函數被執行。 這個方法由下列的原型:
unsigned int (*poll) (struct file *filp, poll_table *wait); 1
這個驅動方法被調用, 無論何時用戶空間程序進行一個 poll, select, 或者 epoll 系統調用, 涉及一個和驅動相關的文件描述符. 這個設備方法負責這 2 步:
對可能引起設備文件狀態變化的等待隊列,調用poll_wait()函數,將對應的等待隊列頭添加到poll_table.
返回一個位掩碼, 描述可能不必阻塞就立刻進行的操作.
poll_table結構, 給 poll 方法的第 2 個參數, 在內核中用來實現 poll, select, 和 epoll 調用; 它在 中聲明, 這個文件必須被驅動源碼包含. 驅動編寫者不必要知道所有它內容并且必須作為一個不透明的對象使用它; 它被傳遞給驅動方法以便驅動可用每個能喚醒進程的等待隊列來加載它, 并且可改變 poll 操作狀態. 驅動增加一個等待隊列到poll_table結構通過調用函數 poll_wait:
void poll_wait (struct file *, wait_queue_head_t *, poll_table *); 1
poll 方法的第 2 個任務是返回位掩碼, 它描述哪個操作可馬上被實現; 這也是直接的. 例如, 如果設備有數據可用, 一個讀可能不必睡眠而完成; poll 方法應當指示這個時間狀態. 幾個標志(通過 定義)用來指示可能的操作: POLLIN:如果設備可被不阻塞地讀, 這個位必須設置. POLLRDNORM:這個位必須設置, 如果”正常”數據可用來讀. 一個可讀的設備返回( POLLIN|POLLRDNORM ). POLLOUT:這個位在返回值中設置, 如果設備可被寫入而不阻塞. …… poll的一個典型模板如下:
static unsigned int globalfifo_poll(struct file *filp, poll_table *wait)
{
unsigned int mask = 0;
struct globalfifo_dev *dev = filp->private_data; /*獲得設備結構體指針*/
down(&dev->sem);
poll_wait(filp, &dev->r_wait, wait);
poll_wait(filp, &dev->w_wait, wait);
/*fifo非空*/
if (dev->current_len != 0) {
mask |= POLLIN | POLLRDNORM; /*標示數據可獲得*/
}
/*fifo非滿*/
if (dev->current_len != GLOBALFIFO_SIZE) {
mask |= POLLOUT | POLLWRNORM; /*標示數據可寫入*/
}
up(&dev->sem);
return mask;
}123456789101112131415161718192021應用程序如何去使用這個poll呢?一般用select()來實現,其原型為:
int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); 1
其中,readfds, writefds, exceptfds,分別是被select()監視的讀、寫和異常處理的文件描述符集合。numfds是需要檢查的號碼最高的文件描述符加1。 以下是一個具體的例子:
/*======================================================================
A test program in userspace
This example is to introduce the ways to use "select"
and driver poll
The initial developer of the original code is Baohua Song
. All Rights Reserved.
======================================================================*/
#include #include #include #include #include #include
#define FIFO_CLEAR 0x1
#define BUFFER_LEN 20
main()
{
int fd, num;
char rd_ch[BUFFER_LEN];
fd_set rfds,wfds;
/*以非阻塞方式打開/dev/globalmem設備文件*/
fd = open("/dev/globalfifo", O_RDONLY | O_NONBLOCK);
if (fd != - 1)
{
/*FIFO清0*/
if (ioctl(fd, FIFO_CLEAR, 0)其中: FD_ZERO(fd_set *set); //清除一個文件描述符集set FD_SET(int fd, fd_set *set); //將一個文件描述符fd,加入到文件描述符集set中 FD_CLEAR(int fd, fd_set *set); //將一個文件描述符fd,從文件描述符集set中清除 FD_ISSET(int fd, fd_set *set); //判斷文件描述符fd是否被置位。22,并發與競態介紹Linux設備驅動中必須解決一個問題是多個進程對共享資源的并發訪問,并發的訪問會導致競態,在當今的Linux內核中,支持SMP與內核搶占的環境下,更是充滿了并發與競態。幸運的是,Linux 提供了多鐘解決競態問題的方式,這些方式適合不同的應用場景。例如:中斷屏蔽、原子操作、自旋鎖、信號量等等并發控制機制。 并發與競態的概念 并發是指多個執行單元同時、并發被執行,而并發的執行單元對共享資源(硬件資源和軟件上的全局變量、靜態變量等)的訪問則很容易導致競態。 臨界區概念是為解決競態條件問題而產生的,一個臨界區是一個不允許多路訪問的受保護的代碼,這段代碼可以操縱共享數據或共享服務。臨界區操縱堅持互斥鎖原則(當一個線程處于臨界區中,其他所有線程都不能進入臨界區)。然而,臨界區中需要解決的一個問題是死鎖。23, 中斷屏蔽在單CPU 范圍內避免競態的一種簡單而省事的方法是進入臨界區之前屏蔽系統的中斷。CPU 一般都具有屏蔽中斷和打開中斷的功能,這個功能可以保證正在執行的內核執行路徑不被中斷處理程序所搶占,有效的防止了某些競態條件的發送,總之,中斷屏蔽將使得中斷與進程之間的并發不再發生。 中斷屏蔽的使用方法: local_irq_disable() /屏蔽本地CPU 中斷/
…..
critical section /臨界區受保護的數據/
…..
local_irq_enable() /打開本地CPU 中斷/ 12345由于Linux 的異步I/O、進程調度等很多重要操作都依賴于中斷,中斷對內核的運行非常重要,在屏蔽中斷期間的所有中斷都無法得到處理,因此長時間屏蔽中斷是非常危險的,有可能造成數據的丟失,甚至系統崩潰的后果。這就要求在屏蔽了中斷后,當前的內核執行路徑要盡快地執行完臨界區代碼。 與local_irq_disable()不同的是,local_irq_save(flags)除了進行禁止中斷的操作外,還保存當前CPU 的中斷狀態位信息;與local_irq_enable()不同的是,local_irq_restore(flags) 除了打開中斷的操作外,還恢復了CPU 被打斷前的中斷狀態位信息。24, 原子操作原子操作指的是在執行過程中不會被別的代碼路徑所中斷的操作,Linux 內核提供了兩類原子操作——位原子操作和整型原子操作。它們的共同點是在任何情況下都是原子的,內核代碼可以安全地調用它們而不被打斷。然而,位和整型變量原子操作都依賴于底層CPU 的原子操作來實現,因此這些函數的實現都與 CPU 架構密切相關。 1 整型原子操作 1)、設置原子變量的值 void atomic_set(atomic v,int i); /設置原子變量的值為 i */
atomic_t v = ATOMIC_INIT(0); /定義原子變量 v 并初始化為 0 / 122)、獲取原子變量的值 int atomic_read(atomic_t v) /返回原子變量 v 的當前值*/
13)、原子變量加/減 void atomic_add(int i,atomic_t v) /原子變量增加 i */
void atomic_sub(int i,atomic_t v) /原子變量減少 i */
124)、原子變量自增/自減 void atomic_inc(atomic_t v) /原子變量增加 1 */
void atomic_dec(atomic_t v) /原子變量減少 1 */
125)、操作并測試 int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);
123上述操作對原子變量執行自增、自減和減操作后測試其是否為 0 ,若為 0 返回true,否則返回false。注意:沒有atomic_add_and_test(int i, atomic_t *v)。 6)、操作并返回 int atomic_add_return(int i, atomic_t *v);
int atomic_sub_return(int i, atomic_t *v);
int atomic_inc_return(atomic_t *v);
int atomic_dec_return(atomic_t *v);
1234上述操作對原子變量進行加/減和自增/自減操作,并返回新的值。 2 位原子操作 1)、設置位 void set_bit(nr,void addr);/設置addr 指向的數據項的第 nr 位為1 */
12)、清除位 void clear_bit(nr,void addr)/設置addr 指向的數據項的第 nr 位為0 */
13)、取反位 void change_bit(nr,void addr); /對addr 指向的數據項的第 nr 位取反操作*/
14)、測試位 test_bit(nr,void addr);/返回addr 指向的數據項的第 nr位*/
15)、測試并操作位 int test_and_set_bit(nr, void *addr);
int test_and_clear_bit(nr,void *addr);
int test_amd_change_bit(nr,void *addr);
12325, 自旋鎖自旋鎖(spin lock)是一種典型的對臨界資源進行互斥訪問的手段。為了獲得一個自旋鎖,在某CPU 上運行的代碼需先執行一個原子操作,該操作測試并設置某個內存變量,由于它是原子操作,所以在該操作完成之前其他執行單元不能訪問這個內存變量。如果測試結果表明鎖已經空閑,則程序獲得這個自旋鎖并繼續執行;如果測試結果表明鎖仍被占用,則程序將在一個小的循環里面重復這個“測試并設置” 操作,即進行所謂的“自旋”。 理解自旋鎖最簡單的方法是把它當做一個變量看待,該變量把一個臨界區標記為“我在這運行了,你們都稍等一會”,或者標記為“我當前不在運行,可以被使用”。 Linux中與自旋鎖相關操作有: 1)、定義自旋鎖 spinlock_t my_lock;
12)、初始化自旋鎖 spinlock_t my_lock = SPIN_LOCK_UNLOCKED; /靜態初始化自旋鎖/
void spin_lock_init(spinlock_t lock); /動態初始化自旋鎖*/
123)、獲取自旋鎖 /若獲得鎖立刻返回真,否則自旋在那里直到該鎖保持者釋放/
void spin_lock(spinlock_t *lock);
/若獲得鎖立刻返回真,否則立刻返回假,并不會自旋等待/
void spin_trylock(spinlock_t *lock)
12344)、釋放自旋鎖 void spin_unlock(spinlock_t *lock)
1自旋鎖的一般用法: spinlock_t lock; /定義一個自旋鎖/
spin_lock_init(&lock); /動態初始化一個自旋鎖/
……
spin_lock(&lock); /獲取自旋鎖,保護臨界區/
……./臨界區/
spin_unlock(&lock); /解鎖/ 123456自旋鎖主要針對SMP 或單CPU 但內核可搶占的情況,對于單CPU 且內核不支持搶占的系統,自旋鎖退化為空操作。盡管用了自旋鎖可以保證臨界區不受別的CPU和本地CPU內的搶占進程打擾,但是得到鎖的代碼路徑在執行臨界區的時候,還可能受到中斷和底半部(BH)的影響,為了防止這種影響,就需要用到自旋鎖的衍生。 獲取自旋鎖的衍生函數: void spin_lock_irq(spinlock_t lock); /獲取自旋鎖之前禁止中斷*/
void spin_lock_irqsave(spinlock_t lock, unsigned long flags);/獲取自旋鎖之前禁止中斷,并且將先前的中斷狀態保存在flags 中*/
void spin_lock_bh(spinlock_t lock); /在獲取鎖之前禁止軟中斷,但不禁止硬件中斷*/ 123釋放自旋鎖的衍生函數: void spin_unlock_irq(spinlock_t *lock)
void spin_unlock_irqrestore(spinlock_t *lock,unsigned long flags);
void spin_unlock_bh(spinlock_t *lock); 123解鎖的時候注意要一一對應去解鎖。 自旋鎖注意點: (1)自旋鎖實際上是忙等待,因此,只有占用鎖的時間極短的情況下,使用自旋鎖才是合理的。 (2)自旋鎖可能導致系統死鎖。 (3)自旋鎖鎖定期間不能調用可能引起調度的函數。如:copy_from_user()、copy_to_user()、kmalloc()、msleep()等函數。 (4)擁有自旋鎖的代碼是不能休眠的。26, 讀寫自旋鎖它允許多個讀進程并發執行,但是只允許一個寫進程執行臨界區代碼,而且讀寫也是不能同時進行的。 1)、定義和初始化讀寫自旋鎖 rwlock_t my_rwlock = RW_LOCK_UNLOCKED; /* 靜態初始化 */
rwlock_t my_rwlock;
rwlock_init(&my_rwlock); /* 動態初始化 */
1232)、讀鎖定 void read_lock(rwlock_t *lock);
void read_lock_irqsave(rwlock_t *lock, unsigned long flags);
void read_lock_irq(rwlock_t *lock);
void read_lock_bh(rwlock_t *lock); 12343)、讀解鎖 void read_unlock(rwlock_t *lock);
void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void read_unlock_irq(rwlock_t *lock);
void read_unlock_bh(rwlock_t *lock); 1234在對共享資源進行讀取之前,應該先調用讀鎖定函數,完成之后調用讀解鎖函數。 4)、寫鎖定 void write_lock(rwlock_t *lock);
void write_lock_irqsave(rwlock_t *lock, unsigned long flags);
void write_lock_irq(rwlock_t *lock);
void write_lock_bh(rwlock_t *lock);
void write_trylock(rwlock_t *lock); 123455)、寫解鎖 void write_unlock(rwlock_t *lock);
void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void write_unlock_irq(rwlock_t *lock);
void write_unlock_bh(rwlock_t *lock); 1234在對共享資源進行寫之前,應該先調用寫鎖定函數,完成之后應調用寫解鎖函數。讀寫自旋鎖的一般用法: rwlock_t lock; /定義一個讀寫自旋鎖 rwlock/
rwlock_init(&lock); /初始化/
read_lock(&lock); /讀取前先獲取鎖/
…../臨界區資源/
read_unlock(&lock); /讀完后解鎖/
write_lock_irqsave(&lock, flags); /寫前先獲取鎖/
…../臨界區資源/
write_unlock_irqrestore(&lock,flags); /寫完后解鎖/ 1234567827, 順序鎖(sequence lock)順序鎖是對讀寫鎖的一種優化,讀執行單元在寫執行單元對被順序鎖保護的資源進行寫操作時仍然可以繼續讀,而不必等地寫執行單元完成寫操作,寫執行單元也不必等待所有讀執行單元完成讀操作才進去寫操作。但是,寫執行單元與寫執行單元依然是互斥的。并且,在讀執行單元讀操作期間,寫執行單元已經發生了寫操作,那么讀執行單元必須進行重讀操作,以便確保讀取的數據是完整的,這種鎖對于讀寫同時進行概率比較小的情況,性能是非常好的。 順序鎖有個限制,它必須要求被保護的共享資源不包含有指針,因為寫執行單元可能使得指針失效,但讀執行單元如果正要訪問該指針,就會導致oops。 1)、初始化順序鎖 seqlock_t lock1 = SEQLOCK_UNLOCKED; /靜態初始化/
seqlock lock2; /動態初始化/
seqlock_init(&lock2) 1232)、獲取順序鎖 void write_seqlock(seqlock_t *s1);
void write_seqlock_irqsave(seqlock_t *lock, unsigned long flags)
void write_seqlock_irq(seqlock_t *lock);
void write_seqlock_bh(seqlock_t *lock);
int write_tryseqlock(seqlock_t *s1); 123453)、釋放順序鎖 void write_sequnlock(seqlock_t *s1);
void write_sequnlock_irqsave(seqlock_t *lock, unsigned long flags)
void write_sequnlock_irq(seqlock_t *lock);
void write_sequnlock_bh(seqlock_t *lock); 1234寫執行單元使用順序鎖的模式如下: write_seqlock(&seqlock_a);
/寫操作代碼/
……..
write_sequnlock(&seqlock_a); 12344)、讀開始 unsigned read_seqbegin(const seqlock_t *s1);
unsigned read_seqbegin_irqsave(seqlock_t *lock, unsigned long flags); 125)、重讀 int read_seqretry(const seqlock_t *s1, unsigned iv);
int read_seqretry_irqrestore(seqlock_t *lock,unsigned int seq,unsigned long flags); 12讀執行單元使用順序鎖的模式如下: unsigned int seq;
do{
seq = read_seqbegin(&seqlock_a);
/讀操作代碼/
…….
}while (read_seqretry(&seqlock_a, seq)); 12345628, 信號量信號量的使用 信號量(semaphore)是用于保護臨界區的一種最常用的辦法,它的使用方法與自旋鎖是類似的,但是,與自旋鎖不同的是,當獲取不到信號量的時候,進程不會自旋而是進入睡眠的等待狀態。 1)、定義信號量 struct semaphore sem;
12)、初始化信號量 void sema_init(struct semaphore sem, int val); /初始化信號量的值為 val */
1更常用的是下面這二個宏: #define init_MUTEX(sem) sema_init(sem, 1)
#define init_MUTEX_LOCKED(sem) sem_init(sem, 0) 12然而,下面這兩個宏是定義并初始化信號量的“快捷方式” DECLARE_MUTEX(name) /一個稱為name信號量變量被初始化為 1 /
DECLARE_MUTEX_LOCKED(name) /一個稱為name信號量變量被初始化為 0 / 123)、獲得信號量 /該函數用于獲取信號量,若獲取不成功則進入不可中斷的睡眠狀態/
void down(struct semaphore *sem);
/該函數用于獲取信號量,若獲取不成功則進入可中斷的睡眠狀態/
void down_interruptible(struct semaphore *sem);
/該函數用于獲取信號量,若獲取不成功立刻返回 -EBUSY/
int down_trylock(struct sempahore *sem); 1234564)、釋放信號量 void up(struct semaphore sem); /釋放信號量 sem ,并喚醒等待者*/
1信號量的一般用法: DECLARE_MUTEX(mount_sem); /定義一個信號量mount_sem,并初始化為 1 /
down(&mount_sem); /* 獲取信號量,保護臨界區*/
…..
critical section /臨界區/
…..
up(&mount_sem); /釋放信號量/ 12345629, 讀寫信號量讀寫信號量可能引起進程阻塞,但是它允許多個讀執行單元同時訪問共享資源,但最多只能有一個寫執行單元。 1)、定義和初始化讀寫信號量 struct rw_semaphore my_rws; /定義讀寫信號量/
void init_rwsem(struct rw_semaphore sem); /初始化讀寫信號量*/
122)、讀信號量獲取 void down_read(struct rw_semaphore *sem);
int down_read_trylock(struct rw_semaphore *sem);
123)、讀信號量釋放 void up_read(struct rw_semaphore *sem);
14)、寫信號量獲取 void down_write(struct rw_semaphore *sem);
int down_write_trylock(struct rw_semaphore *sem);
125)、寫信號量釋放 void up_write(struct rw_semaphore *sem);
130, completion完成量(completion)用于一個執行單元等待另外一個執行單元執行完某事。 1)、定義完成量 struct completion my_completion;
12)、初始化完成量 init_completion(&my_completion);
13)、定義并初始化的“快捷方式” DECLARE_COMPLETION(my_completion)
14)、等待完成量 void wait_for_completion(struct completion c); /等待一個 completion 被喚醒*/
15)、喚醒完成量 void complete(struct completion c); /只喚醒一個等待執行單元*/
void complete(struct completion c); /喚醒全部等待執行單元*/
1231, 自旋鎖VS信號量信號量是進程級的,用于多個進程之間對資源的互斥,雖然也是在內核中,但是該內核執行路徑是以進程的身份,代表進程來爭奪資源的。如果競爭失敗,會發送進程上下文切換,當前進程進入睡眠狀態,CPU 將運行其他進程。鑒于開銷比較大,只有當進程資源時間較長時,選用信號量才是比較合適的選擇。然而,當所要保護的臨界區訪問時間比較短時,用自旋鎖是比較方便的。 總結: 解決并發與競態的方法有(按本文順序): (1)中斷屏蔽 (2)原子操作(包括位和整型原子) (3)自旋鎖 (4)讀寫自旋鎖 (5)順序鎖(讀寫自旋鎖的進化) (6)信號量 (7)讀寫信號量 (8)完成量 其中,中斷屏蔽很少單獨被使用,原子操作只能針對整數進行,因此自旋鎖和信號量應用最為廣泛。自旋鎖會導致死循環,鎖定期間內不允許阻塞,因此要求鎖定的臨界區小;信號量允許臨界區阻塞,可以適用于臨界區大的情況。讀寫自旋鎖和讀寫信號量分別是放寬了條件的自旋鎖 信號量,它們允許多個執行單元對共享資源的并發讀。至此關于Linux系統驅動的教程分享結束,大家有任何問題都可以在評論區留言啊。以上就是良許教程網為各位朋友分享的Linux系統相關內容。想要了解更多Linux相關知識記得關注公眾號“良許Linux”,或掃描下方二維碼進行關注,更多干貨等著你!看完上述內容,你們掌握Linux系統驅動開發的知識點有哪些的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





