溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“CentOS 6.8如何安裝并使用JStorm集群”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“CentOS 6.8如何安裝并使用JStorm集群”文章能幫助大家解決問題。
JStorm 是參考 Apache Storm 實現的實時流式計算框架,在網絡IO、線程模型、資源調度、可用性及穩定性上做了持續改進,已被越來越多企業使用。

從應用的角度,JStorm應用是一種遵守某種編程規范的分布式應用。從系統角度, JStorm是一套類似MapReduce的調度系統。 從數據的角度,JStorm是一套基于流水線的消息處理機制。
實時計算現在是大數據領域中最火爆的一個方向,因為人們對數據的要求越來越高,實時性要求也越來越快,傳統的Hadoop MapReduce,逐漸滿足不了需求,因此在這個領域需求不斷。
| JStorm | Hadoop | |
|---|---|---|
| 角色 | Nimbus | JobTracker |
| Supervisor | TaskTracker | |
| Worker | Child | |
| 應用名稱 | Topology | Job |
| 編程接口 | Spout/Bolt | Mapper/Reducer |
在Storm和JStorm出現以前,市面上出現很多實時計算引擎,但自Storm和JStorm出現后,基本上可以說一統江湖: 究其優點:
JStorm處理數據的方式是基于消息的流水線處理, 因此特別適合無狀態計算,也就是計算單元的依賴的數據全部在接受的消息中可以找到, 并且最好一個數據流不依賴另外一個數據流。
因此,常常用于:
首先,JStorm有點類似于Hadoop的MR(Map-Reduce),但是區別在于,hadoop的MR,提交到hadoop的MR job,執行完就結束了,進程就退出了,而一個JStorm任務(JStorm中稱為topology),是7*24小時永遠在運行的,除非用戶主動kill。
接下來是一張比較經典的Storm的大致的結構圖(跟JStorm一樣):
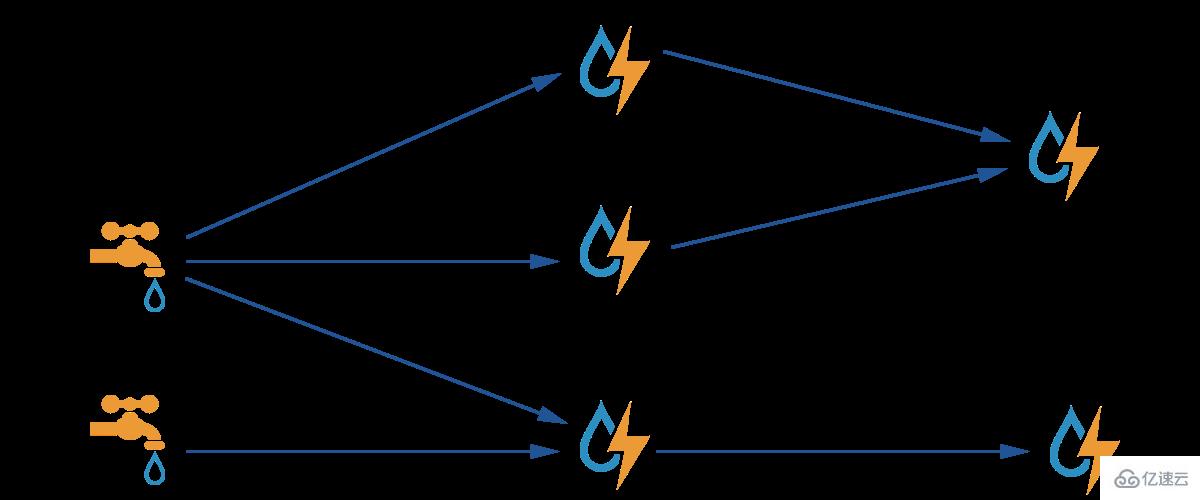
圖中的水龍頭(好吧,有點俗)就被稱作spout,閃電被稱作bolt。
在JStorm的topology中,有兩種組件:spout和bolt。
# spout
spout代表輸入的數據源,這個數據源可以是任意的,比如說kafaka,DB,HBase,甚至是HDFS等,JStorm從這個數據源中不斷地讀取數據,然后發送到下游的bolt中進行處理。
# bolt
bolt代表處理邏輯,bolt收到消息之后,對消息做處理(即執行用戶的業務邏輯),處理完以后,既可以將處理后的消息繼續發送到下游的bolt,這樣會形成一個處理流水線(pipeline,不過更精確的應該是個有向圖);也可以直接結束。
通常一個流水線的最后一個bolt,會做一些數據的存儲工作,比如將實時計算出來的數據寫入DB、HBase等,以供前臺業務進行查詢和展現。
JStorm框架對spout組件定義了一個接口:nextTuple,顧名思義,就是獲取下一條消息。執行時,可以理解成JStorm框架會不停地調這個接口,以從數據源拉取數據并往bolt發送數據。
同時,bolt組件定義了一個接口:execute,這個接口就是用戶用來處理業務邏輯的地方。
每一個topology,既可以有多個spout,代表同時從多個數據源接收消息,也可以多個bolt,來執行不同的業務邏輯。
接下來就是topology的調度和執行原理,對一個topology,JStorm最終會調度成一個或多個worker,每個worker即為一個真正的操作系統執行進程,分布到一個集群的一臺或者多臺機器上并行執行。
而每個worker中,又可以有多個task,分別代表一個執行線程。每個task就是上面提到的組件(component)的實現,要么是spout要么是bolt。
用戶在提交一個topology的時候,會指定以下的一些執行參數:
#總worker數
即總的進程數。舉例來說,我提交一個topology,指定worker數為3,那么最后可能會有3個進程在執行。之所以是可能,是因為根據配置,JStorm有可能會添加內部的組件,如_acker或者__topology_master(這兩個組件都是特殊的bolt),這樣會導致最終執行的進程數大于用戶指定的進程數。我們默認是如果用戶設置的worker數小于10個,那么__topology_master 只是作為一個task存在,不獨占worker;如果用戶設置的worker數量大于等于10個,那么__topology_master作為一個task將獨占一個worker
#每個component的并行度
上面提到每個topology都可以包含多個spout和bolt,而每個spout和bolt都可以單獨指定一個并行度(parallelism),代表同時有多少個線程(task)來執行這個spout或bolt。
JStorm中,每一個執行線程都有一個task id,它從1開始遞增,每一個component中的task id是連續的。
還是上面這個topology,它包含一個spout和一個bolt,spout的并行度為5,bolt并行度為10。那么我們最終會有15個線程來執行:5個spout執行線程,10個bolt執行線程。
這時spout的task id可能是1~5,bolt的task id可能是6~15,之所以是可能,是因為JStorm在調度的時候,并不保證task id一定是從spout開始,然后到bolt的。但是同一個component中的task id一定是連續的。
#每個component之間的關系
即用戶需要去指定一個特定的spout發出的數據應該由哪些bolt來處理,或者說一個中間的bolt,它發出的數據應該被下游哪些bolt處理。
還是以上面的topology為例,它們會分布在3個進程中。JStorm使用了一種均勻的調度算法,因此在執行的時候,你會看到,每個進程分別都各有5個線程在執行。當然,由于spout是5個線程,不能均勻地分配到3個進程中,會出現一個進程只有1個spout線程的情況;同樣地,也會出現一個進程中有4個bolt線程的情況。
在一個topology的運行過程中,如果一個進程(worker)掛掉了,JStorm檢測到之后,會不斷嘗試重啟這個進程,這就是7*24小時不間斷執行的概念。
上面提到,spout的消息會發送給特定的bolt,bolt也可以發送給其他的bolt,那這之間是如何通信的呢?
首先,從spout發送消息的時候,JStorm會計算出消息要發送的目標task id列表,然后看目標task id是在本進程中,還是其他進程中,如果是本進程中,那么就可以直接走進程內部通信(如直接將這個消息放入本進程中目標task的執行隊列中);如果是跨進程,那么JStorm會使用netty來將消息發送到目標task中。
JStorm是7*24小時運行的,外部系統如果需要查詢某個特定時間點的處理結果,并不會直接請求JStorm(當然,DRPC可以支持這種需求,但是性能并不是太好)。一般來說,在JStorm的spout或bolt中,都會有一個定時往外部存儲寫計算結果的邏輯,這樣數據可以按照業務需求被實時或者近實時地存儲起來,然后直接查詢外部存儲中的計算結果即可。
以上內容直接粘貼JStorm官網,切勿吐槽
二、 Jstorm 集群安裝
1、系統環境準備
# OS: CentOS 6.8 mininal# host.ip: 10.1.1.78 aniutv-1# host.ip: 10.1.1.80 aniutv-2# host.ip: 10.1.1.97 aniutv-5
2、安裝目錄自定義
jstorm : /opt/jstorm (源碼安裝);
zookeeper : /opt/zookeeper(源碼安裝);
java : /usr/java/jdk1.7.0_79 (rpm包安裝)
3、zookeeper 集群安裝
zookeeper 集群參考(http://blog.csdn.net/wh311212/article/details/56014983)
4、zeromq 安裝
zeromq下載地址:http://zeromq.org/area:download/
下載zeromq-4.2.1.tar.gz 到/usr/local/src
cd /usr/local/src && tar -zxf zeromq-4.2.1.tar.gz -C /opt
cd /opt/zeromq-4.2.1 && ./configure && make && sudo make install && sudo ldconfig
5、jzmq安裝
cd /opt && git clone https://github.com/nathanmarz/jzmq.git ./autogen.sh && ./configure && make && make install
6、JStorm安裝
wget https://github.com/alibaba/jstorm/releases/download/2.1.1/jstorm-2.1.1.zip -P /usr/local/srccd /usr/local/src && unzip jstorm-2.1.1.zip -d /optcd /opt && mv jstorm-2.1.1 jstorm# mkdir /opt/jstorm/jstorm_dataecho '# jstorm env' >> ~/.bashrcecho 'export JSTORM_HOME=/opt/jstorm' >> ~/.bashrcecho 'export PATH=$PATH:$JSTORM_HOME/bin' >> ~/.bashrcsource ~/.bashrc
# JStorm 配置
sed -i /'storm.zookeeper.servers:/a\ - "10.1.1.78"' /opt/jstorm/conf/storm.yaml sed -i /'storm.zookeeper.servers:/a\ - "10.1.1.80"' /opt/jstorm/conf/storm.yaml sed -i /'storm.zookeeper.servers:/a\ - "10.1.1.97"' /opt/jstorm/conf/storm.yaml sed -i /'storm.zookeeper.root/a\ nimbus.host: "10.1.1.78"' /opt/jstorm/conf/storm.yaml
配置項:
storm.zookeeper.servers: 表示zookeeper 的地址;
nimbus.host: 表示nimbus的地址;
storm.zookeeper.root: 表示JStorm在zookeeper中的根目錄,當多個JStorm共享一個zookeeper時,需要設置該選項,默認即為“/jstorm”;
storm.local.dir: 表示JStorm臨時數據存放目錄,需要保證JStorm程序對該目錄有寫權限;
java.library.path: Zeromq 和java zeromq library的安裝目錄,默認”/usr/local/lib:/opt/local/lib:/usr/lib”;
supervisor.slots.ports: 表示Supervisor 提供的端口Slot列表,注意不要和其他端口發生沖突,默認是68xx,而Storm的是67xx;
topology.enable.classloader: false, 默認關閉classloader,如果應用的jar與JStorm的依賴的jar發生沖突,比如應用使用thrift9,但jstorm使用thrift7時,就需要打開classloader。建議在集群級別上默認關閉,在具體需要隔離的topology上打開這個選項。
# 下面命令只需要在安裝 jstorm_ui 和提交jar節點的機器上面執行即可
mkdir ~/.jstorm cp -f $JSTORM_HOME/conf/storm.yaml ~/.jstorm
7、安裝JStorm Web UI
強制使用tomcat7.0或以上版本,切記拷貝**~/.jstorm/storm.yaml,** Web UI 可以和Nimbus在同一個節點上
mkdir ~/.jstorm cp -f $JSTORM_HOME/conf/storm.yaml ~/.jstorm 下載tomcat 7.x (以apache-tomcat-7.0.37 為例) tar -xzf apache-tomcat-7.0.75.tar.gzcd apache-tomcat-7.0.75cd webapps cp $JSTORM_HOME/jstorm-ui-2.1.1.war ./ mv ROOT ROOT.old ln -s jstorm-ui-2.1.1 ROOT # 另外不是 ln -s jstorm-ui-2.1.1.war ROOT 這個要小心cd ../bin ./startup.sh
8、JStorm啟動
1.在nimbus 節點(10.1.1.78)上執行 “nohup jstorm nimbus &”, 查看$JSTORM_HOME/logs/nimbus.log檢查有無錯誤
2.在supervisor節點(10.1.1.78,10.1.1.80,10.1.1.97)上執行 “nohup jstorm supervisor &”, 查看$JSTORM_HOME/logs/supervisor.log檢查有無錯誤
關于“CentOS 6.8如何安裝并使用JStorm集群”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





