溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
參考劉鵬的《實戰Hadoop》一書,按照hadoop 0.20.2幾個注意的地方。
第一,首先理解Hadoop中的幾個后臺進程。
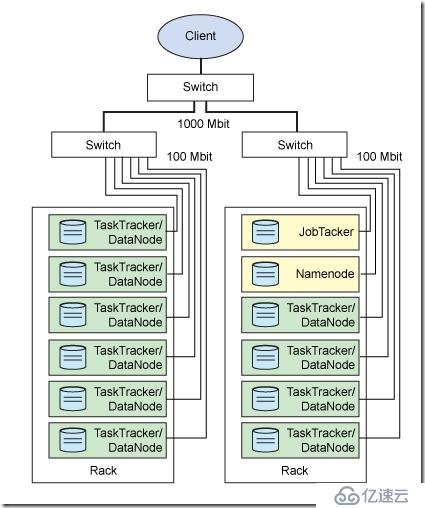
NameNode,Secondary NameNode,JobTracker,TaskTracker,DataNode這幾個角色。
NameNode:負責如何切分數據塊,和切完放哪個節點。它對內存和I/O集中管理。
這個進程部署在Master節點上,是一個單點,它掛了整個系統都掛了。
Secondary NameNode:和NameNode一樣,輔助程序。每個集群都有一個,它與NameNode進行通訊,定期保存HDFS元數據快照,當NameNode故障可以作為備用NameNode使用。它也是部署在Master節點上。
JobTracker負責調度作業,它決定哪些文件由哪些節點運行,并且監聽TaskTracker發送來的心跳。當收不到心跳,即認為某個task失敗,就會決定重啟task。每個集群只有一個JobTracker。它是部署在Master節點上的。
上述三個進程都是部署在Master節點上的,而TaskTracker和DataNode進程進程是集群中各個幾點都需要部署的。
DataNode負責將HDFS數據塊讀寫到本地文件系統。當客戶端讀寫某個數據庫的時候,由NameNode告訴客戶端去那個DataNode進行,然后客戶端直接與這個DataNode的服務器通信,并操作相關的數據塊。
TaskTracker也是位于從節點的,它負責獨立執行具體的Task,每個從節點只能有一個TaskTracker,但是每個TaskTracker可以產生多個Java虛擬機,用于并行處理多個map和reduce認為。TaskTracker還會和JobTracker交互,JobTasker負責分配Task,并且檢測TaskTracker的心跳,如果沒有心跳,就認為已經崩潰,并將認為分配給其他的TaskTracker。
各個進程的部署圖如下:
具體的安裝環節,可以參考書中的步驟,但是有幾個點需要注意。
主機和從機統一創建專門的運行hadoop的用戶grid, 設置SSH的免密碼登陸機制,可以參考http://chenlb.iteye.com/blog/211809。將所有的機器上的公鑰文件上里的內容,都統一整合到一個authorized_keys文件,以此實現互相免密碼登陸ssh。
啟動hadoop的時候,注意要以grid用戶登錄,在grid用戶的主目錄下進行操作,有時權限的問題,此時要注意將主機和從機的hadoop文件夾的owner設置為grid用戶和組。執行 chown -R grid:grid /home/grid/hadoop-1.2.1 (此處為hadoop的放置目錄,這里要使用root用戶修改)
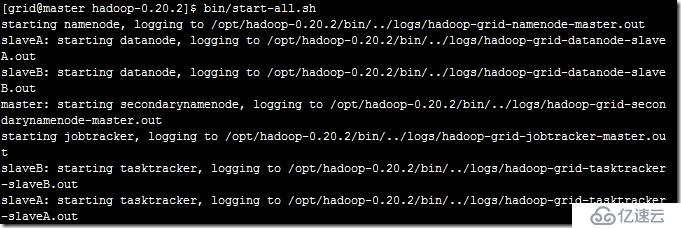
然后可以到hadoop的文件夾中的bin目錄下啟動start-all.sh,可以看到如下的信息,說明啟動成功。
此時還可以通過運行命令查看進程的啟動情況,在主機上運行jdk中的jps文件,可以看到如下:
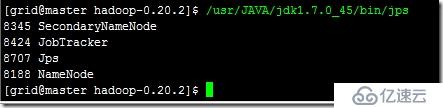
在從節點運行相同的命令,可以看到

至此,說明安裝Hadoop已經成功了。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





