溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

(1)創建數據庫create database db_hive2;`<br/>`或者`<br/>`create database if not exists db_hive;
數據庫在HDFS上的默認存儲路徑/user/hive/warehouse/*.db
(2)顯示所有數據庫show databases;
(3)查詢數據庫show database like ‘db_hive’;
(4)查詢數據庫詳情desc database db_hive;
(5)顯示數據庫 desc database extended db_hive;
(6)切換當前數據庫use db_hive;
(7)刪除數據庫
#刪除為空的數據控drop database db_hive;
#如果刪除的數據庫不存在,最好采用if exists判斷數據庫是否存在drop database if exists db_hive;
#如果數據庫中有表存在,需要使用cascade強制刪除數據庫drop database if exists db_hive cascade;
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [COMMENT col_comment], ...)][COMMENT table_comment] 表的描述可加可不加[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分區[CLUSTERED BY (col_name, col_name, ...) 分桶[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
重點:讀取文本是讀一行數據,需要用分隔符分割,用來匹配表的列[ROW FORMAT row_format] row format delimited fields terminated by “分隔符”[STORED AS file_format] 存儲對應的文件格式[LOCATION hdfs_path]存儲在hdfs的哪個目錄
字段解釋說明:
CREATE TABLE :創建指定名稱的表,如果存在報異常,可以使用 IF NOT EXISTS :來避免這個異常。EXTERNAL:創建外部表,在建表的同時可以指定源數據的路徑LOCATION:創建內部表時,會將數據移動到數據倉庫指向的路徑,若創建外部表不會有任何改變。在刪除表時,內部表的元數據和源數據都會被刪除,外部表不會刪除源數據。COMMENT:為表和列增加注釋PARTITIONED BY:創建分區表CLUSTERED BY:創建分桶表SORTED BY:創建排序后分桶表(不常用)STORED AS :指定存儲文件類型sequencefile(二進制序列文件)、textfile(文本)、rcfile(列式存儲格式文件),如果文件數據是純文本,可以使用STORED AS TEXTFILE。如果需要使用壓縮,使用STORED AS SEQUENCEFILELOCATION 指定表在 hdfs 上的存儲位置
1、直接使用標準的建表語句:
create table if not exists student11(id int,name string)row format delimited fields terminated by '\t'stored as textfile;
使用文本data.txt
1 zhang
2 lisi
2、查詢建表法:
通過AS查詢語句完成建表:將子查詢的結果存放在新表里,有數據
create table if not exists student1 as select id,name from student;
3、like建表法:
根據已存在的表結構創建表
create table if not exists student2 like student;
4、查詢表的類型:
desc formatted student;
5、內部表的默認位置:
(根據自己情況來定)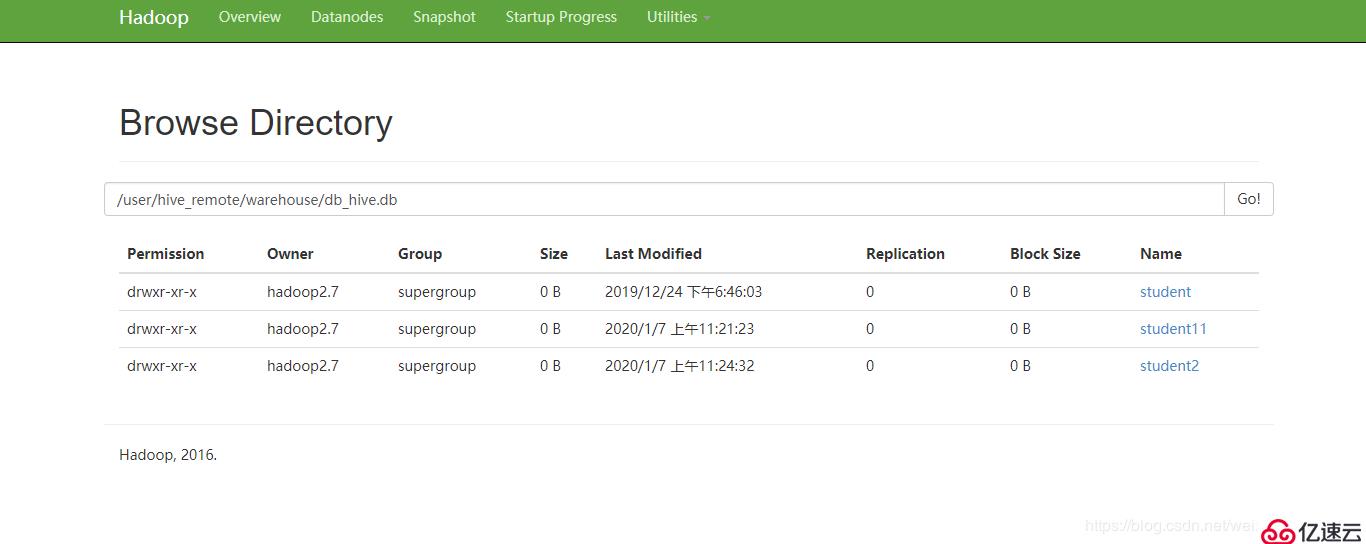
/user/hive_remote/warehouse/db_hive.db
6、將數據導入到Hive表中:
舉列子:student11s是Hive表
load data local inpath '/opt/bigdata2.7/hivedata/student.txt' into table student11;
注意:default是數據庫的名
create external table if not exists default.emp(id int,name string)row format delimited fields terminated by '\t'location '/ opt/bigdata2.7/hivedata'
創建外部表的時候需要加上external關鍵字,location字段可以指定,也可以不指定,不指定的話就是使用默認目錄/user/hive/warehouse
? 1、內部表轉換為外部表
#把student 內部表改為外部表
alter table student set tblproperties('EXTERNAL'='TRUE');
? 2、外部表轉換成內部表
alter table student set tblproperties('EXTERNAL'='FALSE');
1、建表語法不同:
外部表建表的時候需要加上external關鍵字
2、數據存儲位置不同:
創建內部表的時候,會將數據移動到數據倉庫指向的路徑;若創建外部表,僅僅記錄數據所在的路徑,不對數據的位置進行任何改變。
2、刪除表之后:
內部表會刪除元數據,刪除表的數據。
外部表刪除之后,僅僅是把表的元數據刪除了,真實的數據還在,后期還可以恢復出來。
1、數據格式:
戰狼1,吳京1:吳剛1:小明1,2017-08-01
戰狼2,吳京2:吳剛2:小明2,2017-08-02
戰狼3,吳京4:吳剛4:小明4,2017-08-03
戰狼4,吳京3:吳剛3:小明3,2017-08-04
戰狼5,吳京5:吳剛5:小明5,2017-08-05
2、建表語句:
create table t_movie(movie_name string,actors array<string>,first_date string)row format delimited fields terminated by ','collection items terminated by ':';
3、導入數據:
確保hadoop用戶對該文件夾有讀寫權限。load data local inpath '/opt/bigdata2.7/hive/movie';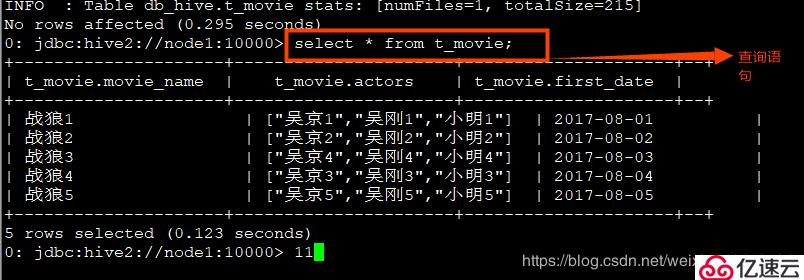
4、查詢每個電影的第二個主演:
select movie_name,actors[1] from t_movie;
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-hgfz0RZZ-1579482997640)(2%E3%80%81Hive%E7%9A%84DDL%E8%AF%AD%E6%B3%95%E6%93%8D%E4%BD%9C.assets/image-20200109093038358.png)]
5、查詢每部電影有幾名主演:
select movie_name,size(actors) as num from t_movie;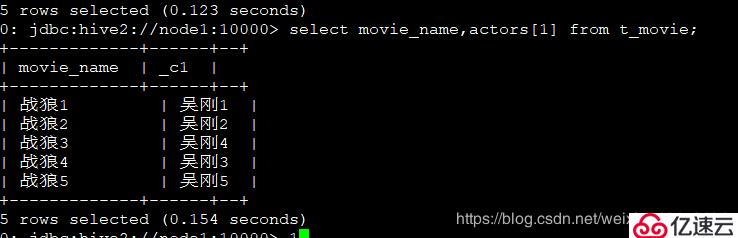
6、主演里包含吳剛5的電影
select movie_name,actors from t_movie where array_contains(actors,'吳剛5');
解析:
這里我們首先看到比較特殊的是主演的名字,而名字有都是string類型的,所以考慮到使用array類型,以為array存儲的都是想同類型的元素。這里我們要使用collection items terminated by ':',來設置指定復雜元素數據類型中元素的分隔符。
需要注意的是:collection items terminated by不僅是用來分隔array的,它的作用是分隔復雜數據類型里面的元素的。size內置函數是用來判斷array元素的個數,array_contains()是判斷array是否有這個元素。
1、數據格式:
1,張三,18:male:北京
2,李四,19:male:南京
3,王五,20:male:上海
4,哈哈,18:male:北京
5,嘿嘿,12:male:成都
6,嘻嘻,14:male:濟南
7,張麗,17:male:深圳
8,李物,19:male:重慶
2、建表語句:
create table t_user(id int,name string,info struct<age:string,sex:string,addr:string>)row format delimited fields terminated by ','collection items terminated by ':';
3、導入數據:
load data local inpath '/opt/bigdata2.7/hive/user' into table t_user;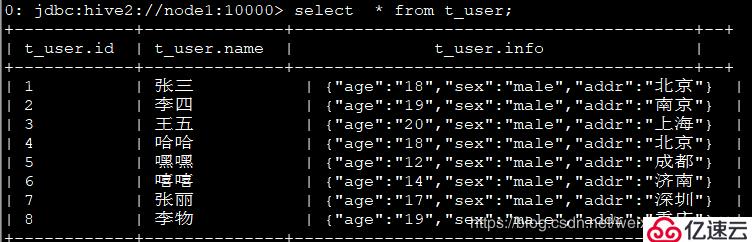
4、 查詢每一個人的id,名字,居住地址:
select id,name,info.addr from t_user;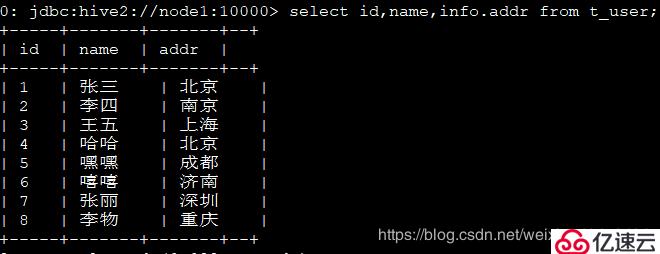
解析:
這里比較特殊的字段是18:male:北京,對應的是年齡:性別:地址,每一個都有特殊的含義,我們考慮到無法構成一個鍵值對,所以map不合適,array只能包含相同的元素,而年齡是int類型,地址是strin類型,所以array不合適,所以考慮struct。
1、數據描述:
1,小明,father:張三#mother:李麗#brother:小剛,28
2,小鴻,father:李四#mother:王麗#brother:小志,28
3,小鵬,father:張物#mother:李美#brother:小英,28
4,張飛,father:張五#mother:李影#brother:小全,28
2、建表語句:
create table t_family(id int,name string,family_mem map<string,string>,age int)row format delimited fields terminated by ','collection items terminated by '#'map keys terminated by ':';
3、導入數據:
load data local inpath '/opt/bigdata2.7/hive/family' into table t_family;
4、查看每個人的父親:
select name,family_mem["father"] from t_family;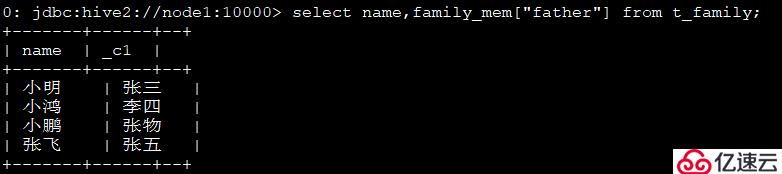
5、查看有哪些親屬關系:select name,map_keys(family_mem),age from t_family;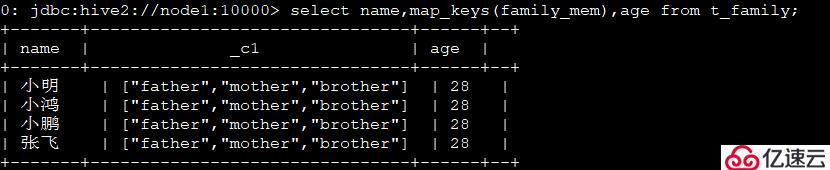
6、查出每個人的親人名字:
select name,map_values(family_mem) as relations,age from t_family;
7、查出每個人親人的數量:
select id,name,size(family_mem) as relation_num,age from t_family;
alter table student_partition1 rename to student_partition2
desc student_partition3;
desc formated student_partition3;
增加列:
alter table student_partition3 add columns(address string);
修改列:
alter table student_partition3 change column address address_id int;
替換列:
alter table student_partition3 replace columns(deptno string,dname string,loc string);
1、添加分區:
(1)添加單個分區:
alter table student_partition1 add partition(dt='20170601');
(2)添加多個分區:
alter table student_partition1 add partition(dt='20170602') partition(dt='20170603');
2、刪除分區:
alter table student_partition1 drop partition (dt='20170601');
alter table student_partition1 drop partition (dt='20170601') partition (dt='20170602');
3、查看分區:
show partitions student_partition1;
load data [local] impath 'datapath' overwrite | into table student [partition (partcol1=val1,...)];
load data: 表示加載數據
local:表示從本地加載數據到hive表中;否則從HDFS加載到hive表中
inpath: 表示加載數據的路徑
overwite:表示覆蓋表中已有數據,否則表示追加
into table:表示加載到哪張表
普通表舉例:
load data local inpath '/opt/bigdata2.7/hive/person.txt' into table person;
分區表舉例:
load data local inpath '/opt/bigdata2.7/hive/person.txt' into table person partition (dt="20190202");
從指定的表中查詢數據結果然后插入到目標表中
insert into/overwrite table tablename select **** from tablename;
insert into table student_partion1 partition(dt="2019-07-08") select * from tablename;
create table if not exists tablename as select id,name from tablename;
創建表,并指定在hdfs上的位置
create table if not exists student1(id int,name string)row format delimited fields terminated by '\t'location '/usr/hive_remote/warehouse/student1';
create table if not exists person(id int,name string,age int,sex string)row format delimited fields terminated by ',';
上傳數據文件到hdfs對應的目錄中
在Linux中運行,注意不是hive端口
hdfs dfs -put /opt/bigdata2.7/hive/student1.txt /usr/hive_remote/warehouse/student1
注意:先用export導出之后,再將數據導入
create table student2 like student1;
export table student1 to '/export/student1';
import table student2 from 'export/student1'
1、將查詢數據的結果導出到本地
insert overwrite local directory '/opt/bigdata/export/student' select * from student;
2、將查詢結構格式化的導出到本地
insert overwrite local directory '/opt/bigdata/export/student' row format delimited fields teminated by ','select * from student;
3、將查詢結果導出到HDFS(沒有local)
insert overwrite directory '/user/export/student' row format delimited fields terminated by ','select * from student;
hdfs dfs -get /user/hive_remote/warehouse/student/student.txt /opt/bigdata2.7/data
hive -e 'select * from default.student' > /opt/bigdata/data/student1.txt
export table default.student to '/user/hive/warehouse/export/student1';
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





