溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
實驗環境
CentOS 6.X
Hadoop 2.6.0
JDK 1.8.0_65
目的
這篇文檔的目的是幫助你快速完成單機上的Hadoop安裝與使用以便你對Hadoop分布式文件系統(HDFS)和Map-Reduce框架有所體會,比如在HDFS上運行示例程序或簡單作業等。
先決條件
支持平臺
GNU/Linux是產品開發和運行的平臺。 Hadoop已在有2000個節點的GNU/Linux主機組成的集群系統上得到驗證。
Win32平臺是作為開發平臺支持的。由于分布式操作尚未在Win32平臺上充分測試,所以還不作為一個生產平臺被支持。
安裝軟件
如果你的集群尚未安裝所需軟件,你得首先安裝它們。
以 CentOS 為例:
# yum install ssh rsync -y
# ssh 必須安裝并且保證 sshd一直運行,以便用Hadoop 腳本管理遠端Hadoop守護進程。
創建用戶
# useradd -m hadoop -s /bin/bash # 創建新用戶hadoop
Hosts解析
# cat /etc/hosts| grep ocean-lab
192.168.9.70 ocean-lab.ocean.org ocean-lab
安裝jdk
JDK – http://www.oracle.com/technetwork/java/javase/downloads/index.html
首先安裝JAVA環境
# wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u65-b17/jdk-8u65-linux-x64.rpm"
# rpm -Uvh jdk-8u65-linux-x64.rpm
配置 Java
# echo "export JAVA_HOME=/usr/java/jdk1.8.0_65" >> /home/hadoop/.bashrc
# source /home/hadoop/.bashrc
# echo $JAVA_HOME
/usr/java/jdk1.8.0_65
下載安裝hadoop
為了獲取Hadoop的發行版,從Apache的某個鏡像服務器上下載最近的 穩定發行版。
運行Hadoop集群的準備工作
# wget http://apache.fayea.com/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
解壓所下載的Hadoop發行版。編輯 conf/hadoop-env.sh文件,至少需要將JAVA_HOME設置為Java安裝根路徑。
# tar xf hadoop-2.6.0.tar.gz -C /usr/local
#### mv /usr/local/hadoop-2.6.0 /usr/local/hadoop
嘗試如下命令:
# bin/hadoop
將會顯示hadoop 腳本的使用文檔。
現在你可以用以下三種支持的模式中的一種啟動Hadoop集群:
單機模式
偽分布式模式
完全分布式模式
單機模式的操作方法
默認情況下,Hadoop被配置成以非分布式模式運行的一個獨立Java進程。這對調試非常有幫助。
現在我們可以執行例子來感受下 Hadoop 的運行。Hadoop 附帶了豐富的例子包括 wordcount、terasort、join、grep 等。
在此我們選擇運行 grep 例子,我們將 input 文件夾中的所有文件作為輸入,篩選當中符合正則表達式 dfs[a-z.]+ 的單詞并統計出現的次數,最后輸出結果到 output 文件夾中。
# mkdir input
# cp conf/*.xml input
# ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep ./input/ ./ouput 'dfs[a-z.]+'
# cat output/*
若執行成功的話會輸出很多作業的相關信息,最后的輸出信息如下圖所示。作業的結果會輸出在指定的 output 文件夾中,通過命令 cat ./output/* 查看結果,符合正則的單詞 dfsadmin 出現了1次:
[10:57:58][hadoop@ocean-lab hadoop-2.6.0]$ cat ./ouput/*
1 dfsadmin
注意,Hadoop 默認不會覆蓋結果文件,因此再次運行上面實例會提示出錯,需要先將 ./output 刪除。
否則會報如下錯誤
INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/usr/local/hadoop-2.6.0/ouput already exists
若出現提示 “INFO metrics.MetricsUtil: Unable to obtain hostName java.net.UnknowHostException”,這需要執行如下命令修改 hosts 文件,為你的主機名增加IP映射:
# cat /etc/hosts| grep ocean-lab
192.168.9.70 ocean-lab.ocean.org ocean-lab
偽分布式模式的操作方法
Hadoop可以在單節點上以所謂的偽分布式模式運行,此時每一個Hadoop守護進程都作為一個獨立的Java進程運行。
節點既作為 NameNode 也作為 DataNode,同時,讀取的是 HDFS 中的文件。
在設置 Hadoop 偽分布式配置前,我們還需要設置 HADOOP 環境變量,執行如下命令在 ~/.bashrc 中設置
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop-2.6.0
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source ~/.bashrc
配置
使用如下的 etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.6.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同樣的,修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.6.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.6.0/tmp/dfs/data</value>
</property>
</configuration>
關于Hadoop配置項的一點說明
雖 然只需要配置 fs.defaultFS 和 dfs.replication 就可以運行(官方教程如此),不過若沒有配置 hadoop.tmp.dir 參數,則默認使用的臨時目錄為 /tmp/hadoo-hadoop,而這個目錄在重啟時有可能被系統清理掉,導致必須重新執行 format 才行。所以我們進行了設置,同時也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否則在接下來的步驟中可能會出錯。
免密碼ssh設置
現在確認能否不輸入口令就用ssh登錄localhost:
# ssh localhost date
如果不輸入口令就無法用ssh登陸localhost,執行下面的命令:
# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
#chmod 600 ~/.ssh/authorized_keys
格式化一個新的分布式文件系統:
$ bin/hadoop namenode -format
15/12/23 11:30:20 INFO util.GSet: VM type = 64-bit
15/12/23 11:30:20 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
15/12/23 11:30:20 INFO util.GSet: capacity = 2^15 = 32768 entries
15/12/23 11:30:20 INFO namenode.NNConf: ACLs enabled? false
15/12/23 11:30:20 INFO namenode.NNConf: XAttrs enabled? true
15/12/23 11:30:20 INFO namenode.NNConf: Maximum size of an xattr: 16384
15/12/23 11:30:20 INFO namenode.FSImage: Allocated new BlockPoolId: BP-823870322-192.168.9.70-1450841420347
15/12/23 11:30:20 INFO common.Storage: Storage directory /usr/local/hadoop-2.6.0/tmp/dfs/name has been successfully formatted.
15/12/23 11:30:20 INFO namenode.NNStorageRetentionManager: Going to retain 1 p_w_picpaths with txid >= 0
15/12/23 11:30:20 INFO util.ExitUtil: Exiting with status 0
15/12/23 11:30:20 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ocean-lab.ocean.org/192.168.9.70
************************************************************/
成功的話,會看到 “successfully formatted” 和 “Exitting with status 0″ 的提示
注意
下次啟動 hadoop 時,無需進行 NameNode 的初始化,只需要運行 ./sbin/start-dfs.sh 就可以!
啟動 NameNode 和 DataNode
$ ./sbin/start-dfs.sh
15/12/23 11:37:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-hadoop-namenode-ocean-lab.ocean.org.out
localhost: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-hadoop-datanode-ocean-lab.ocean.org.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is a5:26:42:a0:5f:da:a2:88:52:04:9c:7f:8d:6a:98:9b.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-hadoop-secondarynamenode-ocean-lab.ocean.org.out
15/12/23 11:37:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[13:57:08][hadoop@ocean-lab hadoop-2.6.0]$ jps
27686 SecondaryNameNode
28455 Jps
27501 DataNode
27405 NameNode
27006 GetConf
如果沒有進程則說明啟動失敗 查看日志bebug
成功啟動后,可以訪問 Web 界面 http://[ip,fqdn]:/50070 查看 NameNode 和 Datanode 信息,還可以在線查看 HDFS 中的文件。
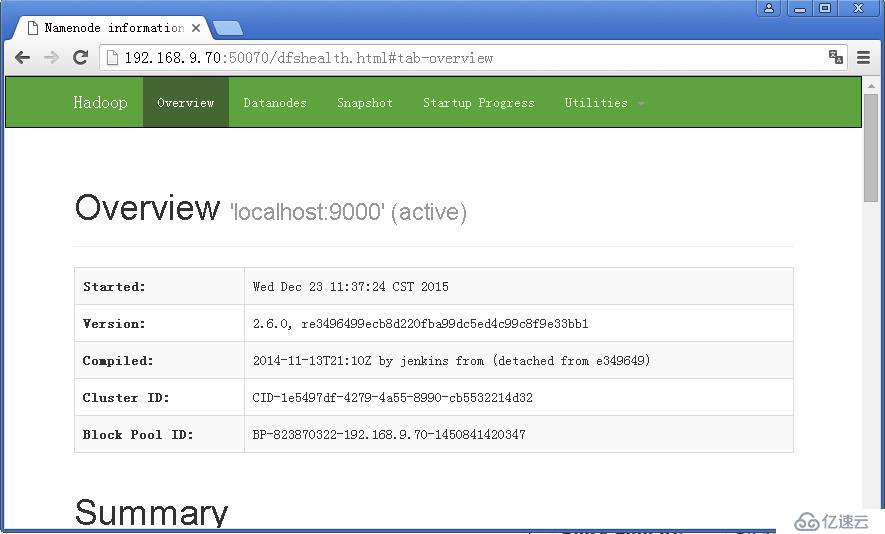
上面的單機模式,grep 例子讀取的是本地數據,偽分布式讀取的則是 HDFS 上的數據。
要使用 HDFS,首先需要在 HDFS 中創建用戶目錄:
# ./bin/hdfs dfs -mkdir -p /user/hadoop
# ./bin/hadoop fs -ls /user/hadoop
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2015-12-23 15:03 /user/hadoop/input
接著將 ./etc/hadoop 中的 xml 文件作為輸入文件復制到分布式文件系統中,即將 /usr/local/hadoop/etc/hadoop 復制到分布式文件系統中的 /user/hadoop/input 中。我們使用的是 hadoop 用戶,并且已創建相應的用戶目錄 /user/hadoop ,因此在命令中就可以使用相對路徑如 input,其對應的絕對路徑就是 /user/hadoop/input:
# ./bin/hdfs dfs -mkdir input
# ./bin/hdfs dfs -put ./etc/hadoop/*.xml input
復制完成后,可以通過如下命令查看 HDFS 中的文件列表:
# ./bin/hdfs dfs -ls input
-rw-r--r-- 1 hadoop supergroup 4436 2015-12-23 16:46 input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 1180 2015-12-23 16:46 input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 9683 2015-12-23 16:46 input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 1136 2015-12-23 16:46 input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2015-12-23 16:46 input/httpfs-site.xml
-rw-r--r-- 1 hadoop supergroup 3523 2015-12-23 16:46 input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 5511 2015-12-23 16:46 input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 858 2015-12-23 16:46 input/mapred-site.xml
-rw-r--r-- 1 hadoop supergroup 690 2015-12-23 16:46 input/yarn-site.xml
偽分布式運行 MapReduce 作業的方式跟單機模式相同,區別在于偽分布式讀取的是HDFS中的文件(可以將單機步驟中創建的本地 input 文件夾,輸出結果 output 文件夾都刪掉來驗證這一點)。
# ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
查看運行結果的命令(查看的是位于 HDFS 中的輸出結果):
$ ./bin/hdfs dfs -cat output/*
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
結果如下,注意到剛才我們已經更改了配置文件,所以運行結果不同。
Hadoop偽分布式運行grep的結果Hadoop偽分布式運行grep的結果
我們也可以將運行結果取回到本地:
# rm -r ./output # 先刪除本地的 output 文件夾(如果存在)
# ./bin/hdfs dfs -get output ./output # 將 HDFS 上的 output 文件夾拷貝到本機
# cat ./output/*
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
Hadoop 運行程序時,輸出目錄不能存在,否則會提示錯誤 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次執行,需要執行如下命令刪除 output 文件夾:
# 刪除 output 文件夾
$./bin/hdfs dfs -rm -r output
Deleted output
運行程序時,輸出目錄不能存在
運行 Hadoop 程序時,為了防止覆蓋結果,程序指定的輸出目錄(如 output)不能存在,否則會提示錯誤,因此運行前需要先刪除輸出目錄。在實際開發應用程序時,可考慮在程序中加上如下代碼,能在每次運行時自動刪除輸出目錄,避免繁瑣的命令行操作:
Configuration conf = new Configuration();
Job job = new Job(conf);
/* 刪除輸出目錄 */
Path outputPath = new Path(args[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
若要關閉 Hadoop,則運行
./sbin/stop-dfs.sh
啟動YARN
(偽分布式不啟動 YARN 也可以,一般不會影響程序執行)
有的讀者可能會疑惑,怎么啟動 Hadoop 后,見不到書上所說的 JobTracker 和 TaskTracker,這是因為新版的 Hadoop 使用了新的 MapReduce 框架(MapReduce V2,也稱為 YARN,Yet Another Resource Negotiator)。
YARN 是從 MapReduce 中分離出來的,負責資源管理與任務調度。YARN 運行于 MapReduce 之上,提供了高可用性、高擴展性,YARN 的更多介紹在此不展開,有興趣的可查閱相關資料。
上述通過 ./sbin/start-dfs.sh 啟動 Hadoop,僅僅是啟動了 MapReduce 環境,我們可以啟動 YARN ,讓 YARN 來負責資源管理與任務調度。
首先修改配置文件 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
接著修改配置文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
然后就可以啟動 YARN 了(需要先執行過 ./sbin/start-dfs.sh):
# ./sbin/start-yarn.sh # 啟動YARN
# ./sbin/mr-jobhistory-daemon.sh start historyserver # 開啟歷史服務器,才能在Web中查看任務運行情況
開啟后通過 jps 查看,可以看到多了 NodeManager 和 ResourceManager 兩個后臺進程:
[09:18:34][hadoop@ocean-lab ~]$ jps
27686 SecondaryNameNode
6968 ResourceManager
7305 Jps
7066 NodeManager
27501 DataNode
27405 NameNode
啟動 YARN 之后,運行實例的方法還是一樣的,僅僅是資源管理方式、任務調度不同。觀察日志信息可以發現,不啟用 YARN 時,是 “mapred.LocalJobRunner” 在跑任務,啟用 YARN 之后,是 “mapred.YARNRunner” 在跑任務。啟動 YARN 有個好處是可以通過 Web 界面查看任務的運行情況:http://[ip,fqdn]:8088/cluster
開啟YARN后可以查看任務運行信息開啟YARN后可以查看任務運行信息
但 YARN 主要是為集群提供更好的資源管理與任務調度,然而這在單機上體現不出價值,反而會使程序跑得稍慢些。因此在單機上是否開啟 YARN 就看實際情況了。
不啟動 YARN 需刪掉/重命名 mapred-site.xml
否則在該配置文件存在,而未開啟 YARN 的情況下,運行程序會提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032″ 的錯誤。
同樣的,關閉 YARN 的腳本如下:
# ./sbin/stop-yarn.sh
# ./sbin/mr-jobhistory-daemon.sh stop historyserver
hadoop 常用命令
# 查看HDFS文件列表
hadoop fs -ls /usr/local/log/
# 創建文件目錄
hadoop fs -mkdir /usr/local/log/test
# 刪除文件
/hadoop fs -rm /usr/local/log/07
# 上傳一個本機文件到HDFS中/usr/local/log/目錄下
adoop fs -put /usr/local/src/infobright-4.0.6-0-x86_64-ice.rpm /usr/local/log/
# 下載
hadoop fs –get /usr/local/log/infobright-4.0.6-0-x86_64-ice.rpm /usr/local/src/
# 查看文件
hadoop fs -cat /usr/local/log/zabbix/access.log.zabbix
# 查看HDFS基本使用情況
# hadoop dfsadmin -report
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Configured Capacity: 29565767680 (27.54 GB)
Present Capacity: 17956433920 (16.72 GB)
DFS Remaining: 17956405248 (16.72 GB)
DFS Used: 28672 (28 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 127.0.0.1:50010 (localhost)
Hostname: ocean-lab.ocean.org
Decommission Status : Normal
Configured Capacity: 29565767680 (27.54 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 11609333760 (10.81 GB)
DFS Remaining: 17956405248 (16.72 GB)
DFS Used%: 0.00%
DFS Remaining%: 60.73%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Dec 24 09:52:14 CST 2015
自此,你已經掌握 Hadoop 的配置和基本使用了。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





