溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“CentOS中如何搭建Hadoop”,內容詳細,步驟清晰,細節處理妥當,希望這篇“CentOS中如何搭建Hadoop”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
軟件環境:
虛擬機:vmware pro14
linux:centos-6.4(,下載dvd版本即可)
jdk:openjdk1.8.0 (強力建議不要使用 oracle 公司的 linux 版本的 jdk)
hadoop:2.6.5()
虛擬機的安裝和linux系統的安裝這里就省略了,可以參照網上的教程安裝,一般沒什么大問題,需要注意的是記住這里你輸入的用戶密碼,下面還要用,如下圖所示。
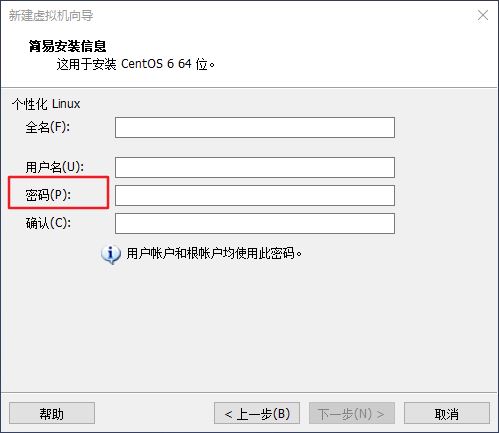
設置用戶密碼.jpg
用戶選擇
使用虛擬機安裝好系統后,可以看到登錄界面,如下圖所示。
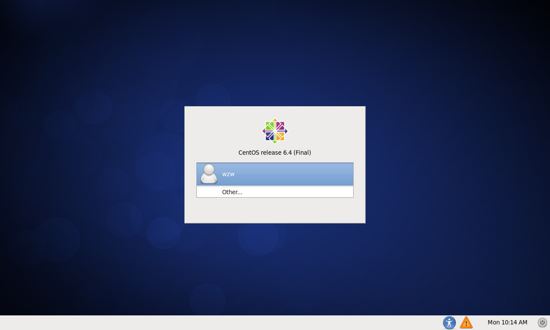
選擇 other ,在 username 輸入框中輸入 root ,回車,再在 password 輸入框中輸入你創建用戶時密碼。root 用戶是安裝 centos 自動創建的超級用戶,但密碼和你安裝系統時創建的普通用戶密碼是一樣的。
平時在使用 centos 時,并不推薦使用 root 用戶,因為該用戶具有整個系統的最高權限,使用該用戶可能會導致嚴重的后果,但前提是你對 linux 很熟,才會誤操作。搭建 hadoop 的大數據平臺,使用普通用戶,很多命令需要 sudo 命令來獲取 root 用戶的權限,比較麻煩,所以索性直接使用 root 用戶。
安裝ssh
集群、單節點模式都需要用到 ssh 登陸(類似于遠程登陸,你可以登錄某臺 linux 主機,并且在上面運行命令)。
首先確保你的 centos 系統可以正常的上網,你可以查看桌面右上角的網絡圖標,若顯示紅叉則表明未聯網,可點擊選擇可用網絡,也可以使用桌面左上角的火狐瀏覽器輸入網址驗證是否網絡連接正常。如果還是無法上網,檢查虛擬機的設置,選用 nat 模式,或者上網百度解決。
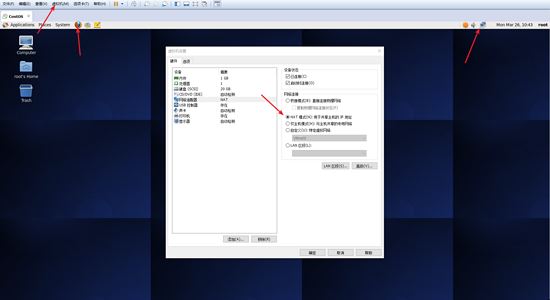
檢查網絡狀況.jpg
確定網絡連接正常后,打開 centos 的終端,可在 centos 的桌面點擊鼠標右鍵,選擇 open in terminal ,如下圖所示。
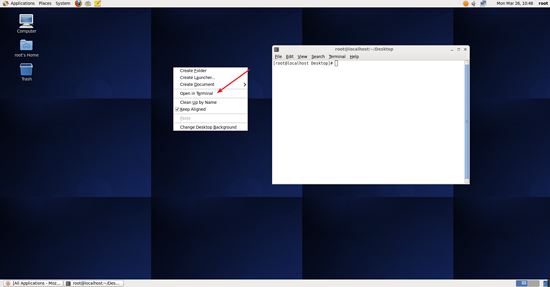
打開終端.jpg
一般情況下,centos 默認已安裝了 ssh client、ssh server,可打開終端執行如下命令進行檢驗:
rpm -qa | grep ssh
如果返回的結果如下圖所示,包含了 ssh client 跟 ssh server,則不需要再安裝。
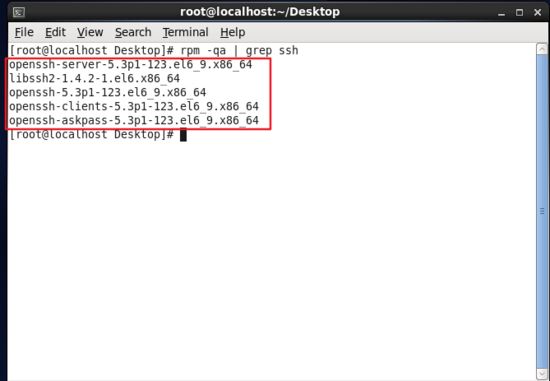
查看ssh是否已安裝.jpg
如果需要安裝,則可以通過 yum 這個包管理器進行安裝。(安裝過程中會讓你輸入 [y/n],輸入 y 即可)
注意:命令是單條執行的,不是直接把兩條命令粘貼過去。
終端中的粘貼可通過鼠標點擊右鍵選擇 paste 粘貼,也可通過快捷鍵 【shift + insert】粘貼。
yum install openssh-clients yum install openssh-server
ssh安裝完成后,執行如下命令測試一下 ssh 是否可用(ssh首次登陸提示 yes/no 信息,輸入 yes 即可,然后按照提示輸入 root 用戶的密碼,這樣就登錄到本機了),如下圖所示。

首次登錄ssh.jpg
但這樣登陸需要每次都輸入密碼,我們需要配置成ssh無密碼登陸比較方便。
首先輸入 exit 退出剛才的 ssh,就回到了我們原先的終端窗口,然后利用 ssh-keygen 生成密鑰,并將密鑰加入到授權中。
exit # 退出剛才的 ssh localhost cd ~/.ssh/ # 若提示沒有該目錄,請先執行一次ssh localhost ssh-keygen -t rsa # 會有提示,都按回車即可 cat id_rsa.pub >> authorized_keys # 加入授權 chmod 600 ./authorized_keys # 修改文件權限
此時再用 ssh localhost 命令,無需輸入密碼就可以直接登陸了,如下圖所示。
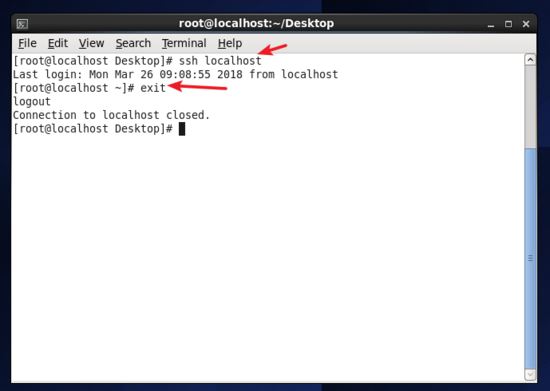
再次登錄ssh.jpg
安裝 java 環境
java 環境可選擇 oracle 的 jdk,或是 openjdk(可看作 jdk 的開源版本),現在一般 linux 系統默認安裝的基本是 openjdk,這里安裝的是 openjdk1.8.0版本的。
有的 centos 6.4 默認安裝了 openjdk 1.7,這里我們可以使用命令檢查一下,和 windows 下的命令一樣,還可以查看 java_home 這個環境變量的值。
java -version # 查看 java 的版本 javac -version # 查看編譯命令 javac 的版本 echo $java_home # 查看 $java_home 這個環境變量的值
如果系統沒有安裝 openjdk,我們可以通過 yum 包管理器來安裝。(安裝過程中會讓輸入 [y/n],輸入 y 即可)
復制代碼 代碼如下:
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel #安裝 openjdk1.8.0
通過上述命令安裝 openjdk,默認安裝位置為 /usr/lib/jvm/java-1.8.0,下面配置 java_home 時就使用這個位置。
接著需要配置一下 java_home 環境變量,為了方便,直接在 ~/.bashrc 中進行設置,相當于配置的是 windows 的用戶環境變量,只對單個用戶生效,當用戶登錄后,每次打開 shell 終端,.bashrc 文件都會被讀取。
修改文件,可以直接使用 vim 編輯器打開文件,也可以使用類似于 windows 記事本的 gedit 文本編輯器。
下面命令任選其一。
vim ~/.bashrc # 使用 vim 編輯器在終端中打開 .bashrc 文件 gedit ~/.bashrc # 使用 gedit 文本編輯器打開 .bashrc 文件
在文件最后面添加如下單獨一行(指向 jdk 的安裝位置),并 保存 。
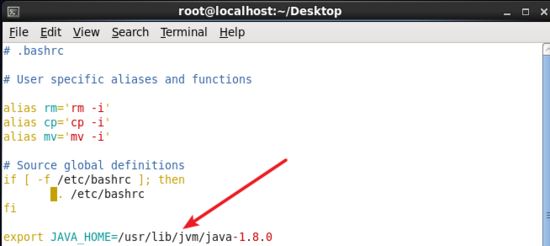
配置java_home環境變量.jpg
接著還需要讓該環境變量生效,執行如下命令。
source ~/.bashrc # 使變量設置生效
設置好后我們來檢驗一下是否設置正確,如下圖所示。
echo $java_home # 檢驗變量值 java -version javac -version $java_home/bin/java -version # 與直接執行 java -version 一樣
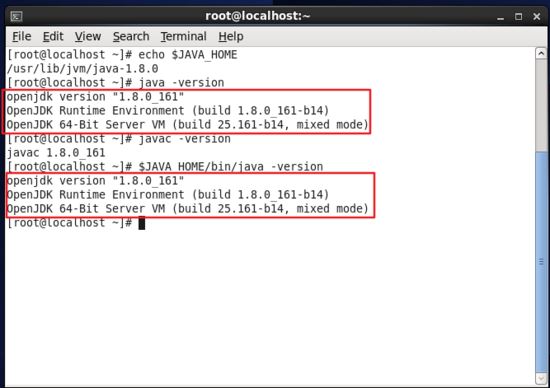
檢查java_home環境變量是否配置正確.jpg
這樣,hadoop 所需的 java 運行環境就安裝好了。
安裝 hadoop
在前面 軟件環境 已經給出了 hadoop2.6.5 的下載地址,可以直接通過火狐瀏覽器打開下載,默認下載位置是在用戶的 home 中的 downloads 文件夾下,如下圖所示。

下載hadoop.jpg
下載完成后,我們將 hadoop 解壓到 /usr/local/ 中。
tar -zxf ~/下載/hadoop-2.6.5.tar.gz -c /usr/local # 解壓到/usr/local目錄中 cd /usr/local/ # 切換當前目錄為 /usr/local 目錄 mv ./hadoop-2.6.5/ ./hadoop # 將文件夾名改為hadoop chown -r root:root ./hadoop # 修改文件權限,root 是當前用戶名
hadoop 解壓后即可使用,輸入如下命令來檢查 hadoop 是否可用,成功則會顯示 hadoop 版本信息。
cd /usr/local/hadoop # 切換當前目錄為 /usr/local/hadoop 目錄 ./bin/hadoop version # 查看 hadoop 的版本信息
或者直接輸入 hadoop version 命令也可以查看。
hadoop version # 查看 hadoop 的版本信息
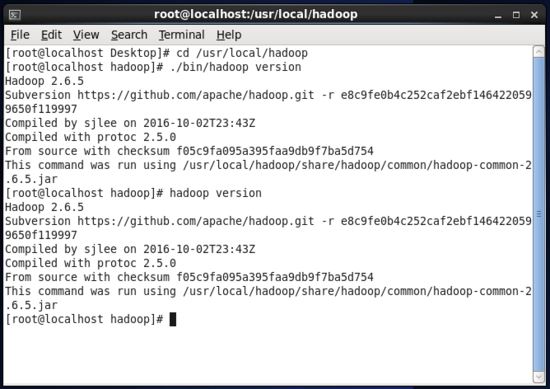
查看hadoop版本信息.jpg
hadoop 安裝方式有三種,分別是單機模式,偽分布式模式,分布式模式。
單機模式:hadoop 默認模式為非分布式模式(本地模式),無需進行其他配置即可運行。非分布式即單 java 進程,方便進行調試。
偽分布式模式:hadoop 可以在單節點上以偽分布式的方式運行,hadoop 進程以分離的 java 進程來運行,節點既作為 namenode 也作為 datanode,同時,讀取的是 hdfs 中的文件。
分布式模式:使用多個節點構成集群環境來運行hadoop,需要多臺主機,也可以是虛擬主機。
hadoop 偽分布式配置
現在我們就可以來使用 hadoop 運行一些例子,hadoop 附帶了很多的例子,可以運行 hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar 看到所有的例子。
我們這里來運行一個查詢的例子,將 input 文件夾作為輸入文件夾,篩選當中符合正則表達式 dfs[a-z.]+ 的單詞,統計它的次數,將篩選結果輸出到 output 文件夾中。
cd /usr/local/hadoop # 切換當前目錄為 /usr/local/hadoop 目錄 mkdir ./input # 在當前目錄下創建 input 文件夾 cp ./etc/hadoop/*.xml ./input # 將 hadoop 的配置文件復制到新建的輸入文件夾 input 中 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+' cat ./output/* # 查看輸出結果
通過命令 cat ./output/* 查看結果,符合正則的單詞 dfsadmin 出現了 1次。
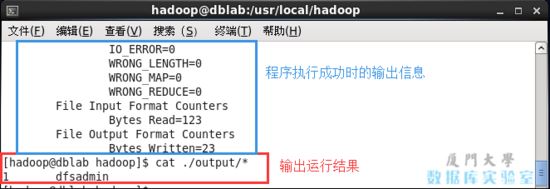
運行測試hadoop例子.jpg
若運行出錯,如出現如下圖提示。
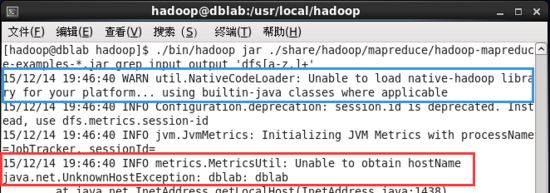
運行hadoop例子出錯.jpg
若出現提示 “warn util.nativecodeloader: unable to load native-hadoop library for your platform… using builtin-java classes where applicable”,該 warn 提示可以忽略,不影響 hadoop 正常運行。
注意:hadoop 默認不會覆蓋結果文件,因此再次運行上面實例會提示出錯,需要先將 output 文件夾刪除。
rm -rf ./output # 在 /usr/local/hadoop 目錄下執行
測試我們的 hadoop 安裝沒有問題,我們可以開始設置 hadoop 的環境變量,同樣在 ~/.bashrc 文件中配置。
gedit ~/.bashrc # 使用 gedit 文本編輯器打開 .bashrc 文件
在 .bashrc 文件最后面增加如下內容,注意 hadoop_home 的位置對不對,如果都是按照前面的配置,這部分可照抄。
# hadoop environment variables export hadoop_home=/usr/local/hadoop export hadoop_install=$hadoop_home export hadoop_mapred_home=$hadoop_home export hadoop_common_home=$hadoop_home export hadoop_hdfs_home=$hadoop_home export yarn_home=$hadoop_home export hadoop_common_lib_native_dir=$hadoop_home/lib/native export path=$path:$hadoop_home/sbin:$hadoop_home/bin
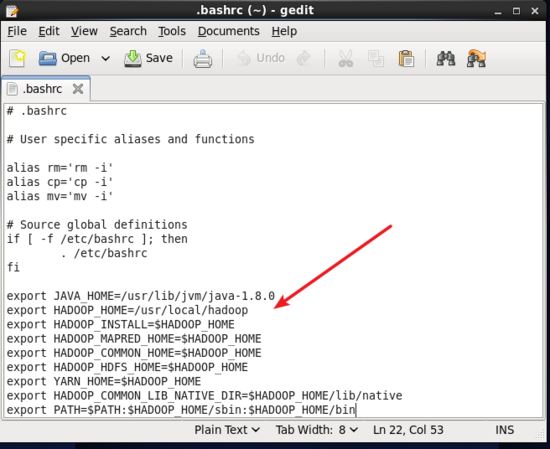
hadoop環境變量的配置.jpg
保存后記得關掉 gedit 程序,否則會占用終端,無法執行下面的命令,可以按 【ctrl + c】鍵終止該程序。
保存后,不要忘記執行如下命令使配置生效。
source ~/.bashrc
hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 下,偽分布式需要修改2個配置文件 core-site.xml 和 hdfs-site.xml 。hadoop的配置文件是 xml 格式,每個配置以聲明 property 的 name 和 value 的方式來實現。
修改配置文件 core-site.xml (通過 gedit 編輯會比較方便,輸入命令, gedit ./etc/hadoop/core-site.xml )。
在 <configuration></configuration> 中間插入如下的代碼。
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>abase for other temporary directories.</description> </property> <property> <name>fs.defaultfs</name> <value>hdfs://localhost:9000</value> </property> </configuration>
同樣的,修改配置文件 hdfs-site.xml , gedit ./etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
配置完成后,執行 namenode 的格式化。(hadoop 首次啟動需要該命令)
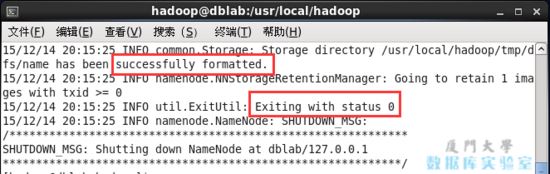
hdfs namenode -format
成功的話,會看到 “successfully formatted” 和 “exitting with status 0” 的提示,若為 “exitting with status 1” 則是出錯。
namenode格式化.jpg
接下來啟動 hadoop。
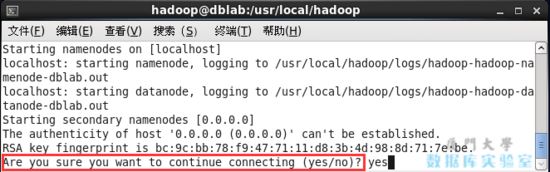
start-dfs.sh # 開啟 namenode 和 datanode 進程
若出現如下 ssh 的提示 “are you sure you want to continue connecting”,輸入 yes 即可。
啟動hadoop注意事項.jpg
啟動完成后,可以通過命令 jps 來判斷是否成功啟動,若出現下面 namenode、datanode、secondarynamenode、jps 四個進程,則 hadoop 啟動成功。
jps # 查看進程判斷 hadoop 是否啟動成功

判斷hadoop是否啟動成功.jpg
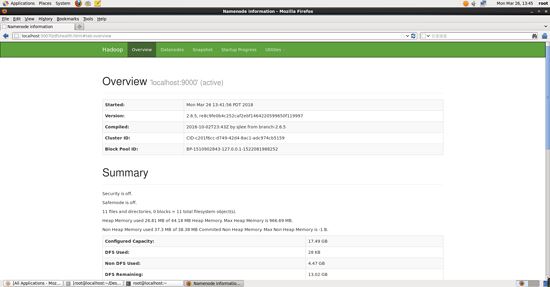
成功啟動后,也可以訪問 web 界面 http://localhost:50070 查看 namenode 和 datanode 信息,還可以在線查看 hdfs 中的文件。
hadoop正常啟動web界面.jpg
啟動yarn
yarn 是從 mapreduce 中分離出來的,負責資源管理與任務調度。yarn 運行于 mapreduce 之上,提供了高可用性、高擴展性。(偽分布式不啟動 yarn 也可以,一般不會影響程序執行)
上述通過 start-dfs.sh 命令啟動 hadoop,僅僅是啟動了 mapreduce 環境,我們可以啟動 yarn ,讓 yarn 來負責資源管理與任務調度。
首先修改配置文件 mapred-site.xml ,需要先將 mapred-site.xml.template 文件的重命名為 mapred-site.xml。
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml # 文件重命名 gedit ./etc/hadoop/mapred-site.xml # 用gedit 文本編輯器打開
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
接著修改配置文件 yarn-site.xml 。
gedit ./etc/hadoop/yarn-site.xml # 用gedit 文本編輯器打開
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
然后就可以啟動 yarn 了,執行 start-yarn.sh 命令。
注意:在啟動 yarn 之前,要確保 dfs hadoop 已經啟動,也就是執行過 start-dfs.sh 。
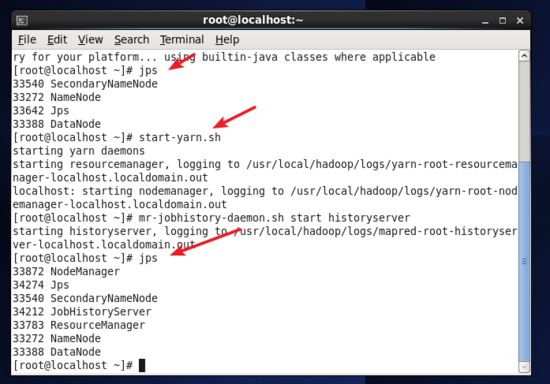
start-yarn.sh # 啟動yarn mr-jobhistory-daemon.sh start historyserver # 開啟歷史服務器,才能在web中查看任務運行情況
開啟后通過 jps 查看,可以看到多了 nodemanager 和 resourcemanager 兩個進程,如下圖所示。
啟動yarn.jpg
啟動 yarn 之后,運行實例的方法還是一樣的,僅僅是資源管理方式、任務調度不同。啟動 yarn 有個好處是可以通過 web 界面查看任務的運行情況: http://localhost:8088/cluster 如下圖所示。
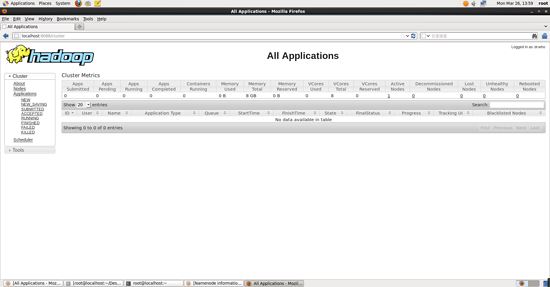
yarn的web界面.jpg
yarn 主要是為集群提供更好的資源管理與任務調度,如果不想啟動 yarn,務必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用時改回來就行。否則在該配置文件存在,而未開啟 yarn 的情況下,運行程序會提示 “retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的錯誤,這也是為何該配置文件初始文件名為 mapred-site.xml.template。
關閉 yarn 的命令如下,開啟是 start,關閉是 stop。
stop-yarn.sh mr-jobhistory-daemon.sh stop historyserver
讀到這里,這篇“CentOS中如何搭建Hadoop”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





