溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹MySQL中分類排名和分組TOP N的示例分析,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
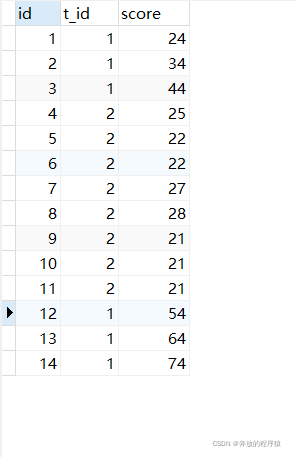
學生表如下:
CREATE TABLE `t_student` ( `id` int NOT NULL AUTO_INCREMENT, `t_id` int DEFAULT NULL COMMENT '學科id', `score` int DEFAULT NULL COMMENT '分數', PRIMARY KEY (`id`) );
數據如下:
允許并列情況可能存在如4、5名成績并列情況,會導致取前4名得出5條數據,取前5名也是5條數據。
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5 ORDER BY s1.t_id, s1.score DESC
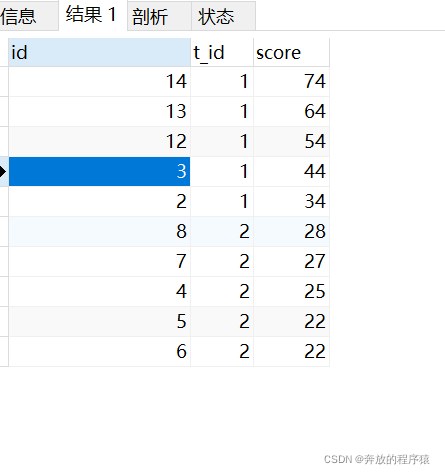
ps:取前4名時
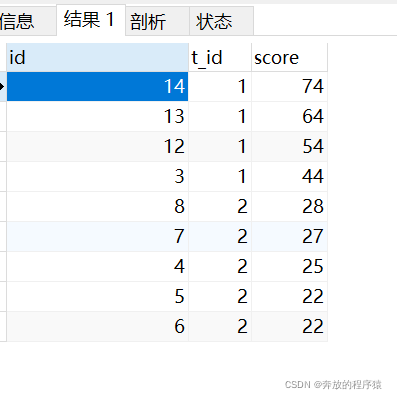
1.自身左外連接,得到所有的左邊值小于右邊值的集合。以t_id=1時舉例,24有5個成績大于他的(74、64、54、44、34),是第6名,34只有4個成績大于他的,是第5名......74沒有大于他的,是第一名。
SELECT * FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score
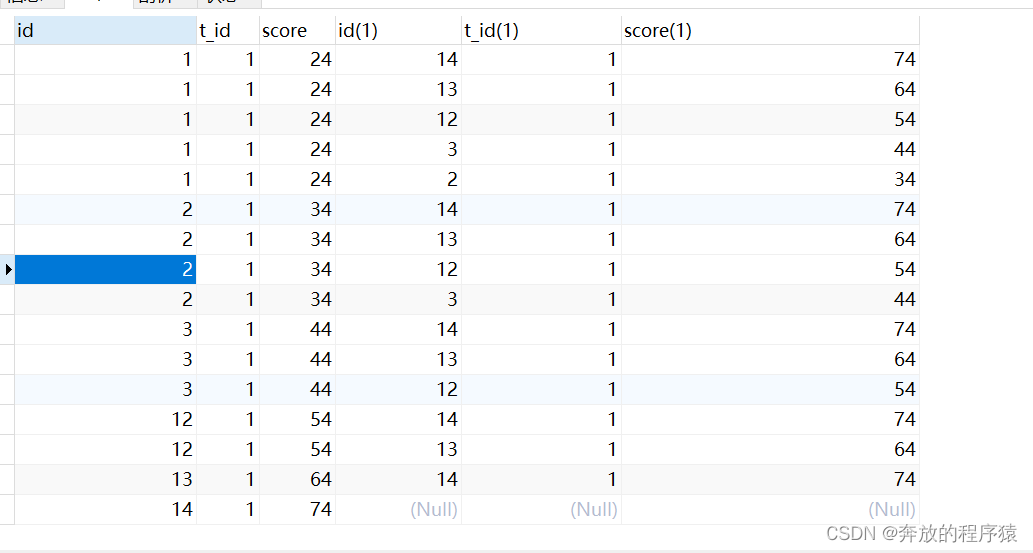
2. 把總結的規律轉換成SQL表示出來,就是group by 每個student 的 id(s1.id),Having統計這個id下面有多少個比他大的值(s2.id)
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5
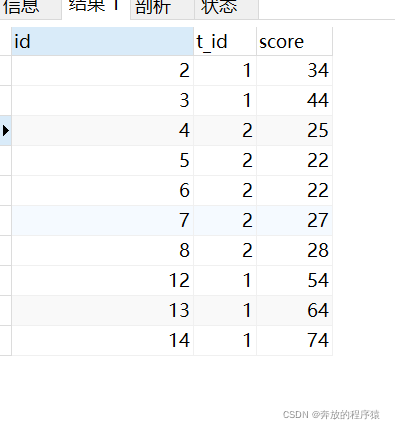
3. 最后根據 t_id 分類,score 倒序排序即可。
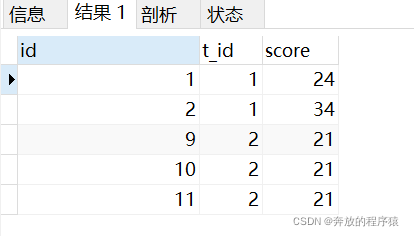
取最后兩名成績
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score
并列存在情況下可能導致篩選出的同一t_id 下結果條數大于2條,但題目要求是取最后兩名的平均值,多條平均后還是本身,故不必再對其處理,可以滿足題目要求。
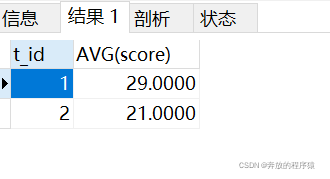
分組求平均值:
SELECT t_id,AVG(score) FROM ( SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score ) tt GROUP BY t_id
結果:
1. 查詢出所有t1.score>t2.score 的記錄
SELECT s1.*,s2.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score
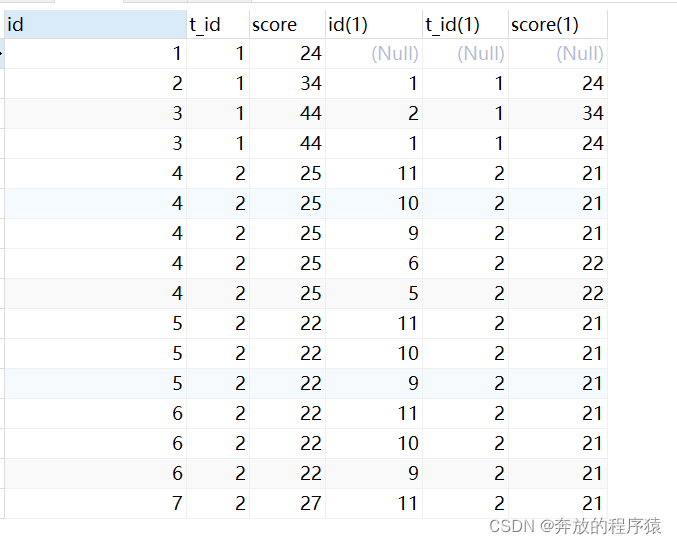
2. group by s.id 去重,having 計數取2條
3. group by t_id 分別取各自學科的然后avg取均值
SELECT * FROM ( SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it GROUP BY s1.id ORDER BY s1.t_id, s1.score DESC ) tt GROUP BY t_id, score, rownum HAVING COUNT( rownum )< 5
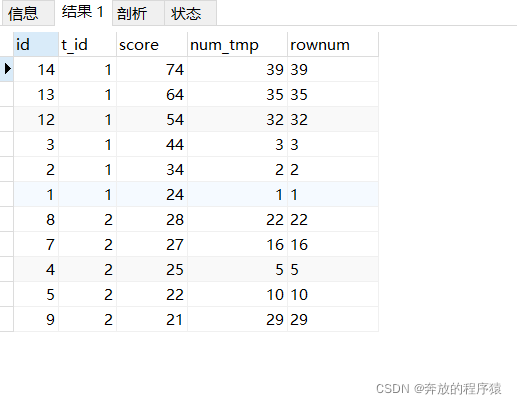
1.引入輔助參數
SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it
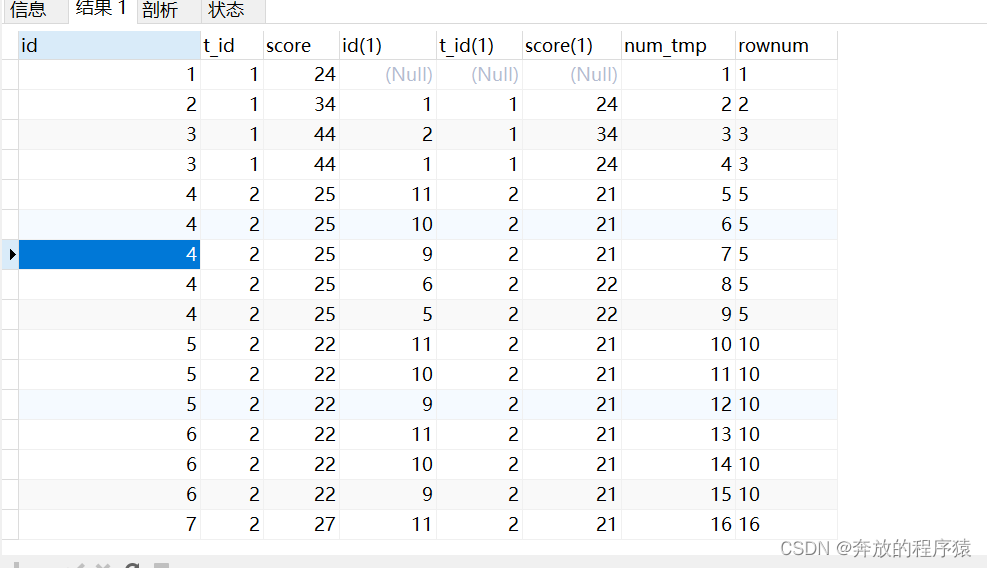
2.去除重復s1.id,分組排序
SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it GROUP BY s1.id ORDER BY s1.t_id, s1.score DESC
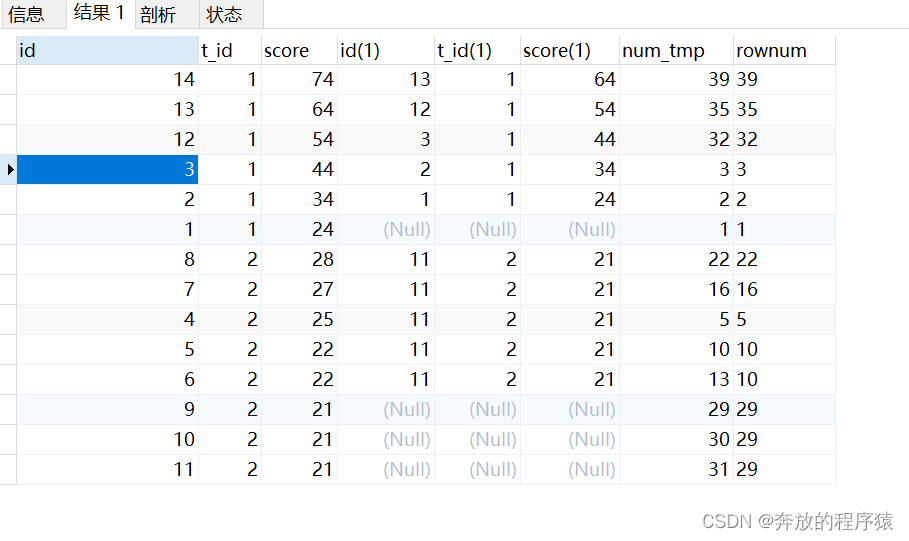
3.GROUP BY t_id, score, rownum 然后 HAVING 取前5條不重復的
以上是“MySQL中分類排名和分組TOP N的示例分析”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





