溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹MySQL中怎么實現排序和分組,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
order by和group by這兩個要十分注意,因為一不小心就會產生文件內排序,即file sort,這個性能是十分差的。下面來看具體的案例分析。
首先建表:
create table `tblA`(
`id` int not null primary key auto_increment comment '主鍵',
`age` int not null comment '年齡',
`birth` timestamp not null comment '生日'
) ;
insert into tblA(age, birth) values(22, now());
insert into tblA(age, birth) values(23, now());
insert into tblA(age, birth) values(24, now());
create index idx_age_birth on tblA(age, birth);
1. order by:
看看下面語句的執行計劃:
explain select * from tblA where age > 20 order by age;
explain select * from tblA where age > 20 order by age,birth;
這兩個個毫無疑問,可以用到索引。
再來看看這個:
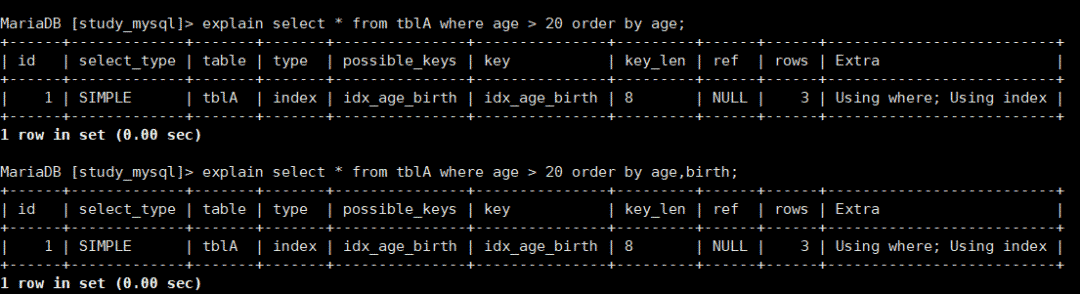
explain select * from tblA where age > 20 order by birth;

顯然我們可以看到這里產生了filesort,為什么呢?因為age是范圍,且order by的直接是二樓,帶頭大哥沒了,所以索引失效了。
那這樣呢?
explain select * from tblA where age > 20 order by birth, age;
explain select * from tblA where age > 20 order by age, birth;
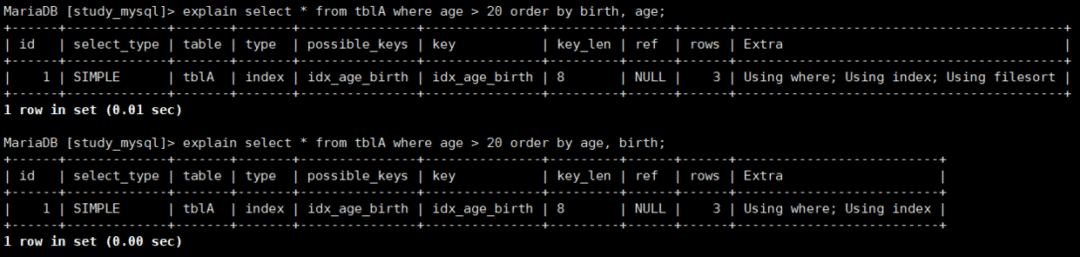
第一個還是不行,因為范圍后失效,且order by是從birth二樓開始的。第二個可以用到索引,不會產生filesort,是因為,雖然前面的age是范圍,但是order by的又是從age開始,帶頭大哥在。
上面這些都好理解,看看這個:
explain select * from tblA order by age desc, birth asc;

奇了怪了,帶頭大哥在,也沒有范圍,為啥就出現了filesort了呢?
這是因為age是降序,birth又是升序,一升一降,就會導致索引用不上,就會產生filesort了。如果把兩個都改成desc或者asc,那就沒問題了。
注意:
MySQL的filesort有兩種策略,
MySQL4.1之前,叫雙路排序。
就是會進行兩次磁盤I/O操作。讀取行指針和order by的列,
對它們排序,然后掃描排好序的表,再從磁盤中取出數據來。
4.1之后的版本,叫單路排序,只進行一次I/O。
先將數據從磁盤讀到內存中,然后在內存中排序。
但是,如果內存,即sort_buffer_size不夠大,性能反而不如雙路排序。
order by優化小總結:
select *;sort_buffer_size,不管用哪種算法,增大這個都可以提高效率;max_length_for_sort_data,增大這個,會增加用改進算法的概率。2. group by:
group by 其實和order by一樣,也是先排序,不過多了一個分組,也遵從最佳左前綴原則。要注意的一點是,where優于having,能用where時就不要用having。
關于MySQL中怎么實現排序和分組就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





