溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“python怎么使用Evidently創建機器學習模型儀表板”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“python怎么使用Evidently創建機器學習模型儀表板”吧!
解釋機器學習模型是一個困難的過程,因為通常大多數模型都是一個黑匣子,我們不知道模型內部發生了什么。創建不同類型的可視化有助于理解模型是如何執行的,但是很少有庫可以用來解釋模型是如何工作的。
Evidently 是一個開源 Python 庫,用于創建交互式可視化報告、儀表板和 JSON 配置文件,有助于在驗證和預測期間分析機器學習模型。它可以創建 6 種不同類型的報告,這些報告與數據漂移、分類或回歸的模型性能等有關。
使用 pip 軟件包管理器安裝,運行
$ pip install evidently
該工具允許在 Jupyter notebook 中以及作為單獨的HTML文件構建交互式報告。如果你只想將交互式報告生成為HTML文件或導出為JSON配置文件,則安裝現已完成。
為了能夠在 Jupyter notebook 中構建交互式報告,我們使用Jupyter nbextension。如果想在 Jupyter notebook 中創建報告,那么在安裝之后,您應該在 terminal 中運行以下兩個命令。
要安裝 jupyter Nbextion,請運行:
$ jupyter nbextension install --sys-prefix --symlink --overwrite --py evidently
運行
jupyter nbextension enable evidently --py --sys-prefix
有一點需要注意:安裝后單次運行就足夠了。無需每次都重復最后兩個命令。
在這一步中,我們將導入創建ML模型所需的庫。我們還將導入用于創建用于分析模型性能的儀表板的庫。此外,我們將導入 pandas 以加載數據集。
import pandas as pd import numpy as np from sklearn.ensemble import RandomForestRegressor from evidently.dashboard import Dashboard from evidently.tabs import RegressionPerformanceTab from evidently.model_profile import Profile from evidently.profile_sections import RegressionPerformanceProfileSection
在這一步中,我們將加載數據并將其分離為參考數據和預測數據。
raw_data = pd.read_csv('/content/day.csv', header = 0, sep = ',', parse_dates=['dteday'])
ref_data = raw_data[:120]
prod_data = raw_data[120:150]
ref_data.head()
在這一步中,我們將創建機器學習模型,對于這個特定的數據集,我們將使用隨機森林回歸模型。
target = 'cnt' datetime = 'dteday' numerical_features = ['mnth', 'temp', 'atemp', 'hum', 'windspeed'] categorical_features = ['season', 'holiday', 'weekday', 'workingday', 'weathersit',] features = numerical_features + categorical_features model = RandomForestRegressor(random_state = 0) model.fit(ref_data[features], ref_data[target]) ref_data['prediction'] = model.predict(ref_data[features]) prod_data['prediction'] = model.predict(prod_data[features])
在這一步中,我們將創建儀表板來解釋模型性能并分析模型的不同屬性,如 MAE、MAPE、誤差分布等。
column_mapping = {}
column_mapping['target'] = target
column_mapping['prediction'] = 'prediction'
column_mapping['datetime'] = datetime
column_mapping['numerical_features'] = numerical_features
column_mapping['categorical_features'] = categorical_features
dashboard = Dashboard(tabs=[RegressionPerformanceTab])
dashboard .calculate(ref_data, prod_data, column_mapping=column_mapping)
dashboard.save('bike_sharing_demand_model_perfomance.html')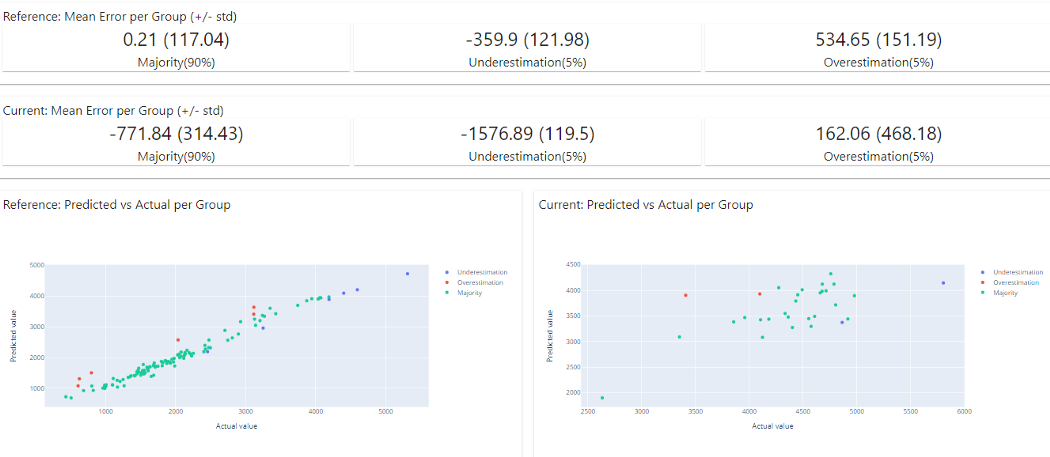
在上圖中,可以清楚地看到顯示模型性能的報告,可以使用上述代碼下載并創建的 HTML 報告。
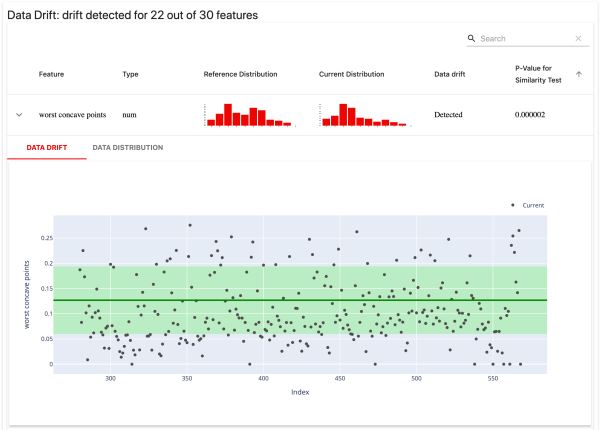
檢測特征分布的變化
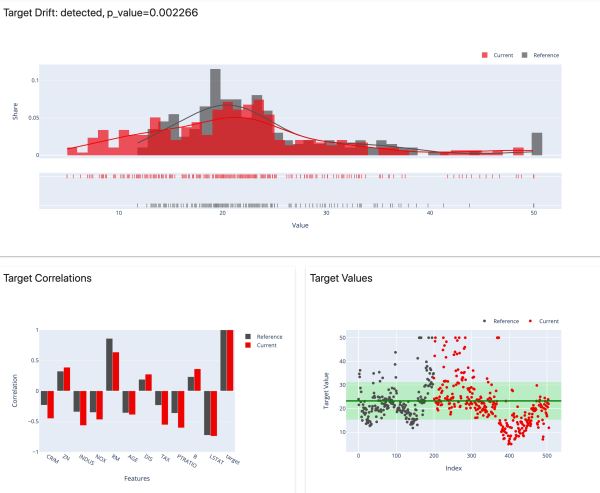
檢測數值目標和特征行為的變化。
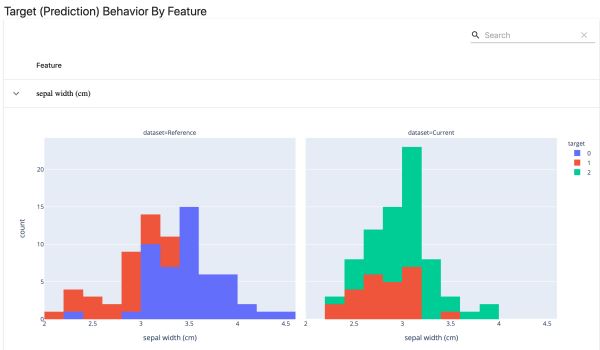
檢測分類目標和特征行為的變化
分析回歸模型的性能和模型誤差
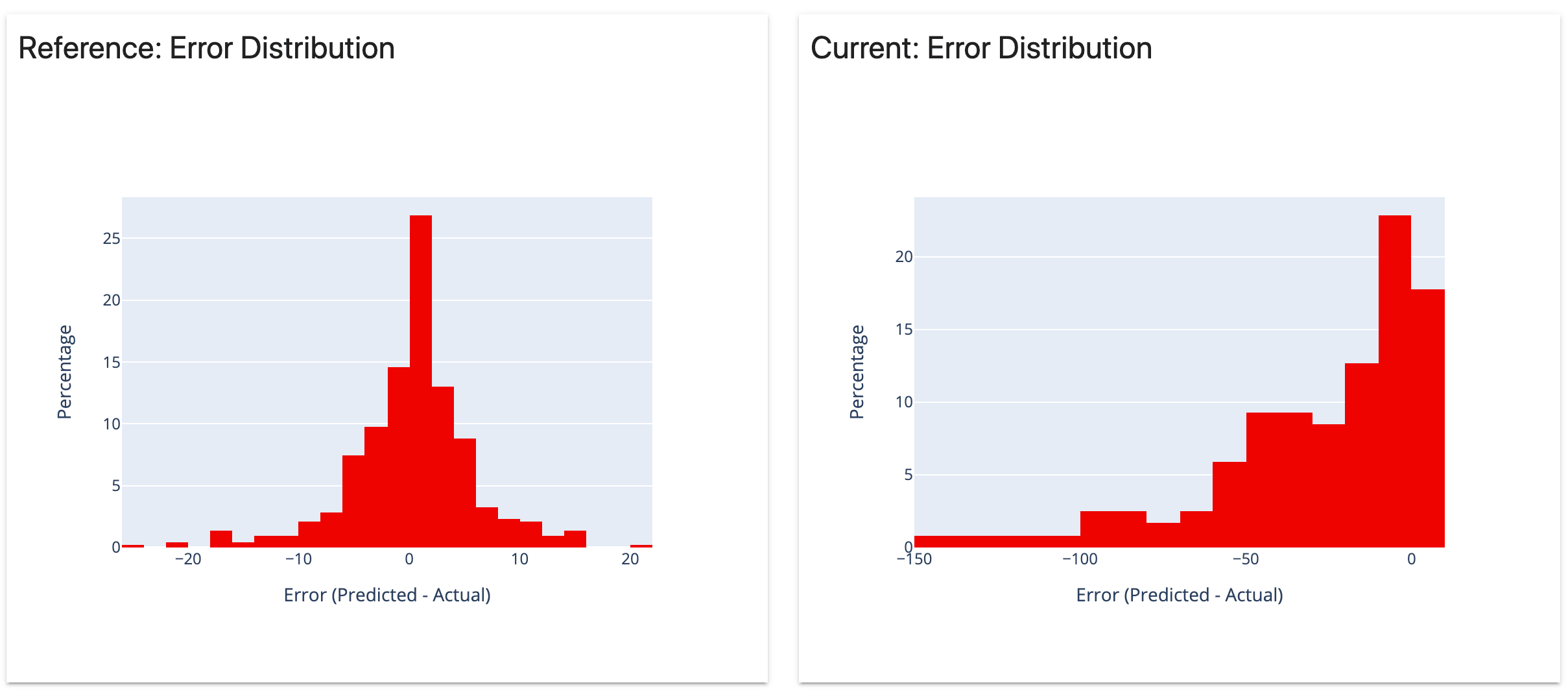
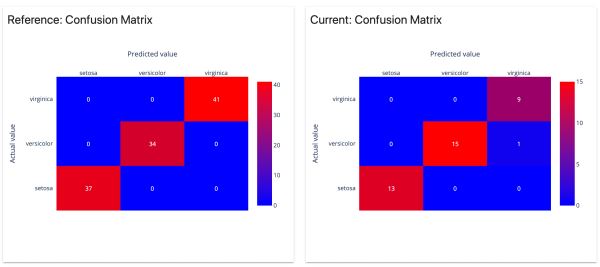
分析分類模型的性能和錯誤。適用于二元和多類模型
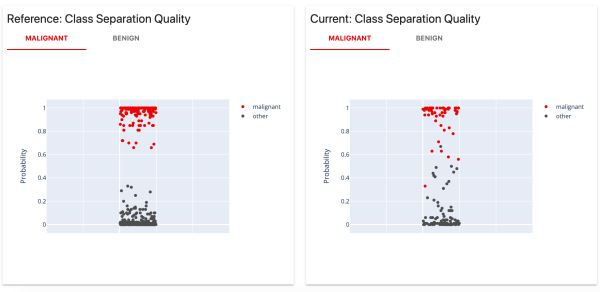
分析概率分類模型的性能、模型校準的質量和模型錯誤。適用于二元和多類模型。
感謝各位的閱讀,以上就是“python怎么使用Evidently創建機器學習模型儀表板”的內容了,經過本文的學習后,相信大家對python怎么使用Evidently創建機器學習模型儀表板這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





