溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Sharding-JDBC自動實現MySQL讀寫分離的示例代碼怎么編寫,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
在介紹Sharding-JDBC之前,有必要先介紹下Sharding-JDBC的大家族ShardingSphere。在介紹ShardingSphere之后,相信大家會對ShardingSphere的整體架構以及Sharding-JDBC扮演的角色會有更深的了解。
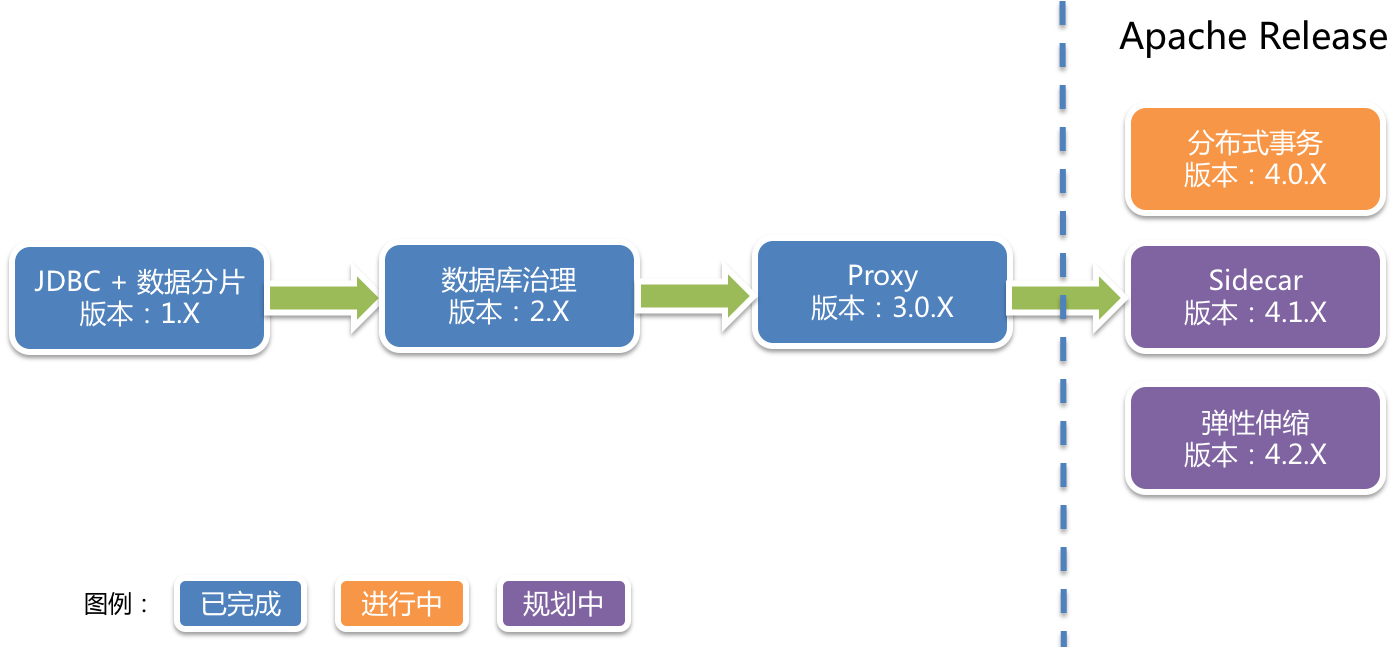
ShardingSphere是后來規劃的,最開始是只有 Sharding-JDBC 一款產品,基于客戶端形式的分庫分表。后面發展變成了現在的Apache ShardingSphere(Incubator) ,它是一套開源的分布式數據庫中間件解決方案組成的生態圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(規劃中)這3款相互獨立,卻又能夠混合部署配合使用的產品組成。它們均提供標準化的數據分片、分布式事務和數據庫治理功能,可適用于如Java同構、異構語言、容器、云原生等各種多樣化的應用場景。
ShardingSphere定位為關系型數據庫中間件,旨在充分合理地在分布式的場景下利用關系型數據庫的計算和存儲能力,而并非實現一個全新的關系型數據庫。 它與NoSQL和NewSQL是并存而非互斥的關系。NoSQL和NewSQL作為新技術探索的前沿,放眼未來,擁抱變化,是非常值得推薦的。反之,也可以用另一種思路看待問題,放眼未來,關注不變的東西,進而抓住事物本質。 關系型數據庫當今依然占有巨大市場,是各個公司核心業務的基石,未來也難于撼動,我們目前階段更加關注在原有基礎上的增量,而非顛覆。
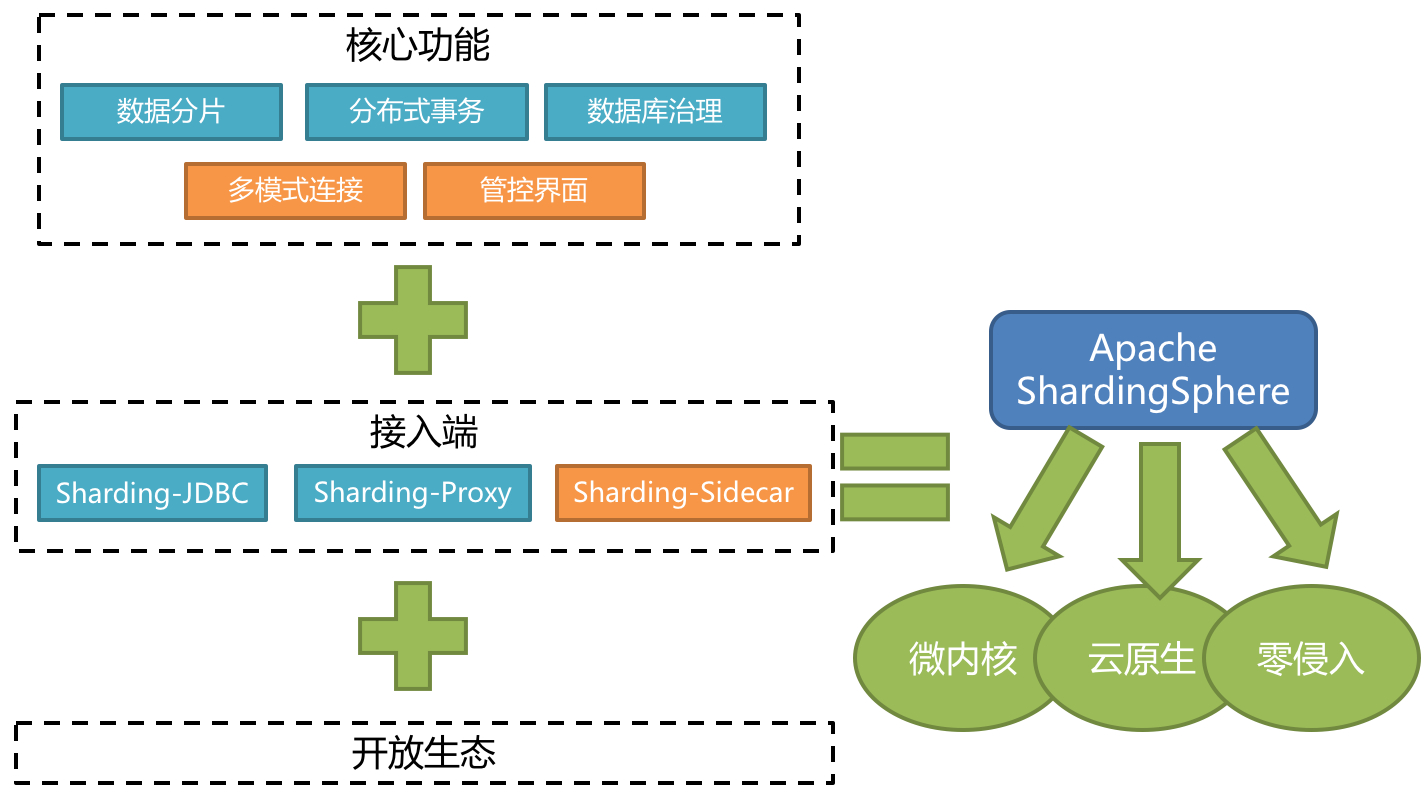
定位為輕量級Java框架,在Java的JDBC層提供的額外服務。 它使用客戶端直連數據庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強版的JDBC驅動,完全兼容JDBC和各種ORM框架。
適用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
基于任何第三方的數據庫連接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意實現JDBC規范的數據庫。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
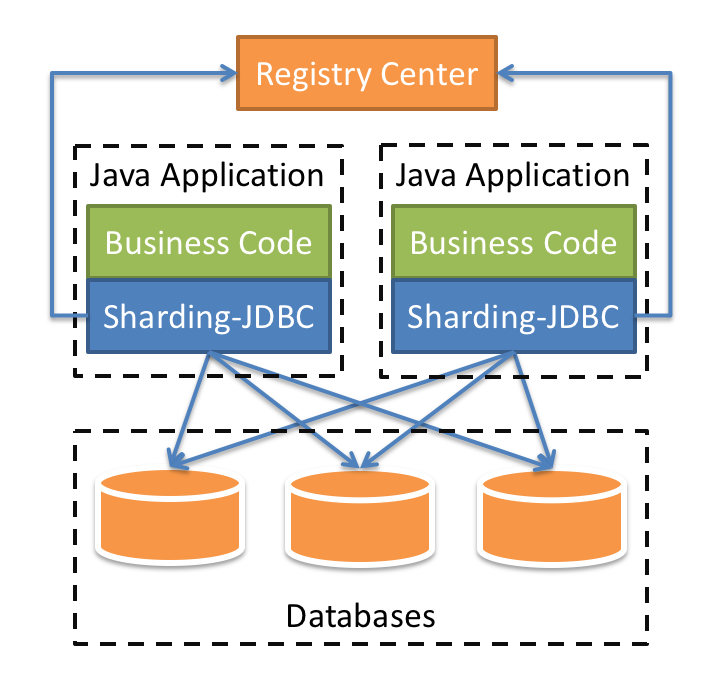

透明化讀寫分離所帶來的影響,讓使用方盡量像使用一個數據庫一樣使用主從數據庫,是讀寫分離數據庫中間件的主要功能。
數據庫中間件可以簡化對讀寫分離以及分庫分表的操作,并隱藏底層實現細節,可以像操作單庫單表那樣操作多庫多表,主流的設計方案主要有兩種:
服務端代理:需要獨立部署一個代理服務,該代理服務后面管理多個數據庫實例,在應用中通過一個數據源與該代理服務器建立連接,由該代理去操作底層數據庫,并返回相應結果。優點是支持多語言,對業務透明,缺點是實現復雜,實現難度大,同時代理需要確保自身高可用
客戶端代理:在連接池或數據庫驅動上進行一層封裝,內部與不同的數據庫建立連接,并對SQL進行必要的操作,比如讀寫分離選擇走主庫還是從庫,分庫分表select后如何聚合結果。優點是實現簡單,天然去中心化,缺點是支持語言較少,版本升級困難
一些常見的數據庫中間件如下:
Cobar:阿里開源的關系型數據庫分布式服務中間件,已停更
DRDS:脫胎于Cobar,全稱分布式關系型數據庫服務
MyCat:開源數據庫中間件,目前更新了MyCat2版本
Atlas:Qihoo 360公司Web平臺部基礎架構團隊開發維護的一個基于MySQL協議的數據中間層項目,同時還有一個NoSQL的版本,叫Pika
tddl:阿里巴巴自主研發的分布式數據庫服務
Sharding-JDBC:ShardingShpere的一個子產品,一個輕量級Java框架
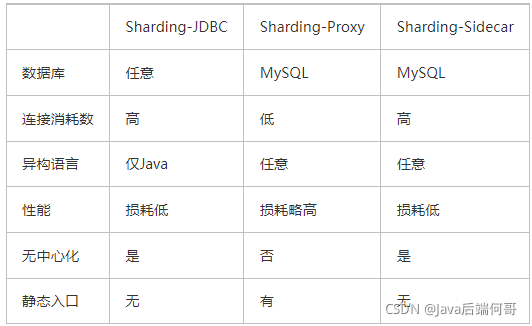
1)mycat是一個中間件的第三方應用,sharding-jdbc是一個jar包
2)使用mycat時不需要改代碼,而使用sharding-jdbc時需要修改代碼
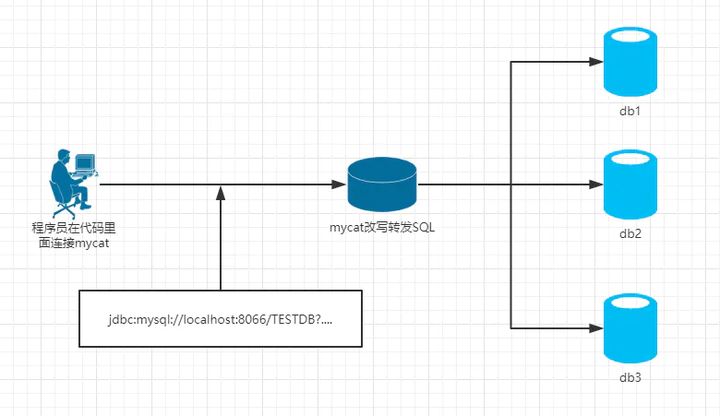
Mycat(proxy中間件層):
Sharding-jdbc(TDDL為代表的應用層):
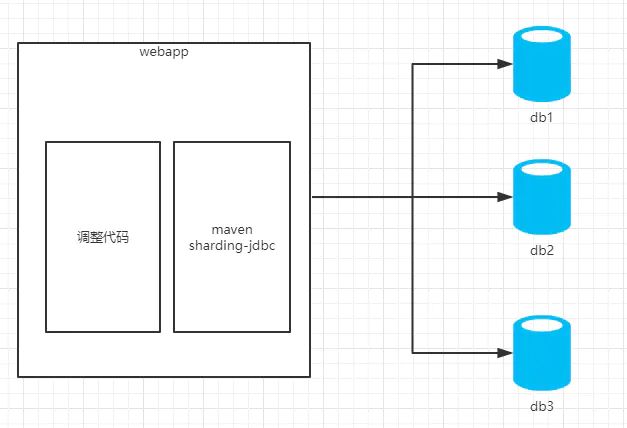
可以看出sharding-jdbc作為一個組件集成在應用內,而mycat則作為一個獨立的應用需要單獨部署。從架構上看sharding-jdbc更符合分布式架構的設計,直連數據庫,沒有中間應用,理論性能是最高的(實際性能需要結合具體的代碼實現,理論性能可以理解為上限,通過不斷優化代碼實現,逐漸接近理論性能)。同時缺點也很明顯,由于作為組件存在,需要集成在應用內,意味著作為使用方,必須要集成到代碼里,使得開發成本相對較高;另一方面,由于需要集成在應用內,使得需要針對不同語言(java、C、PHP……)有不同的實現(事實上sharding-jdbc目前只支持Java),這樣組件本身的維護成本也會很高。最終將應用場景限定在由Java開發的應用這一種場景下。
Sharding-JDBC較于MyCat,我認為最大的優勢是:sharding-jdbc是輕量級的第三方工具,直連數據庫,沒有中間應用,我們只需要在項目中引用指定的jar包即可,然后根據項目的業務需要配置分庫分表或者讀寫分離的規則和方式。
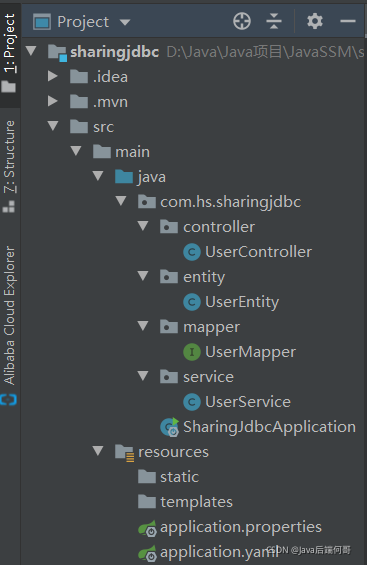
(1) 項目代碼結構
(2) 建表SQL語句
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `user_id` int(11) NOT NULL AUTO_INCREMENT, `account` varchar(45) NOT NULL, `nickname` varchar(18) NOT NULL, `password` varchar(45) NOT NULL, `headimage_url` varchar(45) DEFAULT NULL, `introduce` varchar(45) DEFAULT NULL, PRIMARY KEY (`user_id`), UNIQUE KEY `account_UNIQUE` (`account`), UNIQUE KEY `nickname_UNIQUE` (`nickname`) ) ENGINE=InnoDB AUTO_INCREMENT=66 DEFAULT CHARSET=utf8;
<!--Sharding-JDBC實現讀寫分離--> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>4.1.1</version> </dependency> <!-- mybatis-plus 依賴 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.2</version> </dependency> <!-- mysql 依賴 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <!--支持Web開發,包括Tomcat和spring-webmvc--> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--LomBok使用@Data注解--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.4</version> <scope>provided</scope> </dependency>
Spring Boot 2.x中,對數據源的選擇也緊跟潮流,默認采用了目前性能最佳的HikariCP
spring: shardingsphere: datasource: names: master,slave # 數據源名字 master: type: com.zaxxer.hikari.HikariDataSource # 連接池 driver-class-name: com.mysql.cj.jdbc.Driver jdbc-url: jdbc:mysql://xxxxxx:3306/test?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8 #主庫地址 username: root password: xxxxxx hikari: maximum-pool-size: 20 #最大連接數量 minimum-idle: 10 #最小空閑連接數 max-lifetime: 0 #最大生命周期,0不過期。不等于0且小于30秒,會被重置為默認值30分鐘.設置應該比mysql設置的超時時間短 idle-timeout: 30000 #空閑連接超時時長,默認值600000(10分鐘) connection-timeout: 60000 #連接超時時長 data-source-properties: prepStmtCacheSize: 250 prepStmtCacheSqlLimit: 2048 cachePrepStmts: true useServerPrepStmts: true slave: type: com.zaxxer.hikari.HikariDataSource # 連接池 driver-class-name: com.mysql.cj.jdbc.Driver jdbc-url: jdbc:mysql://xxxxxx:3306/test?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8 #從庫地址 username: root password: xxxxxx hikari: maximum-pool-size: 20 minimum-idle: 10 max-lifetime: 0 idle-timeout: 30000 connection-timeout: 60000 data-source-properties: prepStmtCacheSize: 250 prepStmtCacheSqlLimit: 2048 cachePrepStmts: true useServerPrepStmts: true masterslave: load-balance-algorithm-type: round_robin # 負載均衡算法,用于配置從庫負載均衡算法類型,可選值:ROUND_ROBIN(輪詢),RANDOM(隨機) name: ms # 最終的數據源名稱 master-data-source-name: master # 主庫數據源名稱 slave-data-source-names: slave # 從庫數據源名稱列表,多個逗號分隔 props: sql: show: true # 在執行SQL時,會打印SQL,并顯示執行庫的名稱,默認false
package com.hs.sharingjdbc.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
//定義表名:當數據庫名與實體類名不一致或不符合駝峰命名時,需要在此注解指定表名
@TableName(value = "user")
public class UserEntity {
//指定主鍵自增策略:value與數據庫主鍵列名一致,若實體類屬性名與表主鍵列名一致可省略value
@TableId(type = IdType.AUTO)
private Integer user_id;
private String account;
private String nickname;
private String password;
private String headimage_url;
private String introduce;
}編寫的接口需要繼承 BaseMapper接口,該接口源碼定義了一些通用的操作數據庫方法, 單表大部分 CRUD 操作都能直接搞定,相比原生的MyBatis,效率提高了很多
package com.hs.sharingjdbc.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.hs.sharingjdbc.entity.UserEntity;
public interface UserMapper extends BaseMapper<UserEntity> {
// int insert(T entity);
//
// int deleteById(Serializable id);
//
// int deleteByMap(@Param("cm") Map<String, Object> columnMap);
//
// int delete(@Param("ew") Wrapper<T> queryWrapper);
//
// int deleteBatchIds(@Param("coll") Collection<? extends Serializable> idList);
//
// int updateById(@Param("et") T entity);
//
// int update(@Param("et") T entity, @Param("ew") Wrapper<T> updateWrapper);
//
// T selectById(Serializable id);
//
// List<T> selectBatchIds(@Param("coll") Collection<? extends Serializable> idList);
//
// List<T> selectByMap(@Param("cm") Map<String, Object> columnMap);
//
// T selectOne(@Param("ew") Wrapper<T> queryWrapper);
//
// Integer selectCount(@Param("ew") Wrapper<T> queryWrapper);
//
// List<T> selectList(@Param("ew") Wrapper<T> queryWrapper);
//
// List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> queryWrapper);
//
// List<Object> selectObjs(@Param("ew") Wrapper<T> queryWrapper);
//
// <E extends IPage<T>> E selectPage(E page, @Param("ew") Wrapper<T> queryWrapper);
//
// <E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param("ew") Wrapper<T> queryWrapper);
}主類添加@MapperScan("com.hs.sharingjdbc.mapper"),掃描所有Mapper接口
package com.hs.sharingjdbc;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication()
@MapperScan("com.hs.sharingjdbc.mapper")
public class SharingJdbcApplication {
public static void main(String[] args) {
SpringApplication.run(SharingJdbcApplication.class, args);
}
}package com.hs.sharingjdbc.service;
import com.hs.sharingjdbc.entity.UserEntity;
import com.hs.sharingjdbc.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
UserMapper userMapper;
public List<UserEntity> findAll()
{
//selectList() 方法的參數為 mybatis-plus 內置的條件封裝器 Wrapper,這里不填寫表示無任何條件,全量查詢
List<UserEntity> userEntities = userMapper.selectList(null);
return userEntities;
}
public int insertUser(UserEntity user)
{
int i = userMapper.insert(user);
return i;
}
}package com.hs.sharingjdbc.controller;
import com.hs.sharingjdbc.entity.UserEntity;
import com.hs.sharingjdbc.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class UserController
{
@Autowired
UserService userService;
@RequestMapping("/listUser")
public List<UserEntity> listUser()
{
List<UserEntity> users = userService.findAll();
return users;
}
@RequestMapping("/insertUser")
public void insertUser()
{
UserEntity userEntity = new UserEntity();
userEntity.setAccount("22222");
userEntity.setNickname("hshshs");
userEntity.setPassword("123");
userService.insertUser(userEntity);
}
}http://localhost:8080/listUser ,執行查詢語句,可以看到讀操作在Slave從庫進行:

http://localhost:8090/insertUser,執行插入語句,可以看到寫操作在Master主庫進行:

這樣讀寫分離就算是可以了。
4.1、SpringBoot2關于HikariPool-1 - Failed to validate connection com.mysql.cj.jdbc.ConnectionImp
上面在使用springboot2.x 時遇到了一個很奇怪的問題,在程序運行起來之后,長時間的不進行數據庫操作就會出現這樣的錯誤,后面跟著這樣的敘述, Connection is not available, request timed out after XXXms. Possibly consider using a shorter maxLifetime value.
為什么會存在不可用的連接呢?maxLifetime可以控制連接的生命周期,我們來以前看看maxLifetime參數。

我引一下chrome上面的中文翻譯:
此屬性控制數據庫連接池中連接的最大生存期。使用中的連接永遠不會停止,只有關閉連接后,連接才會被移除。在逐個連接的基礎上,應用較小的負衰減以避免池中的質量消滅。 我們強烈建議設置此值,它應該比任何數據庫或基礎結構施加的連接時間限制短幾秒鐘。 值0表示沒有最大壽命(無限壽命),當然要遵守該idleTimeout設置。 默認值:1800000(30分鐘)
分析是HikariCP連接池對連接管理的問題,因此想方設法進行SpringBoot2.0 HikariCP連接池配置
hikari: maximum-pool-size: 20 #最大連接數量 minimum-idle: 10 #最小空閑連接數 max-lifetime: 0 #最大生命周期,0不過期。不等于0且小于30秒,會被重置為默認值30分鐘.設置應該比mysql設置的超時時間短 idle-timeout: 30000 #空閑連接超時時長,默認值600000(10分鐘) connection-timeout: 60000 #連接超時時長 data-source-properties: prepStmtCacheSize: 250 prepStmtCacheSqlLimit: 2048 cachePrepStmts: true useServerPrepStmts: true
spring.datasource.hikari.minimum-idle: 最小空閑連接,默認值10,小于0或大于maximum-pool-size,都會重置為maximum-pool-size
spring.datasource.hikari.maximum-pool-size: 最大連接數,小于等于0會被重置為默認值10;大于零小于1會被重置為minimum-idle的值
spring.datasource.hikari.idle-timeout: 空閑連接超時時間,默認值600000(10分鐘),大于等于max-lifetime且max-lifetime>0,會被重置為0;不等于0且小于10秒,會被重置為10秒。
spring.datasource.hikari.max-lifetime: 連接最大存活時間,不等于0且小于30秒,會被重置為默認值30分鐘.設置應該比mysql設置的超時時間短
spring.datasource.hikari.connection-timeout: 連接超時時間:毫秒,小于250毫秒,否則被重置為默認值30秒
4.2、com.zaxxer.hikari.pool.HikariPool : datasource -Thread starvation or clock leap detected (housekeeper delta=4m32s295ms949µs223ns).
分析:WARN警告級別,看起來不是什么錯誤,但是連接數據庫就是連不上
英譯漢:數據源-檢測到線程饑餓或時鐘跳動
人話:要么是檢測到等待連接的時間過長,造成進饑餓;要么是檢測到時鐘跳動,反正最后是關閉了數據庫連接。
其實,這里根本就沒有報錯,只是一個警告。是上游代碼出了問題,長時間不調用Service層進行存儲,然后Hikari數據源就關掉了自己;當有新的調用時,會啟用新的數據源。
修改默認的連接池配置如下:
datasource:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${ip}:3306/${數據庫}?useSSL=false&characterEncoding=UTF-8
username: ${username}
password: ${password}
hikari:
auto-commit: true
#空閑連接超時時長
idle-timeout: 60000
#連接超時時長
connection-timeout: 60000
#最大生命周期,0不過期
max-lifetime: 0
#最小空閑連接數
minimum-idle: 10
#最大連接數量
maximum-pool-size: 20剛插入一條數據,然后馬上就要去讀取,這個時候有可能會讀取不到?歸根到底是因為主節點寫入完之后數據是要復制給從節點的,讀不到的原因是復制的時間比較長,也就是說數據還沒復制到從節點,你就已經去從節點讀取了,肯定讀不到。mysql5.7 的主從復制是多線程了,意味著速度會變快,但是不一定能保證百分百馬上讀取到,這個問題我們可以有兩種方式解決:
(1)業務層面妥協,是否操作完之后馬上要進行讀取
(2)對于操作完馬上要讀出來的,且業務上不能妥協的,我們可以對于這類的讀取直接走主庫
當然Sharding-JDBC也是考慮到這個問題的存在,所以給我們提供了一個功能,可以讓用戶在使 用的時候指定要不要走主庫進行讀取。在讀取前使用下面的方式進行設置就可以了:
public List<UserInfo> findAllUser()
{
// 強制路由主庫
HintManager.getInstance().setMasterRouteOnly();
return this.list();
}看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





