溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark是近年來發展較快的分布式并行數據處理框架,了解和掌握spark對于學習大數據有著至關重要的意義。但是spark依賴于函數單元,它的函數編程過程是怎樣的呢?我們怎么來應用呢?
一、Spark的函數式編程
Spark依賴于函數單元,函數是其編程的基本單元,只有輸入輸出,沒有state和side effect。它的關鍵概念就是把函數作為其他函數的輸入,不過在使用函數的過程中 使用的都是匿名函數,因為這個函數只是滿足當下計算,因此不需要固化下來進行其它應用。
把函數作為參數傳遞
很多RDD操作把函數作為參數傳遞,這里我們看一下RDD map操作偽代碼,把函數fn應用到RDD的每條記錄。但這并不是它執行的一個真正的代碼,只是通過這個代碼去看一下它處理的邏輯。

示例:傳遞命名的函數
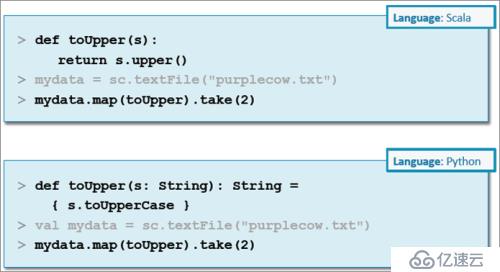
匿名函數
匿名函數是沒有標識符的嵌入式定義的函數,最適合于臨時一次性的函數。在很多編程語言中支持,比如:
(1)Python:lambda x
(2)Scala:x =>
(3)Java 8:x ->
示例:傳遞匿名函數
(1)Python

(2)Scala
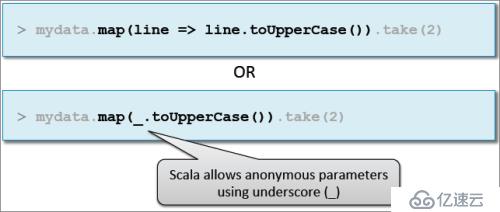
示例:Java
(1)Python

(2)Scala

Spark作為當下大數據中重要的子目,必須深度掌握學習。但是大數據還在起步發展,并沒有形成完整成熟的理論系統,需要我們多方位,多渠道的挖掘學習。這里推薦“大數據cn”微信公眾平臺,里面介紹了很多大數據的相關知識,很不錯的!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





