溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python如何利用隨機森林對特征重要性計算評估”,在日常操作中,相信很多人在Python如何利用隨機森林對特征重要性計算評估問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python如何利用隨機森林對特征重要性計算評估”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
1 前言
2 隨機森林(RF)簡介
3 特征重要性評估
4 舉個例子
隨機森林是以決策樹為基學習器的集成學習算法。隨機森林非常簡單,易于實現,計算開銷也很小,更令人驚奇的是它在分類和回歸上表現出了十分驚人的性能,因此,隨機森林也被譽為“代表集成學習技術水平的方法”。
只要了解決策樹的算法,那么隨機森林是相當容易理解的。隨機森林的算法可以用如下幾個步驟概括:
1.用有抽樣放回的方法(bootstrap)從樣本集中選取n個樣本作為一個訓練集
2.用抽樣得到的樣本集生成一棵決策樹。在生成的每一個結點:
隨機不重復地選擇d個特征
利用這d個特征分別對樣本集進行劃分,找到最佳的劃分特征(可用基尼系數、增益率或者信息增益判別)
3.重復步驟1到步驟2共k次,k即為隨機森林中決策樹的個數。
4.用訓練得到的隨機森林對測試樣本進行預測,并用票選法決定預測的結果。
下圖比較直觀地展示了隨機森林算法(圖片出自文獻2):
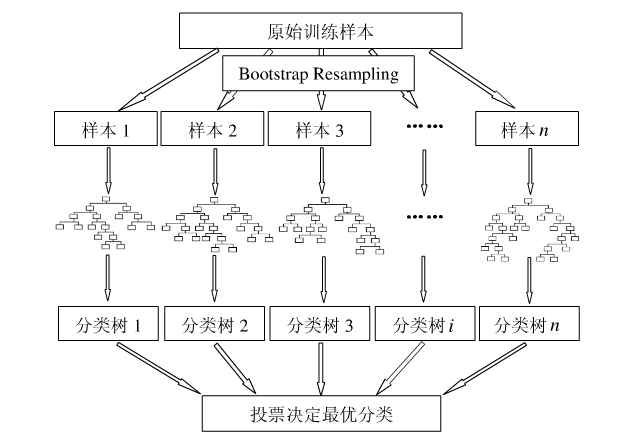
圖1:隨機森林算法示意圖
沒錯,就是這個到處都是隨機取值的算法,在分類和回歸上有著極佳的效果,是不是覺得強的沒法解釋~
然而本文的重點不是這個,而是接下來的特征重要性評估。
現實情況下,一個數據集中往往有成百上前個特征,如何在其中選擇比結果影響最大的那幾個特征,以此來縮減建立模型時的特征數是我們比較關心的問題。這樣的方法其實很多,比如主成分分析,lasso等等。不過,這里我們要介紹的是用隨機森林來對進行特征篩選。
用隨機森林進行特征重要性評估的思想其實很簡單,說白了就是看看每個特征在隨機森林中的每顆樹上做了多大的貢獻,然后取個平均值,最后比一比特征之間的貢獻大小。
好了,那么這個貢獻是怎么一個說法呢?通常可以用基尼指數(Gini index)或者袋外數據(OOB)錯誤率作為評價指標來衡量。
我們這里只介紹用基尼指數來評價的方法,想了解另一種方法的可以參考文獻2。


值得慶幸的是, sklearn已經幫我們封裝好了一切,我們只需要調用其中的函數即可。
我們以UCI上葡萄酒的例子為例,首先導入數據集。
import pandas as pd url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data' df = pd.read_csv(url, header = None) df.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
然后,我們來大致看下這時一個怎么樣的數據集
import numpy as np np.unique(df['Class label'])
輸出為
array([1, 2, 3], dtype=int64)
可見共有3個類別。然后再來看下數據的信息:
df.info()
輸出為
<class 'pandas.core.frame.DataFrame'> RangeIndex: 178 entries, 0 to 177 Data columns (total 14 columns): Class label 178 non-null int64 Alcohol 178 non-null float64 Malic acid 178 non-null float64 Ash 178 non-null float64 Alcalinity of ash 178 non-null float64 Magnesium 178 non-null int64 Total phenols 178 non-null float64 Flavanoids 178 non-null float64 Nonflavanoid phenols 178 non-null float64 Proanthocyanins 178 non-null float64 Color intensity 178 non-null float64 Hue 178 non-null float64 OD280/OD315 of diluted wines 178 non-null float64 Proline 178 non-null int64 dtypes: float64(11), int64(3) memory usage: 19.5 KB
可見除去class label之外共有13個特征,數據集的大小為178。
按照常規做法,將數據集分為訓練集和測試集。
from sklearn.cross_validation import train_test_split from sklearn.ensemble import RandomForestClassifier x, y = df.iloc[:, 1:].values, df.iloc[:, 0].values x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0) feat_labels = df.columns[1:] forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1) forest.fit(x_train, y_train)
好了,這樣一來隨機森林就訓練好了,其中已經把特征的重要性評估也做好了,我們拿出來看下。
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(x_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))輸出的結果為
1) Color intensity 0.182483 2) Proline 0.158610 3) Flavanoids 0.150948 4) OD280/OD315 of diluted wines 0.131987 5) Alcohol 0.106589 6) Hue 0.078243 7) Total phenols 0.060718 8) Alcalinity of ash 0.032033 9) Malic acid 0.025400 10) Proanthocyanins 0.022351 11) Magnesium 0.022078 12) Nonflavanoid phenols 0.014645 13) Ash 0.013916
對的就是這么方便。
如果要篩選出重要性比較高的變量的話,這么做就可以
threshold = 0.15 x_selected = x_train[:, importances > threshold] x_selected.shape
輸出為
(124, 3)
到此,關于“Python如何利用隨機森林對特征重要性計算評估”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





