溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Pandas數據結構的介紹及如何創建Series,DataFrame對象,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
在網絡上的Pandas教程中,很多都提到了如何使用Pandas將已有的數據(如csv,如hdfs等)直接加載成Pandas數據對象,然后在其基礎上進行數據分析操作,但是,很多時候,我們需要自己創建Pandas數據對象,并填入一些數據,常見的應用場景如:我們想要將現有的數據進行處理,并生成一個新的Pandas數據對象,還有,我們想利用Pandas的數據保存功能(比如to_csv, to_json, to_hdf等等)把我們采集到的數據寫入到IO里邊,因此掌握Pandas對象的特性,以及如何創建也是很重要的。
Pandas支持兩種數據類型,分別為Series和DataFrame,其中:
Series - 是一個帶有標簽的一維數組,支持多種不同的類型,但是針對同一個Series里邊存儲的數據類型必須是一致的
DataFrame - 是一個帶有標簽的二維數組,是一個尺寸可以修改的表格,一個DataFrame由多個Series組成,每一列都是一個Series
一句話描述的話就是,Series是很多標量數據(Scalar)的集合,而DataFrame是很多Series的集合。
我們來看下圖這個例子,在1D的Series中,下圖中有三個Series,分別保存了姓名(name), 年齡(age)和得分(marks),而他們的每一行都分別對應一個不同的人的信息,在每一個Series中的每一個單元格中(比如name series的第1行,對應的Prasadi)都是一個標量(Scalar),而每一行前邊的0,1,2,3這些就是數據的索引(index),也可以叫做標簽,所以說,Series是帶有標簽的一維數組。
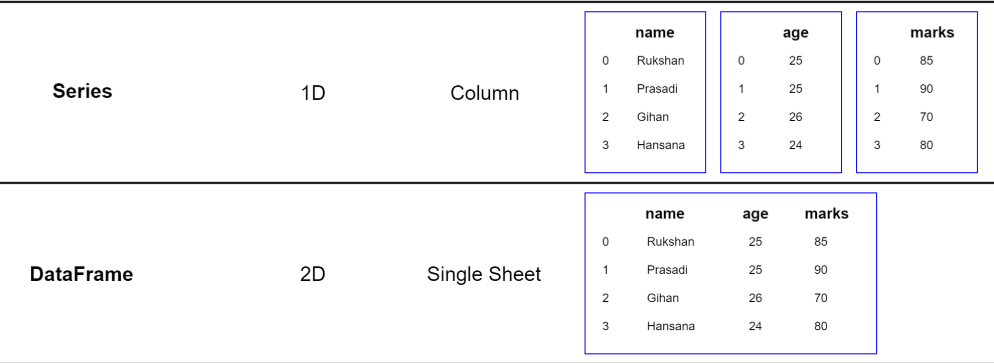
可以看出,利用Series只能存儲一種類型的數據,比如說name series存儲的數據是字符串類型,而age series存儲的數據是整數型。如果我們想把name,age,marks存儲在一個數據結構里,我們就需要使用DataFrame,從圖中看出,DataFrame類似于一個表格數據,有行有列,行跟Series的行一致,是數據的標簽,而每一列就是原來的每一個Series。
如我們在前文中所說,Series結構中可以存儲任何類型的數據,包括:整型,字符串類型,浮點型,甚至是Python對象等等,但是要求是,每一行的數據類型必須統一。那么如何創建一個Series對象呢,
Pandas的一個主要用途是數據分析,而它也是基于Numpy實現的,因此,通過numpy array來創建Series是非常常見的。
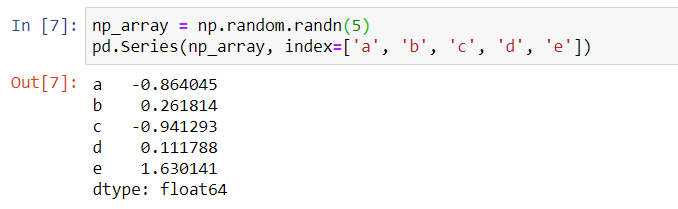
np_array = np.random.randn(5) pd.Series(np_array, index=['a', 'b', 'c', 'd', 'e'])
上邊這段代碼,利用np.random.randn隨機生成一個長度為5的numpy array,然后pd.Series使用這個numpy array來創建一個Series,在創建的同時,指定了每一行的index(標簽)分別是a,b,c,d,e,f,輸出結果為:
通過上邊這個示例,大家有沒有發現Series跟Python內置的dict類型是不是很類似,標簽相當于dict中的key,而數據內容相當于dict中的value,它們有一一對應的關系,因此,可以想象,我們能夠直接通過Python的dict來創建一個Series。
d = {'b': 1, 'a': 0, 'c': 2}
pd.Series(d)上邊這段代碼,我們先創建了一個Python地點d,然后將這個字典傳遞給pd.Series來創建一個Pandas Series,運行結果為:

除了上邊這兩種方式,我們還可以通過一個簡單的標量值來創建Series,特別注意的是跟上邊兩種方式不同,在使用這種方式創建Series的時候,我們必須指定index
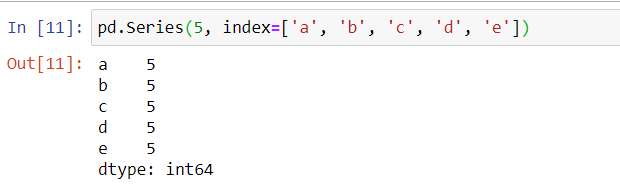
pd.Series(5, index=['a', 'b', 'c', 'd', 'e'])
如上邊代碼所示,我們使用一個常量5,然后指定index為a,b,c,d,e,同樣使用pd.Series可以創建一個Series對象,看到這里我們就能夠明白為什么必須指定Index了吧,那是因為Series對象是有長度的,長度是可以大于1的,而標量的長度固定為1,我們可以通過指定Index的方式來控制生成的Series的長度,Series中的值則是重復使用這一個標量常量5。其運行結果為:
當我們創建一個Series的時候,我們可以指定一個名稱,這個名稱會被存儲到Series的name屬性中,后續我們還可以使用rename方法來修改這個屬性,例如下邊這樣的代碼:
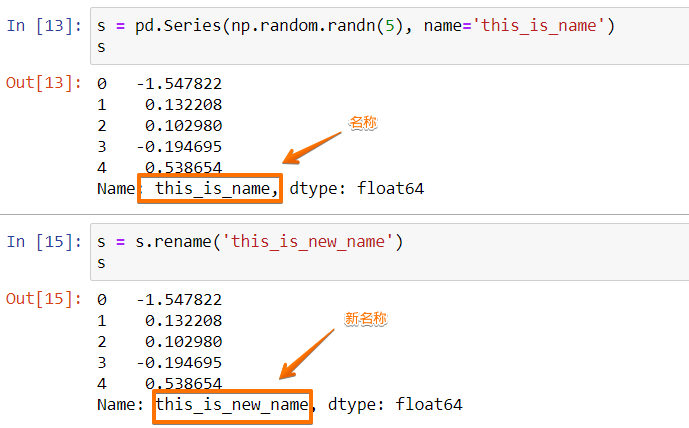
s = pd.Series(np.random.randn(5), name='this_is_name') s
創建了一個名稱為this_is_name的Series,然后我們使用rename方法來重命名這個Series為this_is_new_name:
s = s.rename('this_is_new_name')
s上邊這兩部分代碼的輸入如下圖:
那么這個名稱有什么作用呢,這里預告一下,我們將在DataFrame中用到(別忘了DataFrame是多個Series的集合)
在第一節中我們介紹到,DataFrame是一個二維的表格數據結構,它有行和列的概念,跟行標簽相對應的,為了能夠按列索引數據,每一列都可以有一個名稱,即列名,我們剛在Series章節中看到,Series可以表示一列數據,我們在本節中介紹的DataFrame就是多個這樣的Series的組合,每一列就對應一個Series,而每一行也對應一個Series。讀到這里,你是不是能夠猜的出我們剛說的Series的name屬性的用途了,對了,使用Series創建DataFrame的列的時候,Series的名稱就會成為列名,如果Series作為行,則Series的名稱會成為行名。
接下來我們來講解如何創建DataFrame
通過一維numpy array或者Python List 組成的字典
大家可以想想,如果一個字典的value是array或者list的時候,那么這個字典其實就是一種表格結構,圖為DataFrame是一個表格結構的數據類型,我們是可以通過這樣的字典來創建DataFrame,例如下邊這段代碼
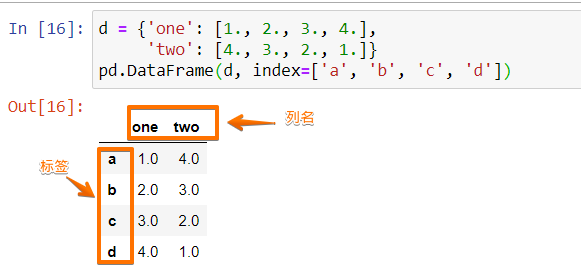
d = {'one': [1., 2., 3., 4.],
'two': [4., 3., 2., 1.]}
pd.DataFrame(d, index=['a', 'b', 'c', 'd'])我們把d這個Python字典傳遞給pd.DataFrame來創建新的DataFrame,同時我們可以通過指定index來指定DataFrame的行名(標簽),上邊代碼的輸出為
我們再來想想一下,除了字典之外可以表示表格數據,還有沒有其他的方法,是的,還有Python List,例如下邊這段代碼
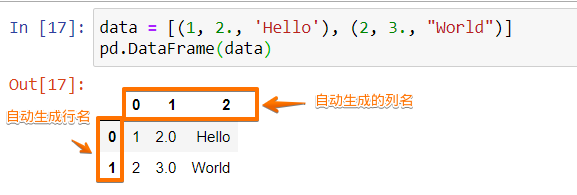
data = [(1, 2., 'Hello'), (2, 3., "World")] pd.DataFrame(data)
我們可以用data這樣的Python List來表示表格數據,不同于前邊提到的字典(dict),用List表示的表格數據其實是沒有行名和列名的,因此Pandas默認會自動生成行名和列名,所以上邊的代碼輸出為:
當然,自動生成的行名列名沒有任何意義,為了更好的操作數據,我們還可以通過設置pd.DataFrame方法的index或者columns參數來指定自己的行名或者列名。
我們繼續想想,還有什么能夠表示表格數據?對了,包含Python字典的Python List也是可以表達表格數據的,例如下邊的代碼
data = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
pd.DataFrame(data)data是一個Python List,而列表中的每一個元素都是一個字典,運行結果為:

類似的,我們也可以通過指定index或者columns參數來修改行名和列名
我們一直在提DataFrame是很多Series的集合(注:Series在DataFrame中可以是一行,也可以是一列),因此,我們也可以通過Series來創建DataFrame,例如下邊這段代碼
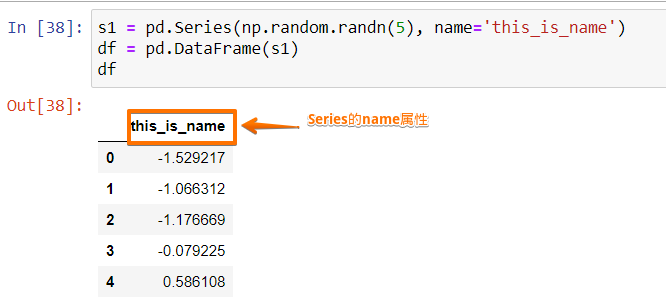
s1 = pd.Series(np.random.randn(5), name='this_is_name') df = pd.DataFrame(s1) df
利用s1這個Series來創建只有一列的DataFrame,輸出結果為:
還記得不,我們前邊提到了Series的name屬性,在使用Series創建DataFrame的時候,這個屬性會用來作為列名(或者行名,我們在下邊的列子可以看得出),例如下邊的這段代碼,如果有兩個Series,我們還可以用下邊這樣的方式創建DataFrame
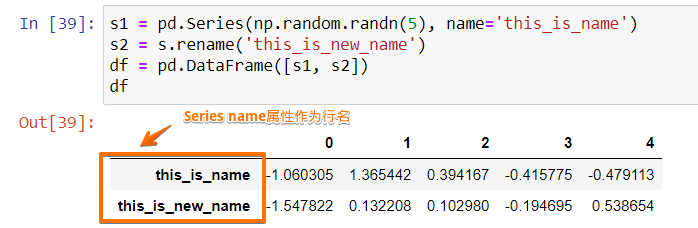
s1 = pd.Series(np.random.randn(5), name='this_is_name')
s2 = s.rename('this_is_new_name')
df = pd.DataFrame([s1, s2])
df這里我們使用了兩個名分別為this_is_name和this_is_new_name的Series來創建DataFrame,得到的結果為:
到這里,相信讀者已經對Pandas提供的數據類型有了一個全面的認識了,并且有能力自己創建Pandas數據結構,并存儲自己的數據了,一個常見的應用場景就是我們通過爬蟲獲取到數據以后,可以將這些非結構化的數據以Pandas的表格格式保存,值得注意的是數據存儲在Pandas數據結構中的時候,數據其實是在內存中的,當程序被關閉以后,數據就丟失了,如果我們需要將數據持久化保存到硬盤或者數據庫中的話,則可以通過簡單的調用Pandas提供的to_csv, to_json, to_hdf等等接口將數據永久保存下來。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





