溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Redis高效率原因及數據結構的示例分析,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
Redis,英文全稱是Remote Dictionary Server(遠程字典服務),是一個開源的使用ANSI C語言編寫、支持網絡、可基于內存亦可持久化的日志型、Key-Value數據庫,并提供多種語言的API。
與MySQL數據庫不同的是,Redis的數據是存在內存中的。它的讀寫速度非常快,每秒可以處理超過10萬次讀寫操作。因此redis被廣泛應用于緩存,另外,Redis也經常用來做分布式鎖。除此之外,Redis支持事務、持久化、LUA 腳本、LRU 驅動事件、多種集群方案。
知道redis是什么后,接下來我們來說一說redis為什么這么快。
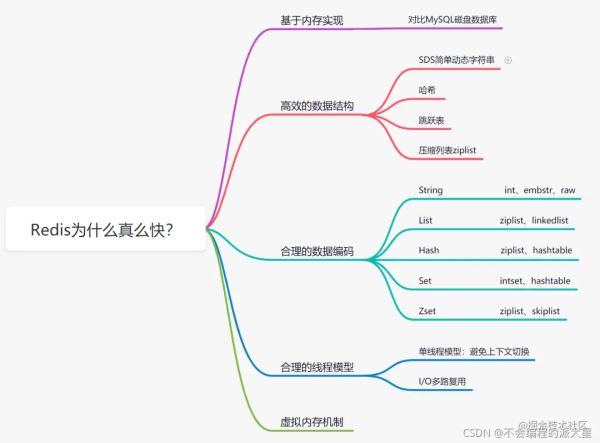
我們來一個一個說明!
計算機專業的同學我們都知道內存讀寫是要比磁盤快很多的,Redis是基于內存實現的數據庫,相對于數據存在磁盤的mysql等數據庫,省去了磁盤I/O的消耗。
我們都知道,mysql索引為了提高效率,選擇了B+樹的數據結構,對于一個應用場景來說合理的數據結構可以讓你的應用或者程序更快。我們來看看Redis的數據結構–內部編碼圖:
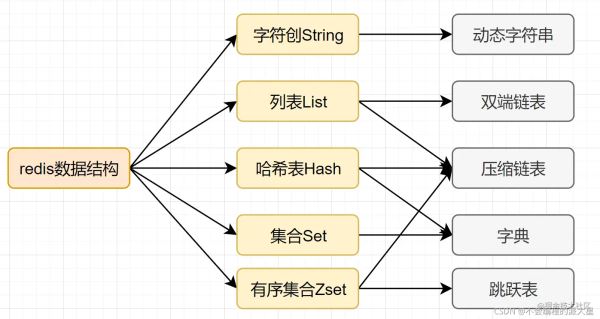
String : 動態字符串SDSList: 雙端鏈表LinkedList+壓縮鏈表ziplistHash: 壓縮鏈表ziplist+字典哈希表hashtableSet: hashtable(+inset)Zset: 壓縮鏈表ziplist+跳表skiplist
我們來說一說這幾種內部編碼:
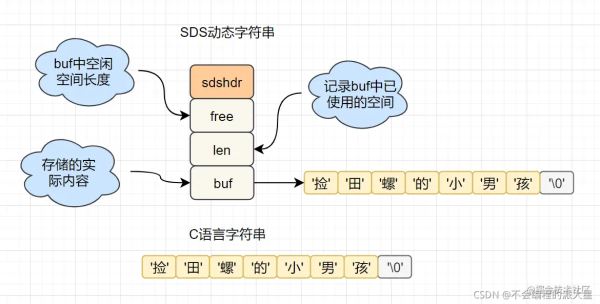
我們來和C語言中的char[ ]對比下
字符串長度處理: Redis獲取字符串長度,時間復雜度為O(1),而C語言中,需要從頭遍歷,復雜度為O(N)。
空間預分配: 字符串修改越頻繁的話,內存分配就越頻繁,就會很消費性能,而SDS修改和空間擴充,會額外分配未使用的空間,減少性能損耗。
惰性空間釋放: SDS縮短時,不是回收多余的內存空間,而是free記錄下多余的空間,后續有變更,直接使用free中記錄的空間,減少分配。
二進制安全: Redis可以存儲一些二進制數據,在C語言中字符串遇到'/0'會結束,而SDS中標志字符串結束的是len屬性。
Redis 作為 K-V 型內存數據庫,所有的鍵值就是用字典來存儲。字典就是哈希表,比如HashMap,通過key就可以直接獲取到對應的value。而哈希表的特性,在O(1)時間復雜度就可以獲得對應的值。
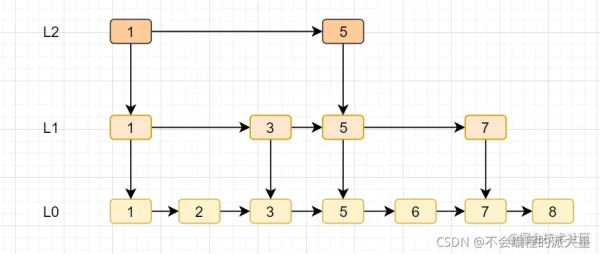
跳表是Redis特有的數據結構,就是在鏈表的基礎上,增加多級索引提升查找效率。
跳表支持平均O(logN),最壞O(N)復雜度的節點查找,還可以通過順序性操作。
Redis 支持多種數據數據類型,每種基本類型,可能對多種數據結構。什么時候,使用什么樣數據結構,使用什么樣編碼,是redis設計者總結優化的結果。
String: 如果存儲數字的話,是用int類型的編碼;如果存儲非數字,小于等于39字節的字符串,是embstr;大于39個字節,則是raw編碼。
List: 如果列表的元素個數小于512個,列表每個元素的值都小于64字節(默認),使用ziplist編碼,否則使用linkedlist編碼
Hash: 哈希類型元素個數小于512個,所有值小于64字節的話,使用ziplist編碼,否則使用hashtable編碼。
Set: 如果集合中的元素都是整數且元素個數小于512個,使用intset編碼,否則使用hashtable編碼。
Zset: 當有序集合的元素個數小于128個,每個元素的值小于64字節時,使用ziplist編碼,否則使用skiplist(跳躍表)編碼。
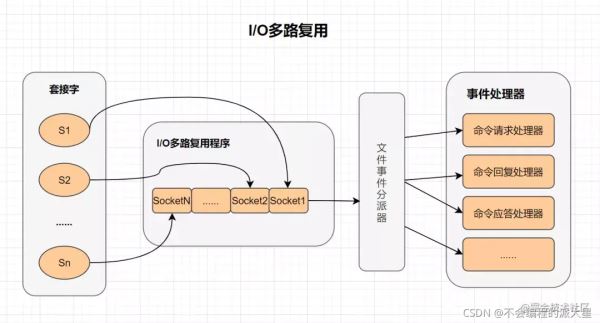
多路I/O復用技術可以讓單個線程高效的處理多個連接請求,而Redis使用用epoll作為I/O多路復用技術的實現。并且,Redis自身的事件處理模型將epoll中的連接、讀寫、關閉都轉換為事件,不在網絡I/O上浪費過多的時間。
I/O : 網絡 I/O
多路 : 多個網絡連接
復用: 復用同一個線程。
IO多路復用其實就是一種同步IO模型,它實現了一個線程可以監視多個文件句柄;一旦某個文件句柄就緒,就能夠通知應用程序進行相應的讀寫操作;而沒有文件句柄就緒時,就會阻塞應用程序,交出cpu。
Redis是單線程模型的,而單線程避免了CPU不必要的上下文切換和競爭鎖的消耗。也正因為是單線程,如果某個命令執行過長(如hgetall命令),會造成阻塞。Redis是面向快速執行場景的數據庫。,所以要慎用如smembers和lrange、hgetall等命令。
Redis 6.0 引入了多線程提速,它的執行命令操作內存的仍然是個單線程。
redis直接自己構建了VM機制,不會像一般的系統會調用系統函數處理,會浪費一定的時間去移動和請求。
虛擬內存機制就是暫時把不經常訪問的數據(冷數據)從內存交換到磁盤中,從而騰出寶貴的內存空間用于其它需要訪問的數據(熱數據)。通過VM功能可以實現冷熱數據分離,使熱數據仍在內存中、冷數據保存到磁盤。這樣就可以避免因為內存不足而造成訪問速度下降的問題。
以上是“Redis高效率原因及數據結構的示例分析”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





