溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下JavaScript常用字符串方法有哪些,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
JavaScript中有哪些常用的字符串方法
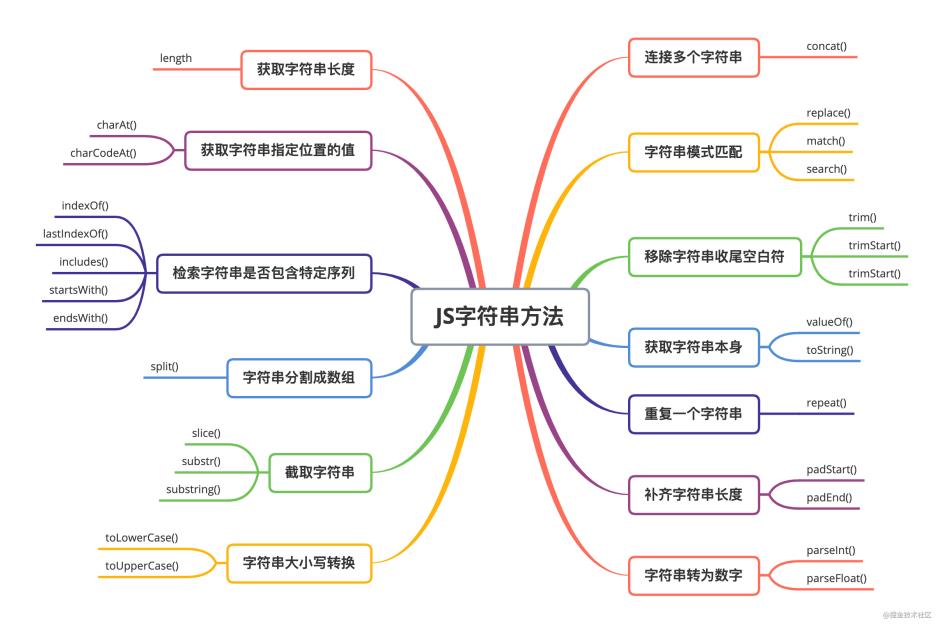
JavaScript中的字符串有一個length屬性,該屬性可以用來獲取字符串的長度: const str = 'hello'; str.length // 輸出結果:5
charAt()和charCodeAt()方法都可以通過索引來獲取指定位置的值:
charAt() 方法獲取到的是指定位置的字符;
charCodeAt()方法獲取的是指定為值得字符的Unicode值。
charAt() 方法可以返回指定位置的字符。其語法如下:
string.charAt(index)
index表示字符在字符串中的索引值:
const str = 'hello'; str.charAt(1) // 輸出結果:e
我們知道,字符串也可以通過索引值來直接獲取對應字符,那它和charAt()有什么區別呢?來看例子:
const str = 'hello'; str.charAt(1) // 輸出結果:e str[1] // 輸出結果:e str.charAt(5) // 輸出結果:'' str[5] // 輸出結果:undefined
可以看到,當index的取值不在str的長度范圍內時,str[index]會返回undefined,而charAt(index)會返回空字符串;除此之外,str[index]不兼容ie6-ie8,charAt(index)可以兼容。
charCodeAt():該方法會返回指定索引位置字符的 Unicode 值,返回值是 0 - 65535 之間的整數,表示給定索引處的 UTF-16 代碼單元,如果指定位置沒有字符,將返回 NaN:
let str = "abcdefg"; console.log(str.charCodeAt(1)); // "b" --> 98
通過這個方法,可以獲取字符串中指定Unicode編碼值范圍的字符。比如,數字0~9的Unicode編碼范圍是: 48~57,可以通過這個方法來篩選字符串中的數字,當然如果你更熟悉正則表達式,會更方便。
這5個方法都可以用來檢索一個字符串中是否包含特定的序列。其中前兩個方法得到的指定元素的索引值,并且只會返回第一次匹配到的值的位置。后三個方法返回的是布爾值,表示是否匹配到指定的值。
注意:這5個方法都對大小寫敏感!
indexOf():查找某個字符,有則返回第一次匹配到的位置,否則返回-1,其語法如下:
string.indexOf(searchvalue,fromindex)
該方法有兩個參數:
searchvalue:必需,規定需檢索的字符串值;
fromindex:可選的整數參數,規定在字符串中開始檢索的位置。它的合法取值是 0 到 string.length - 1。如省略該,則從字符串的首字符開始檢索。
let str = "abcdefgabc";
console.log(str.indexOf("a")); // 輸出結果:0
console.log(str.indexOf("z")); // 輸出結果:-1
console.log(str.indexOf("c", 4)) // 輸出結果:9lastIndexOf():查找某個字符,有則返回最后一次匹配到的位置,否則返回-1
let str = "abcabc";
console.log(str.lastIndexOf("a")); // 輸出結果:3
console.log(str.lastIndexOf("z")); // 輸出結果:-1該方法和indexOf()類似,只是查找的順序不一樣,indexOf()是正序查找,lastIndexOf()是逆序查找。
includes():該方法用于判斷字符串是否包含指定的子字符串。如果找到匹配的字符串則返回 true,否則返回 false。該方法的語法如下:
string.includes(searchvalue, start)
該方法有兩個參數:
searchvalue:必需,要查找的字符串;
start:可選,設置從那個位置開始查找,默認為 0。
let str = 'Hello world!';
str.includes('o') // 輸出結果:true
str.includes('z') // 輸出結果:false
str.includes('e', 2) // 輸出結果:falsestartsWith():該方法用于檢測字符串是否以指定的子字符串開始。如果是以指定的子字符串開頭返回 true,否則 false。其語法和上面的includes()方法一樣。
let str = 'Hello world!';
str.startsWith('Hello') // 輸出結果:true
str.startsWith('Helle') // 輸出結果:false
str.startsWith('wo', 6) // 輸出結果:trueendsWith():該方法用來判斷當前字符串是否是以指定的子字符串結尾。如果傳入的子字符串在搜索字符串的末尾則返回 true,否則將返回 false。其語法如下:
string.endsWith(searchvalue, length)
該方法有兩個參數:
searchvalue:必需,要搜索的子字符串;
length: 設置字符串的長度,默認值為原始字符串長度 string.length。
let str = 'Hello world!';
str.endsWith('!') // 輸出結果:true
str.endsWith('llo') // 輸出結果:false
str.endsWith('llo', 5) // 輸出結果:true可以看到,當第二個參數設置為5時,就會從字符串的前5個字符中進行檢索,所以會返回true。
concat() 方法用于連接兩個或多個字符串。該方法不會改變原有字符串,會返回連接兩個或多個字符串的新字符串。其語法如下:
string.concat(string1, string2, ..., stringX)
其中參數 string1, string2, ..., stringX 是必須的,他們將被連接為一個字符串的一個或多個字符串對象。
let str = "abc";
console.log(str.concat("efg")); //輸出結果:"abcefg"
console.log(str.concat("efg","hijk")); //輸出結果:"abcefghijk"雖然concat()方法是專門用來拼接字符串的,但是在開發中使用最多的還是加操作符+,因為其更加簡單。
split() 方法用于把一個字符串分割成字符串數組。該方法不會改變原始字符串。其語法如下:
string.split(separator,limit)
該方法有兩個參數:
separator:必需。字符串或正則表達式,從該參數指定的地方分割 string。
limit:可選。該參數可指定返回的數組的最大長度。如果設置了該參數,返回的子串不會多于這個參數指定的數組。如果沒有設置該參數,整個字符串都會被分割,不考慮它的長度。
let str = "abcdef";
str.split("c"); // 輸出結果:["ab", "def"]
str.split("", 4) // 輸出結果:['a', 'b', 'c', 'd']如果把空字符串用作 separator,那么字符串中的每個字符之間都會被分割。
str.split(""); // 輸出結果:["a", "b", "c", "d", "e", "f"]其實在將字符串分割成數組時,可以同時拆分多個分割符,使用正則表達式即可實現:
const list = "apples,bananas;cherries" const fruits = list.split(/[,;]/) console.log(fruits); // 輸出結果:["apples", "bananas", "cherries"]
substr()、substring()和 slice() 方法都可以用來截取字符串。
slice() 方法用于提取字符串的某個部分,并以新的字符串返回被提取的部分。其語法如下:
string.slice(start,end)
該方法有兩個參數:
start:必須。 要截取的片斷的起始下標,第一個字符位置為 0。如果為負數,則從尾部開始截取。
end:可選。 要截取的片段結尾的下標。若未指定此參數,則要提取的子串包括 start 到原字符串結尾的字符串。如果該參數是負數,那么它規定的是從字符串的尾部開始算起的位置。
上面說了,如果start是負數,則該參數規定的是從字符串的尾部開始算起的位置。也就是說,-1 指字符串的最后一個字符,-2 指倒數第二個字符,以此類推:
let str = "abcdef"; str.slice(1,6); // 輸出結果:"bcdef" str.slice(1); // 輸出結果:"bcdefg" str.slice(); // 輸出結果:"abcdefg" str.slice(-2); // 輸出結果:"fg" str.slice(6, 1); // 輸出結果:""
注意,該方法返回的子串包括開始處的字符,但不包括結束處的字符。
substr() 方法用于在字符串中抽取從開始下標開始的指定數目的字符。其語法如下:
string.substr(start,length)
該方法有兩個參數:
start 必需。要抽取的子串的起始下標。必須是數值。如果是負數,那么該參數聲明從字符串的尾部開始算起的位置。也就是說,-1 指字符串中最后一個字符,-2 指倒數第二個字符,以此類推。
length:可選。子串中的字符數。必須是數值。如果省略了該參數,那么返回從 stringObject 的開始位置到結尾的字串。
let str = "abcdef"; str.substr(1,6); // 輸出結果:"bcdefg" str.substr(1); // 輸出結果:"bcdefg" 相當于截取[1,str.length-1] str.substr(); // 輸出結果:"abcdefg" 相當于截取[0,str.length-1] str.substr(-1); // 輸出結果:"g"
substring() 方法用于提取字符串中介于兩個指定下標之間的字符。其語法如下:
string.substring(from, to)
該方法有兩個參數:
from:必需。一個非負的整數,規定要提取的子串的第一個字符在 string 中的位置。
to:可選。一個非負的整數,比要提取的子串的最后一個字符在 string 中的位置多 1。如果省略該參數,那么返回的子串會一直到字符串的結尾。
注意: 如果參數 from 和 to 相等,那么該方法返回的就是一個空串(即長度為 0 的字符串)。如果 from 比 to 大,那么該方法在提取子串之前會先交換這兩個參數。并且該方法不接受負的參數,如果參數是個負數,就會返回這個字符串。
let str = "abcdef"; str.substring(1,6); // 輸出結果:"bcdef" [1,6) str.substring(1); // 輸出結果:"bcdefg" [1,str.length-1] str.substring(); // 輸出結果:"abcdefg" [0,str.length-1] str.substring(6,1); // 輸出結果 "bcdef" [1,6) str.substring(-1); // 輸出結果:"abcdefg"
注意,該方法返回的子串包括開始處的字符,但不包括結束處的字符。
toLowerCase() 和 toUpperCase()方法可以用于字符串的大小寫轉換。
toLowerCase():該方法用于把字符串轉換為小寫。 let str = "adABDndj"; str.toLowerCase(); // 輸出結果:"adabdndj"
toUpperCase():該方法用于把字符串轉換為大寫。
let str = "adABDndj"; str.toUpperCase(); // 輸出結果:"ADABDNDJ"
我們可以用這個方法來將字符串中第一個字母變成大寫:
let word = 'apple' word = word[0].toUpperCase() + word.substr(1) console.log(word) // 輸出結果:"Apple"
replace()、match()和search()方法可以用來匹配或者替換字符。
replace():該方法用于在字符串中用一些字符替換另一些字符,或替換一個與正則表達式匹配的子串。其語法如下:
string.replace(searchvalue, newvalue)
該方法有兩個參數:
searchvalue:必需。規定子字符串或要替換的模式的 RegExp 對象。如果該值是一個字符串,則將它作為要檢索的直接量文本模式,而不是首先被轉換為 RegExp 對象。
newvalue:必需。一個字符串值。規定了替換文本或生成替換文本的函數。
let str = "abcdef";
str.replace("c", "z") // 輸出結果:abzdef執行一個全局替換, 忽略大小寫:
let str="Mr Blue has a blue house and a blue car"; str.replace(/blue/gi, "red"); // 輸出結果:'Mr red has a red house and a red car'
注意: 如果 regexp 具有全局標志 g,那么 replace() 方法將替換所有匹配的子串。否則,它只替換第一個匹配子串。
match():該方法用于在字符串內檢索指定的值,或找到一個或多個正則表達式的匹配。該方法類似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置。其語法如下:
string.match(regexp)
該方法的參數 regexp 是必需的,規定要匹配的模式的 RegExp 對象。如果該參數不是 RegExp 對象,則需要首先把它傳遞給 RegExp 構造函數,將其轉換為 RegExp 對象。
注意: 該方法返回存放匹配結果的數組。該數組的內容依賴于 regexp 是否具有全局標志 g。
let str = "abcdef";
console.log(str.match("c")) // ["c", index: 2, input: "abcdef", groups: undefined]search()方法用于檢索字符串中指定的子字符串,或檢索與正則表達式相匹配的子字符串。其語法如下:
string.search(searchvalue)
該方法的參數 regex 可以是需要在 string 中檢索的子串,也可以是需要檢索的 RegExp 對象。
注意: 要執行忽略大小寫的檢索,請追加標志 i。該方法不執行全局匹配,它將忽略標志 g,也就是只會返回第一次匹配成功的結果。如果沒有找到任何匹配的子串,則返回 -1。
返回值: 返回 str 中第一個與 regexp 相匹配的子串的起始位置。
let str = "abcdef"; str.search(/bcd/) // 輸出結果:1
trim()、trimStart()和trimEnd()這三個方法可以用于移除字符串首尾的頭尾空白符,空白符包括:空格、制表符 tab、換行符等其他空白符等。
trim() 方法用于移除字符串首尾空白符,該方法不會改變原始字符串:
let str = " abcdef " str.trim() // 輸出結果:"abcdef"
注意,該方法不適用于null、undefined、Number類型。
trimStart() 方法的的行為與trim()一致,不過會返回一個從原始字符串的開頭刪除了空白的新字符串,不會修改原始字符串:
const s = ' abc '; s.trimStart() // "abc "
trimEnd() 方法的的行為與trim()一致,不過會返回一個從原始字符串的結尾刪除了空白的新字符串,不會修改原始字符串:
const s = ' abc '; s.trimEnd() // " abc"
valueOf()和toString()方法都會返回字符串本身的值,感覺用處不大。
valueOf():返回某個字符串對象的原始值,該方法通常由 JavaScript 自動進行調用,而不是顯式地處于代碼中。
let str = "abcdef" console.log(str.valueOf()) // "abcdef"
toString():返回字符串對象本身
let str = "abcdef" console.log(str.toString()) // "abcdef"
repeat() 方法返回一個新字符串,表示將原字符串重復n次:
'x'.repeat(3) // 輸出結果:"xxx" 'hello'.repeat(2) // 輸出結果:"hellohello" 'na'.repeat(0) // 輸出結果:""
如果參數是小數,會向下取整:
'na'.repeat(2.9) // 輸出結果:"nana"
如果參數是負數或者Infinity,會報錯:
'na'.repeat(Infinity) // RangeError 'na'.repeat(-1) // RangeError
如果參數是 0 到-1 之間的小數,則等同于 0,這是因為會先進行取整運算。0 到-1 之間的小數,取整以后等于-0,repeat視同為 0。
'na'.repeat(-0.9) // 輸出結果:""
如果參數是NaN,就等同于 0:
'na'.repeat(NaN) // 輸出結果:""
如果repeat的參數是字符串,則會先轉換成數字。
'na'.repeat('na') // 輸出結果:""
'na'.repeat('3') // 輸出結果:"nanana"padStart()和padEnd()方法用于補齊字符串的長度。如果某個字符串不夠指定長度,會在頭部或尾部補全。
padStart()用于頭部補全。該方法有兩個參數,其中第一個參數是一個數字,表示字符串補齊之后的長度;第二個參數是用來補全的字符串。
如果原字符串的長度,等于或大于指定的最小長度,則返回原字符串:
'x'.padStart(1, 'ab') // 'x'
如果用來補全的字符串與原字符串,兩者的長度之和超過了指定的最小長度,則會截去超出位數的補全字符串:
'x'.padStart(5, 'ab') // 'ababx' 'x'.padStart(4, 'ab') // 'abax'
如果省略第二個參數,默認使用空格補全長度:
'x'.padStart(4, 'ab') // 'a '
padStart()的常見用途是為數值補全指定位數,筆者最近做的一個需求就是將返回的頁數補齊為三位,比如第1頁就顯示為001,就可以使用該方法來操作:
"1".padStart(3, '0') // 輸出結果: '001' "15".padStart(3, '0') // 輸出結果: '015'
padEnd()用于尾部補全。該方法也是接收兩個參數,第一個參數是字符串補全生效的最大長度,第二個參數是用來補全的字符串:
'x'.padEnd(5, 'ab') // 'xabab' 'x'.padEnd(4, 'ab') // 'xaba'
parseInt()和parseFloat()方法都用于將字符串轉為數字。
parseInt() 方法用于可解析一個字符串,并返回一個整數。其語法如下:
parseInt(string, radix)
該方法有兩個參數:
string:必需。要被解析的字符串。
radix:可選。表示要解析的數字的基數。該值介于 2 ~ 36 之間。
當參數 radix 的值為 0,或沒有設置該參數時,parseInt() 會根據 string 來判斷數字的基數。
parseInt("10"); // 輸出結果:10
parseInt("17",8); // 輸出結果:15 (8+7)
parseInt("010"); // 輸出結果:10 或 8當參數 radix 的值以 “0x” 或 “0X” 開頭,將以 16 為基數:
parseInt("0x10") // 輸出結果:16如果該參數小于 2 或者大于 36,則 parseInt() 將返回 NaN:
parseInt("50", 1) // 輸出結果:NaN
parseInt("50", 40) // 輸出結果:NaN只有字符串中的第一個數字會被返回,當遇到第一個不是數字的字符為止:
parseInt("40 4years") // 輸出結果:40如果字符串的第一個字符不能被轉換為數字,就會返回 NaN:
parseInt("new100") // 輸出結果:NaN字符串開頭和結尾的空格是允許的:
parseInt(" 60 ") // 輸出結果: 60parseFloat() 方法可解析一個字符串,并返回一個浮點數。該方法指定字符串中的首個字符是否是數字。如果是,則對字符串進行解析,直到到達數字的末端為止,然后以數字返回該數字,而不是作為字符串。其語法如下:
parseFloat(string)
parseFloat 將它的字符串參數解析成為浮點數并返回。如果在解析過程中遇到了正負號(+ 或 -)、數字 (0-9)、小數點,或者科學記數法中的指數(e 或 E)以外的字符,則它會忽略該字符以及之后的所有字符,返回當前已經解析到的浮點數。同時參數字符串首位的空白符會被忽略。
parseFloat("10.00") // 輸出結果:10.00
parseFloat("10.01") // 輸出結果:10.01
parseFloat("-10.01") // 輸出結果:-10.01
parseFloat("40.5 years") // 輸出結果:40.5如果參數字符串的第一個字符不能被解析成為數字,則 parseFloat 返回 NaN。
parseFloat("new40.5") // 輸出結果:NaN以上是“JavaScript常用字符串方法有哪些”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





