溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“java中LinkedHashMap的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“java中LinkedHashMap的示例分析”這篇文章吧。
LinkedHashMap維護插入的順序。
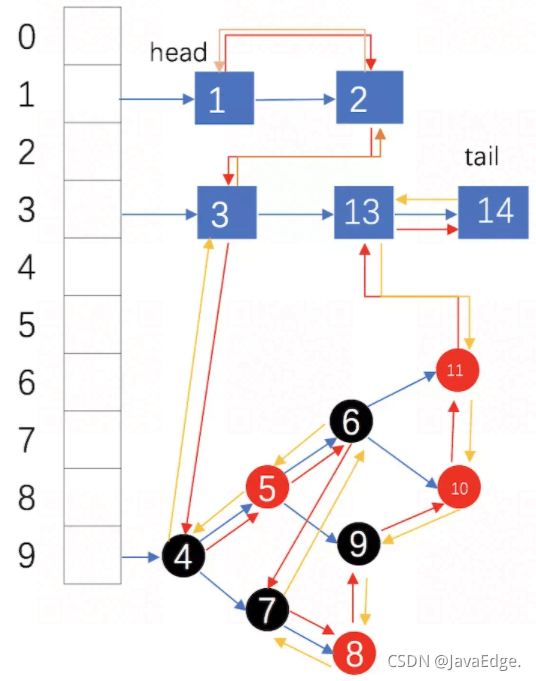
紅黃箭頭:元素添加順序
藍箭頭:單鏈表各個元素的存儲順序
head:鏈表頭部
tail:鏈表尾部
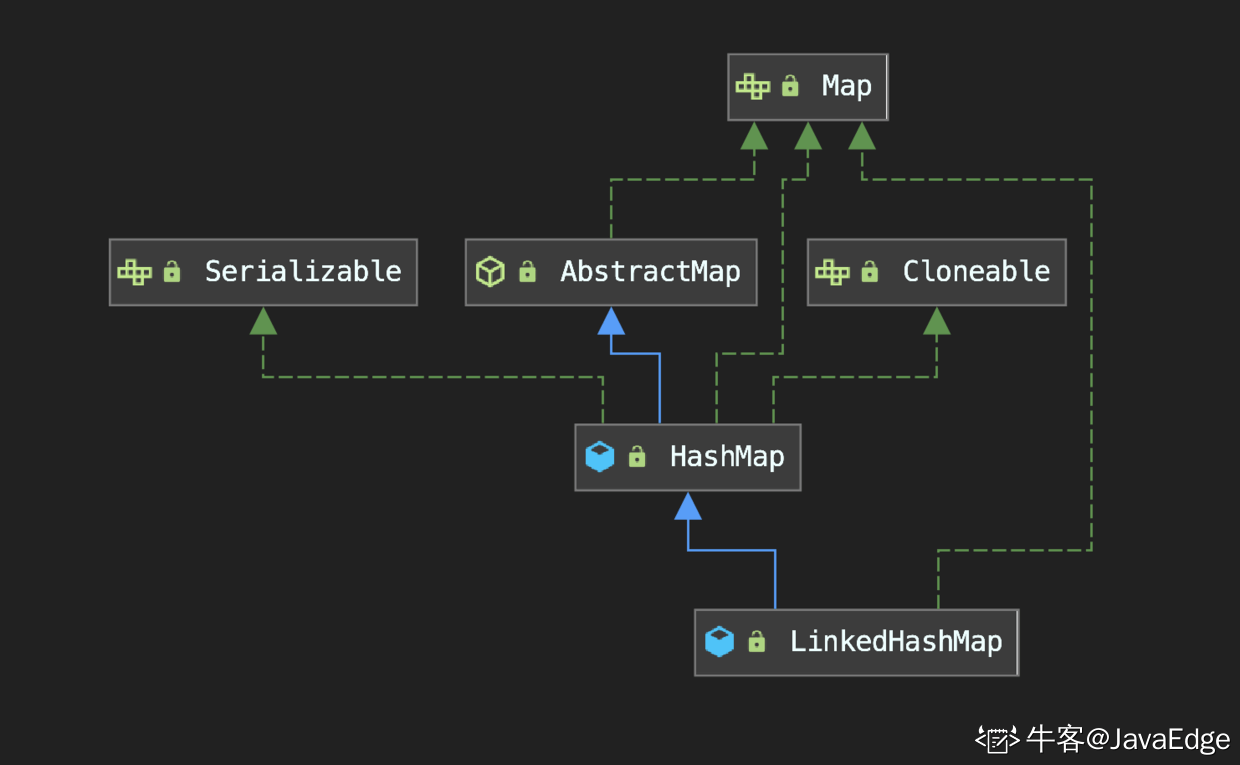
繼承自 HashMap ,因此 HashMap 擁有的榮耀它也都有.

雙向鏈表的頭(最老)

雙鏈表的末尾(最小)

HashMap.Node的子類:常規 LinkedHashMap 節點,增加了 before 和 after 屬性,維護雙向鏈表的結構

此 LinkedHashMap 的迭代排序方法:
true: 訪問順序
false(默認): 插入順序

構造方法都是先執行父類 HashMap 的構造方法.
構造一個空的維護插入順序的LinkedHashMap實例,其默認初始容量(16)和負載因子(0.75).

構造一個空的LinkedHashMap實例,可自己指定初始容量,負載因子和排序模式.

構造一個維護插入順序的LinkedHashMap實例,該實例具有與指定map相同的映射關系,創建的LinkedHashMap實例具有默認的加載因子(0.75)和足以容納指定map中映射的初始容量.

下面我們開始研究該類的主要特性是如何通過代碼實現的.
LinkedHashMap 默認 accessOrder 為 false,提供按照插入順序的訪問,并沒有重寫父類 HashMap 的 put 方法.但在 HashMap 中,put 的是 HashMap 的 Node 類型節點,LinkedHashMap 的 Entry 與其結構并不同,又是怎樣建立起雙向鏈表的呢?下面一起看下 LinkedHashMap 插入相關代碼.
忽略未重寫的 put=>putValue代碼部分,我們直接觀察重寫的
HashMap

LinkedHashMap 重寫

控制新增節點追加到鏈表的尾部,這樣每次新節點都追加到尾部,即可保證插入順序了.
繼續研究 linkNodeLast
新增節點,并追加到鏈表的尾部.
`// link at the end of list`
`private` `void` `linkNodeLast(LinkedHashMap.Entry<K,V> p) {`
`LinkedHashMap.Entry<K,V> last = tail;`
`// 新增于尾節點`
`tail = p;`
`// last 為null,說明鏈表為空`
`if` `(last == ``null``)`
`head = p;`
`// 鏈表非空,建立新節點和上一個尾節點的前后關系`
`else` `{`
`// 將新節點 p 直接接在鏈尾`
`p.before = last;`
`last.after = p;`
`}`
`}`由此得知,通過在 HashMap 基礎上新增的頭尾節點,節點的 before 和 after 屬性,就能實現在每次新增時,把節點直接追加到尾節點,即可達到維護按照插入順序的鏈表結構的目的!
圖解鏈表創建步驟
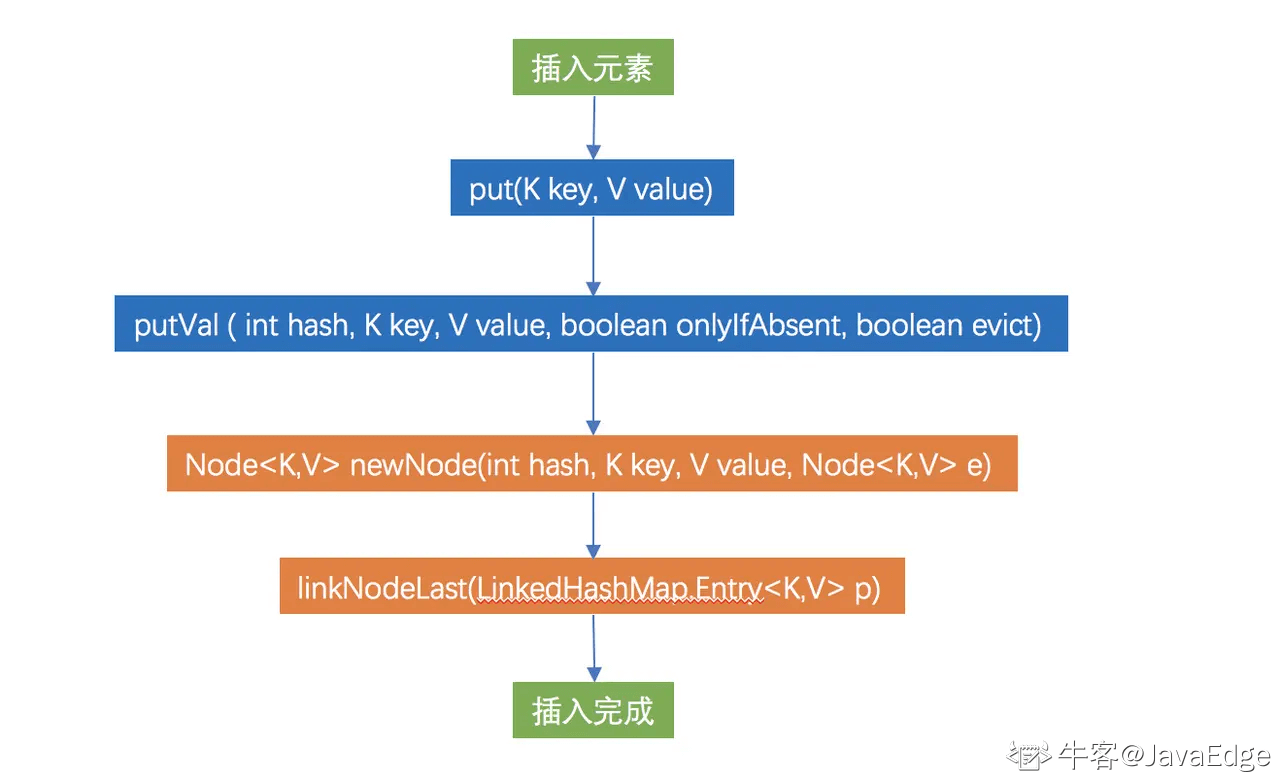
藍色部分是 HashMap 的方法
橙色部分為 LinkedHashMap 獨有方法
注意 LinkedHashMap 雖然也是雙向鏈表,但只提供單向的按插入的順序從頭到尾訪問,不及 LinkedList 般可雙向無死角訪問.
LinkedHashMap 通過迭代器訪問,而且默認是從頭節點開始訪問
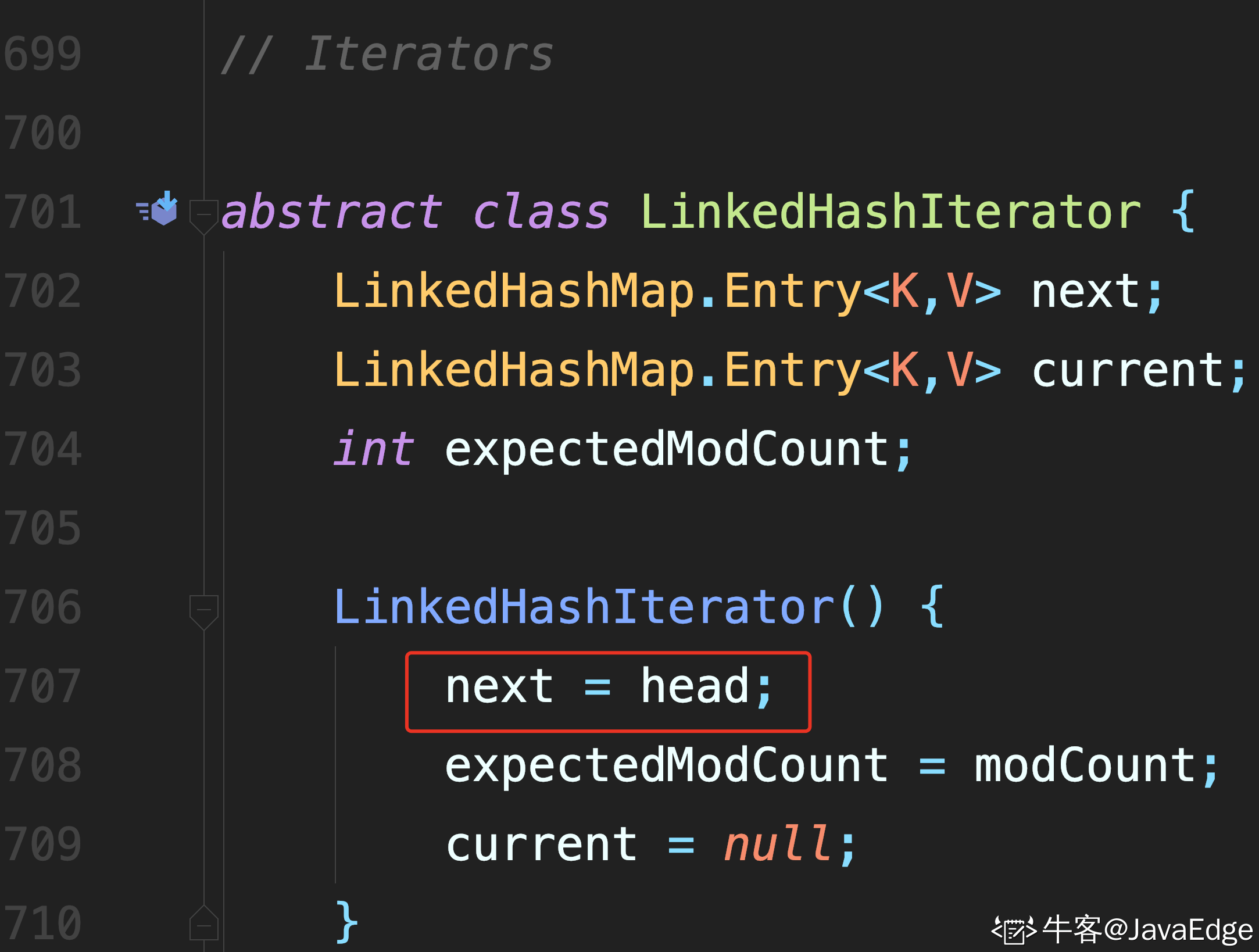
迭代過程中,不斷訪問 after 節點即可完成遍歷.
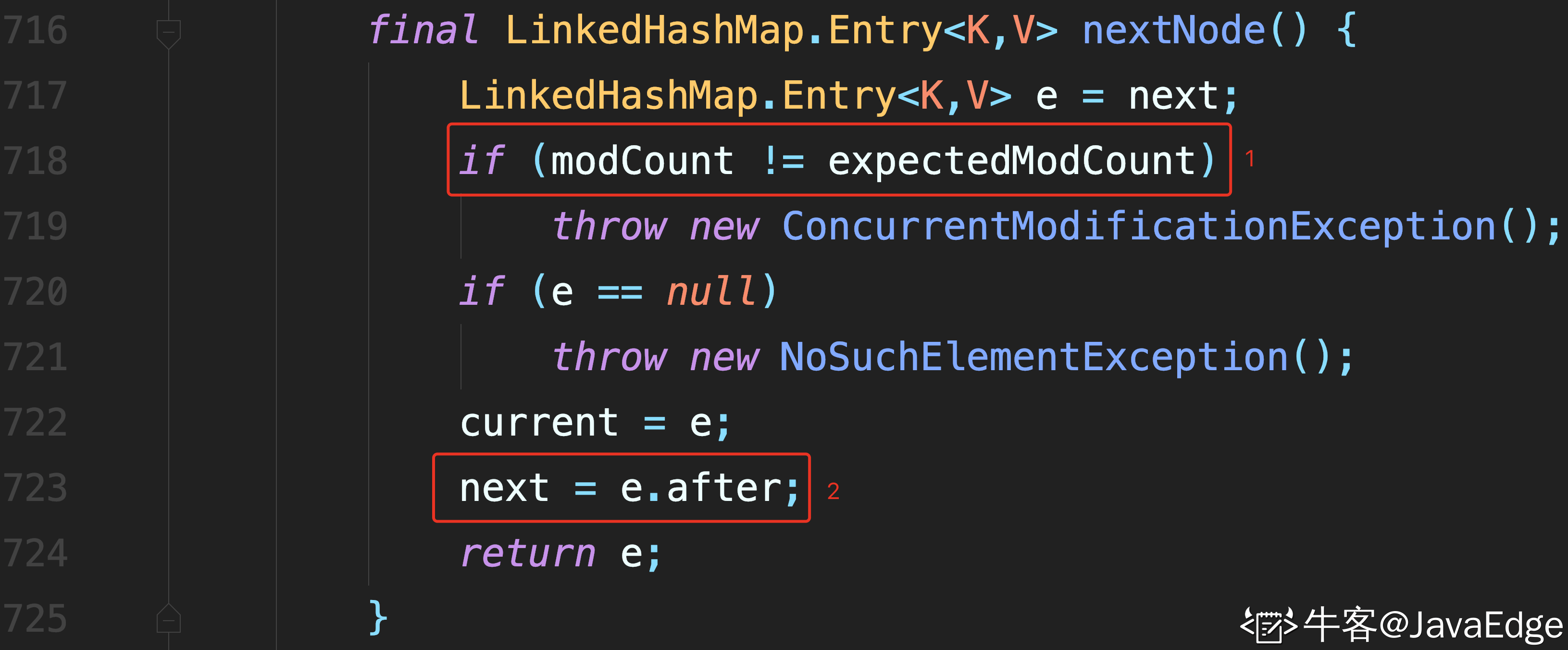
1 處進行校驗
2 處通過節點的 after 屬性,找到后繼節點
HashMap 中保存的允許 LinkedHashMap 后處理的回調

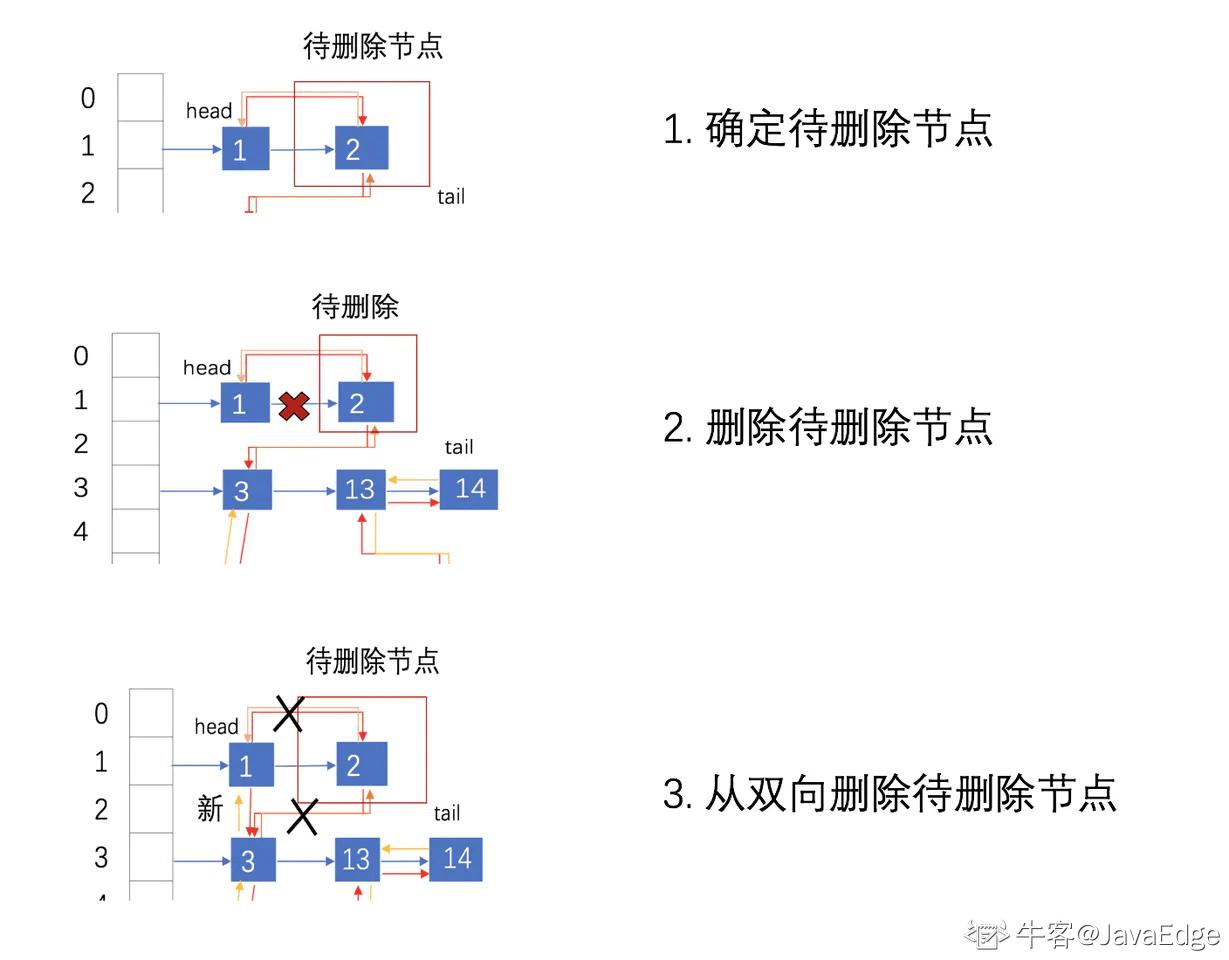
與插入操作一樣,LinkedHashMap 刪除操作相關的代碼也是直接用父類的實現. 在刪除節點時,父類不會修復 LinkedHashMap 的雙向鏈表。那么刪除及節點后,被刪除的節點該如何從雙鏈表中安全移除呢?其實在刪除節點后,回調方法 afterNodeRemoval 會被調用。LinkedHashMap 重寫了該方法.
`// e 為已經刪除的節點`
`void` `afterNodeRemoval(Node<K,V> e) { ``// unlink`
`LinkedHashMap.Entry<K,V> p =`
`(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;`
`// 將 p 節點的前驅后后繼引用置 null,輔助 GC`
`p.before = p.after = ``null``;`
`// p.before 為 null,表明 p 是頭節點`
`if` `(b == ``null``)`
`head = a;`
`else`
`// 否則將 p 的前驅節點連接到 p 的后繼節點`
`b.after = a;`
`// a 為 null,表明 p 是尾節點`
`if` `(a == ``null``)`
`tail = b;`
`else`
`// 否則將 a 的前驅節點連接到 b`
`a.before = b;`
`}`刪除元素的主要流程:
根據 hash 定位到桶位置
遍歷鏈表或調用紅黑樹相關的刪除方法
從 LinkedHashMap 維護的雙鏈表中移除要刪除的節點
轉存失敗重新上傳取消
經常訪問的元素會被追加到隊尾,這樣不經常訪問的數據自然就靠近隊頭,然后可以通過設置刪除策略,比如當 Map 元素個數大于多少時,把頭節點刪除
get 時,元素會被移動到隊尾:

`public` `V get(Object key) {`
`Node<K,V> e;`
`// 調用 HashMap get 方法`
`if` `((e = getNode(hash(key), key)) == ``null``)`
`return` `null``;`
`// 如果設置了 LRU 策略`
`if` `(accessOrder)`
`// 這個方法把當前 key 移動到隊尾`
`afterNodeAccess(e);`
`return` `e.value;`
`}`從上述源碼中,可以看到,通過 afterNodeAccess 方法把當前訪問節點移動到了隊尾,其實不僅僅是 get 方法,執行 getOrDefault、compute、computeIfAbsent、computeIfPresent、merge 方法時,也會這么做,通過不斷的把經常訪問的節點移動到隊尾,那么靠近隊頭的節點,自然就是很少被訪問的元素了。
以上是“java中LinkedHashMap的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





