溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文主要給大家介紹 MySQL大數據如何優化及分解,其所涉及的東西,從理論知識來獲悉,有很多書籍、文獻可供大家參考,從現實意義角度出發,億速云累計多年的實踐經驗可分享給大家。
公司中的數據過大或者訪問量過多都會導致數據庫的性能降低,過多的損耗磁盤i/o和其他云服務器的性能,嚴重會導致宕機。根據這種情況我們給出了解決方法,那么接下來我們繼續:
上次說到了分表和分區:首先讓我們回顧下分表和分區的區別:
分表:
將一個大表分解成若干個小表,每個小表都有獨立的文件.MYD/.MYI/.frm三個文件
分區:
將存放數據的數據塊變多了,表還是一張大表,在后面會有一個總結。
講到分區了上次,這次主要還是分區的內容;分區主要包括五個分區類型:
1):range分區:
把連續區間的列值分配給分區,而且這些區間不能相互重疊,
那么我們就舉個例子來驗證下,range分區和未分區的不同之處:{性能比拼}
首先創建一個未分區的庫和表
MySQL>create database test;
mysql> create table test.tab1(c1 int,c2 varchar(30),c3 date);

接下來創建一個分區的表,按照年份進行拆分
mysql> use test
mysql> CREATE TABLE tab2 ( c1 int, c2 varchar(30) , c3 date )
PARTITION BY RANGE (year(c3)) (PARTITION p0 VALUES LESS THAN (1995),
PARTITION p1 VALUES LESS THAN (1996) , PARTITION p2 VALUES LESS THAN (1997) ,
PARTITION p3 VALUES LESS THAN (1998) , PARTITION p4 VALUES LESS THAN (1999) ,
PARTITION p5 VALUES LESS THAN (2000) , PARTITION p6 VALUES LESS THAN (2001) ,
PARTITION p7 VALUES LESS THAN (2002) , PARTITION p8 VALUES LESS THAN (2003) ,
PARTITION p9 VALUES LESS THAN (2004) , PARTITION p10 VALUES LESS THAN (2010),
PARTITION p11 VALUES LESS THAN MAXVALUE );
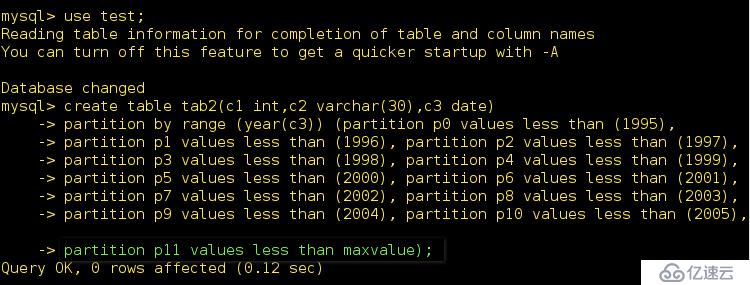
最后一行表示有可能在插入年份數據比2005大的數據可以插入,如果沒有將會出錯
剛才創建的兩個表tab1和tab2沒有數據只有一個空表;接下來為它們插入數據;
多一點,不然看不出效果;1000000條數據
創建存儲過程,需要使用界定符
mysql> delimiter &&//指定存儲過程結束符
mysql>CREATE PROCEDURE load_part_tab()
begin
declare x int default 0;
while x < 1000000
do
insert into test.tab1
values (x,'testing partitions',adddate('1995-01-01',(rand(x)*36520) mod 3652));
set x = x + 1;
end while;
end
&&
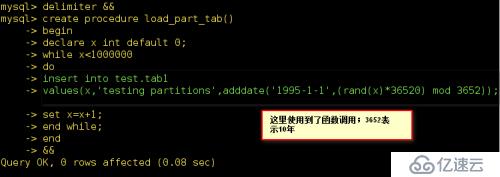
rand()函數在0和1之間的隨機數,如果rand(n)中的n被指定,它將作為一個值,再次不做過多的敘述;大家可以查看相關的資料
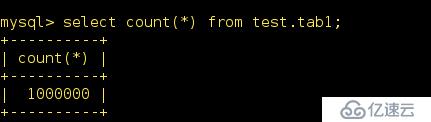
將load_part_tab向test.tab1表中插入1000000條數據

查看一下是否插入成功
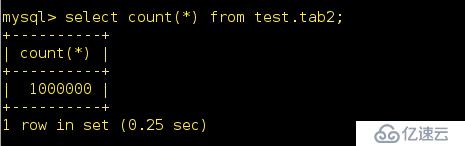
接下來向tab2表中也插入1000000條的數據
mysql> insert into test.tab2 select * from test.tab1;

注:這條sql語句屬于嵌套式,將后面執行的結果交給前面的執行
查看一下是否成功;
接下來讓我們拭目以待;測試sql性能:
tab1表的查詢:
mysql> select count(*) from test.tab1 where c3 > '1995-01-01' and c3 < '1995-12-31';

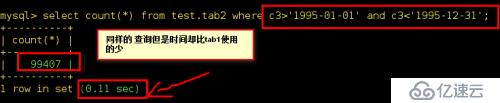
tab2表的查詢:
mysql>select count(*) from test.tab2 where c3 > '1995-01-01' and c3 < '1995-12-31';
通過explain語句來分析下它們的執行情況:


結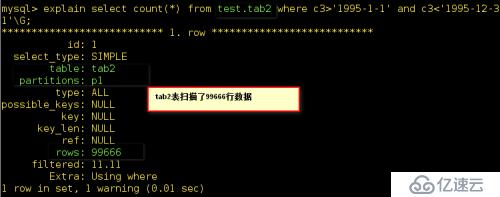 果表明分區的效果要比為分區的效果好太多了。既然這樣我們就現在這個前題之下為tab1
果表明分區的效果要比為分區的效果好太多了。既然這樣我們就現在這個前題之下為tab1
表和tab2表創建索引,看看它們的效果如何:
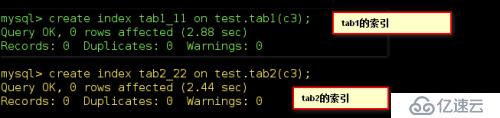
刷新下表的緩存,進行查詢:
tab1表查詢如下

tab2表的查詢如下;

由此結果可見索引創建之后還是分區后的速度快,但是結果相差不大,但是如果數據結構復雜,數據量龐大的情況之下,結果會越發的顯著
不知道大家看明白了沒有,如果沒有我們在舉個例子,主要因為range分區在工作中使用較多,所以再次在舉個例子:
mysql>create database test2
mysql> CREATE TABLE employees ( ==========>創建一個employees表
id INT NOT NULL, ========> ID號為×××不能為空
fname VARCHAR(30), ===========>姓氏
lname VARCHAR(30), ===========>名字
hired DATE NOT NULL DEFAULT '1970-01-01', ==========> 雇傭的日期,不能為空
separated DATE NOT NULL DEFAULT '9999-12-31', ==========>離開的日期,不能為空
job_code INT NOT NULL, =============> 員工職務的工號,不能為空
store_id INT NOT NULL ===========> 商店ID號,不能為空
)
partition BY RANGE (store_id) ( ============> 分區范圍以商店ID為準
partition p0 VALUES LESS THAN (6), =========> p0包括小于6的id號
partition p1 VALUES LESS THAN (11), ===========>p1包括小于11ID號
partition p2 VALUES LESS THAN (16), ============>p2包括小于16ID號
partition p3 VALUES LESS THAN (21) ===============>p3包括小于21的ID號
);

上面的分區方式說明了商店1-5號;工作的員工都被保存在了p0區域當中,6-11的商店員工被保存在了p1區域中,其他的一次類推;
但是需要注意的是,如果從其他地方區域調來了一個員工如(81,‘lll’,‘xxff’,‘1998-06-25’,‘2001-26-25’,25,13)是否可以加入呢? 當然可以而且還是p2區域,這要查看他的商店id號為13,所以可以。那么我們來驗證一下OK

插入成功
那如果又有一個商店ID號為25的員工是否能加入呢?

插入失敗,由于沒有規則把store_id大于20的商店包含在內,服務器將不知道把該行保存在何處,將會導致錯誤。要避免這種錯誤,可以創建maxvalue分區,所有不在指定范圍內的記錄都會被存儲到maxvalue所在的分區中。
我們可以通過sql語句修改次分區:
mysql> alter table employees add partition (partition p4 values less than maxvalue);
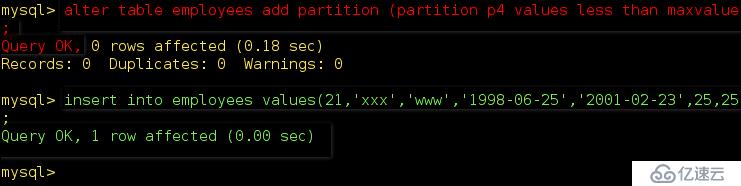
可以看出修改之后的分區來自商店ID為25的員工可以加入。
介紹了range分區,那么我們進行個總結對range:
基于屬于一個給定連續區間的列值,把多行分配給分區。這些區間要連續且不能相互重疊
而且在最后的區域中設置maxvalue防止大于區域的內容無法插入。
2)list分區;
比較類似range分區,區別在于range的值是連續的,而list是散值集合在一個行中,或許大家聽的不太明白,一會給大家舉個例子看下。
LIST分區通過使用“PARTITION BY LIST(expr)”來實現,其中“expr” 是某列值或一個基于某個列值、并返回一個整數值的表達式,然后通過“VALUES IN (value_list)”的方式來定義每個分區,其中“value_list”是一個通過逗號分隔的整數列表。
我們還以商店這個例子為大家進行演示,正好和range進行對比:
首先創建庫
mysql> create database tty;

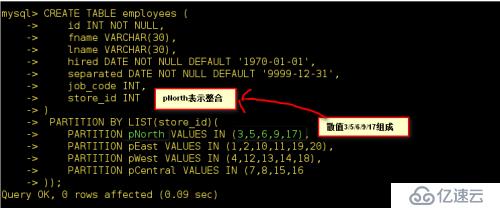
這樣在表中增加或者刪除制定區域的員工記錄變得容易起來,假如說pNorth商店倒閉了現在需要將員工記錄全部刪掉可以使用“ALTER TABLE employees DROP PARTITION pWest;”來進行刪除,它與具有同樣作用的DELETE (刪除)查詢“DELETE query DELETE FROM employees WHERE store_id IN (4,12,13,14,18);”比起來,要有效得多。
接下來為大家介紹下另外的三種分區方式:作為了解
3)HASH分區;
這種模式允許DBA通過對表的一個或多個列的Hash Key進行計算,最后通過這個Hash碼不同數值對應的數據區域進行分區。
hash分區的目的是將數據均勻的分布到預先定義的各個分區中,保證各分區的數據量大致一致。分區中; MYSQL自動完成這些工作,用戶所要定一個列值或者表達式,以及指定被分區的表將要被分割成的分區數量。
接下來舉例說明:
mysql> create table t_hash( a int(11), b datetime) partition by hash(year(b)) partitions 4;

接下來插入點數據,讓我們來驗證下:

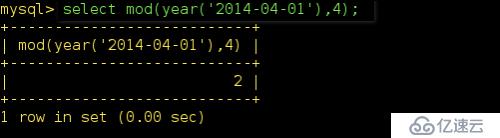
那么看一下MySQL自動會將這條數據插入到那個分區呢?
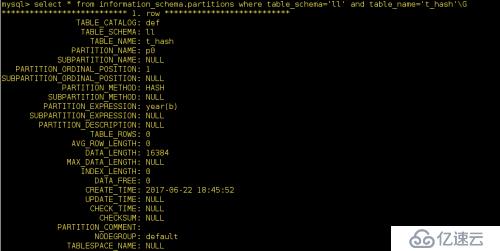
我們還可以通過系統數據庫information_schema查看下ll庫中的t_hash表的樹形結構:
前期應為創建了4個分區所以這里會顯示4個
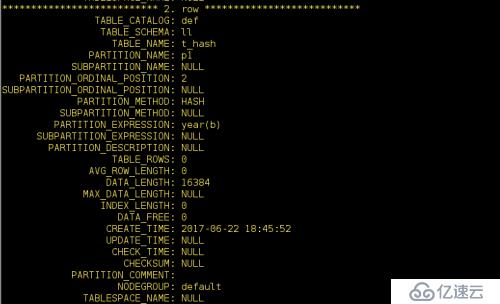
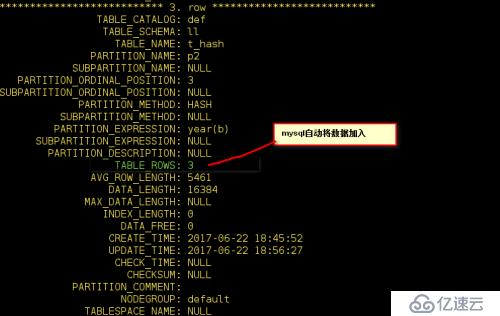
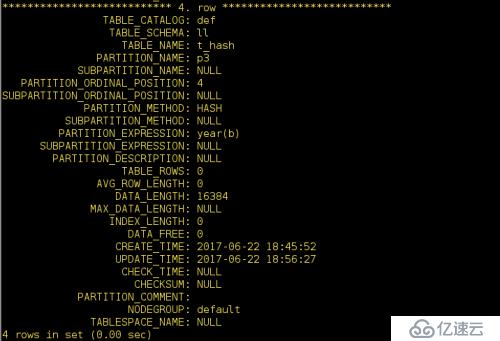
這里只有p2表當中有數據,其他的三個都沒有數據
4)key分區:
key分區和hash分區相似,不同在于hash分區是用戶自定義函數進行分區,key分區使用mysql數據庫提供的函數進行分區,對于其他存儲引擎mysql使用內部的hash函數。
創建的sql語句為:
mysql> create table t_key( a int(11), b datetime) partition by key(b) partitions 4;

為其插入一條sql語句:

我們看一下

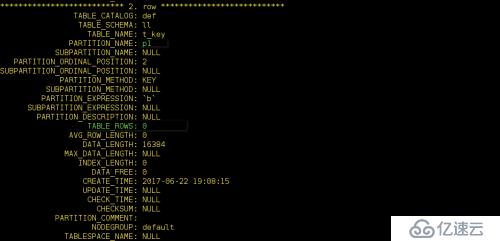
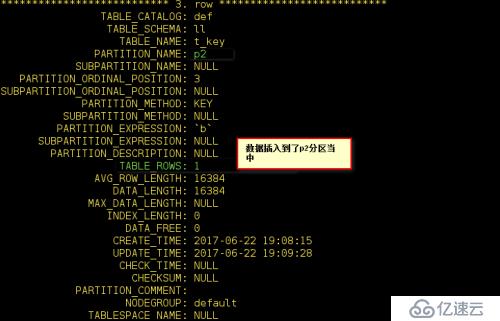
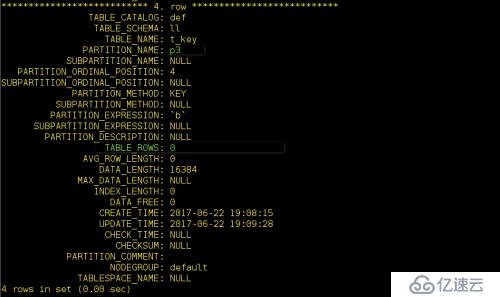
上面的RANGE、LIST、HASH、KEY四種分區中,分區的條件必須是×××,如果不是×××需要通過函數將其轉換為×××。
5)columns分區
mysql-5.5開始支持COLUMNS分區,可視為RANGE和LIST分區的進化,COLUMNS分區可以直接使用非×××數據進行分區。COLUMNS分區支持以下數據類型:
所有×××,如INT SMALLINT TINYINT BIGINT。FLOAT和DECIMAL則不支持。
日期類型,如DATE和DATETIME。其余日期類型不支持。
字符串類型,如CHAR、VARCHAR、BINARY和VARBINARY。BLOB和TEXT類型不支持。
COLUMNS可以使用多個列進行分區。
最后為大家做一個完整的總結;從不同方面介紹分表和分區的不同之處
mysql分表和分區有什么區別呢
1、實現方式上
a) mysql的分表是真正的分表,一張表分成很多表后,每一個小表都是完整的一張表,都對應三個文件,一個.MYD數據文件,.MYI索引文件,.frm表結構文件。
b) 分區不一樣,一張大表進行分區后,他還是一張表,不會變成二張表,但是他存放數據的區塊變多了
2、數據處理上
a)分表后,數據都是存放在分表里,總表只是一個外殼,存取數據發生在一個一個的分表里面。
b)分區呢,不存在分表的概念,分區只不過把存放數據的文件分成了許多小塊,分區后的表呢,還是一張表,數據處理還是由自己來完成。
3、提高性能上
a)分表后,單表的并發能力提高了,磁盤I/O性能也提高了。并發能力為什么提高了呢,因為查尋一次所花的時間變短了,如果出現高并發的話,總表可以根據不同的查詢,將并發壓力分到不同的小表里面。
b)mysql提出了分區的概念,主要是想突破磁盤I/O瓶頸,想提高磁盤的讀寫能力,來增加mysql性能。
在這一點上,分區和分表的測重點不同,分表重點是存取數據時,如何提高mysql并發能力上;而分區呢,如何突破磁盤的讀寫能力,從而達到提高mysql性能的目的。
4、實現的難易度上
a)分表的方法有很多,用merge來分表,是最簡單的一種方式。這種方式跟分區難易度差不多,并且對程序代碼來說可以做到透明的。如果是用其他分表方式就比分區麻煩了。
b)分區實現是比較簡單的,建立分區表,根建平常的表沒什么區別,并且對開代碼端來說是透明的。
mysql分表和分區有什么聯系?
1.都能提高mysql的性高,在高并發狀態下都有一個良好的表現。
2.分表和分區不矛盾,可以相互配合的,對于那些大訪問量,并且表數據比較多的表,我們可以采取分表和分區結合的方式,訪問量不大,但是表數據很多的表,我們可以采取分區的方式等。
3.分表技術是比較麻煩的,需要手動去創建子表,app服務端讀寫時候需要計算子表名。采用merge好一些,但也要創建子表和配置子表間的union關系。
4.表分區相對于分表,操作方便,不需要創建子表。
看了以上 MySQL大數據如何優化及分解介紹,希望能給大家在實際運用中帶來一定的幫助。本文由于篇幅有限,難免會有不足和需要補充的地方,大家可以繼續關注億速云行業資訊板塊,會定期給大家更新行業新聞和知識,如有需要更加專業的解答,可在官網聯系我們的24小時售前售后,隨時幫您解答問題的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





