溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關MySQL大數據查詢性能優化的示例,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
MySQL性能優化包括表的優化與列類型選擇,表的優化可以細分為什么? 1、定長與變長分離;2、常用字段與不常用字段要分離; 3、在1對多,需要關聯統計的字段上添加冗余字段。
一、表的優化與列類型選擇
表的優化:
1、定長與變長分離
如 id int,占4個字節,char(4)占4個字符長度,也是定長,time即每一單元值占的字節是固定的。
核心且常用字段,宜建成定長,放在一張表。
而varchar,text,blob這種變長字段,適合單放一張表,用主鍵與核心表關聯起來。
2、常用字段與不常用字段要分離
需要結合網站具體的業務來分析,分析字段的查詢場景,查詢頻率低的字段,單拆出來。
3、在1對多,需要關聯統計的字段上添加冗余字段。
看如下的效果:
每個版塊里,有N條帖子,在首頁顯示了版塊信息和版塊下的帖子數。
這是如何做的

如果board表只有前2列,則需要取出版塊后,
再查post表,select count(*) from post group by board_id,得出每個版塊的帖子數。
二、列類型選擇
1、字段類型優先級
整型>date
time>enum
char>varchar>blob,text
整型:定長,沒有國家/地區之分,沒有字符集的差異。比如:
tinyint 1,2,3,4,5 <--> char(1) a,b,c,d,e
從空間上,都占1個字節,但是 order by 排序,前者快。原因,或者需要考慮字符集與校對集(就是排序規則);
time定長,運算快,節省空間。考慮時區,寫sql時不方便 where > `2018-08-08`;
enum,能起到約束的目的,內部用整型來存儲,但與cahr聯查時,內部要經歷串與值的轉化;
char定長,考慮字符集和(排序)校對集;
varchar不定長,要考慮字符集的轉換與排序時的校對集,速度慢;
text/blob 無法使用內存臨時表(排序等操作只能在磁盤上進行)
附:關于date/time的選擇,大師的明確意見,直接選 int unsgined not null,存儲時間戳。
例如:
性別:以utf8為例
char(1) ,3個字長字節
enum('男','女'); 內部轉成數字來存,多一個轉換過程
tinyint(), 定長1個字節
2、夠用就行,不要慷慨(如 smallint varchar(N))
原因:大的字節浪費內存,影響速度。
以年齡為例 tinyint unsigned not null,可以存儲255歲,足夠。用int浪費了3個字節;
以varchar(10),varchar(300)存儲的內容相同,但在表聯查時varchar(300)要花更多內存。
3、盡量避免用NULL()
原因:NULL不利于索引,要用特殊的字符來標注。
在磁盤上占據的空間其實更大(MySQL5.5已對null做的改進,但查詢仍是不便)
三、索引優化策略
1、索引類型
1.1 B-tree索引
名叫btree索引,大的方面看,都用的平衡樹,但具體的實現上,各引擎稍有不同,比如,嚴格的說,NDB引擎,使用的是T-tree.
但抽象一下 B-tree系統,可理解為“排好序的快速查詢結構”。
1.2 hash索引
在memory表里默認是hash索引,hash的理論查詢時間復雜度為O(1)。
疑問:既然hash的查找如此高效,為什么不都用hash索引?
回答:
1、hash函數計算后的結果,是隨機的,如果是在磁盤上放置數據,以主鍵為id為例,那么隨著id的增長,id對應的行,在磁盤上隨機放置。
2、無法對范圍查詢進行優化。
3、無法利用前綴索引,比如在btree中,field列的值“helloworld”,并加索引查詢 x=helloworld自然可以利用索引,x=hello也可以利用索引(左前綴索引)。
4、排序也無法優化。
5、必須回行,就是說通過索引拿到數據位置,必須回到表中取數據。
2、btree索引的常見誤區
2.1 在where條件常用的列上加索引,例如:
where cat_id = 3 and price>100;查詢第三個欄目,100元以上的商品。
誤區:cat_id 上和price上都加上索引。
錯:只能用上cat_id 或 price索引,因為是獨立的索引,同時只能用一個。
2.2 在多列上建立索引后(聯合索引),查詢哪個列,索引都會將發揮作用
誤區:多列索引上,索引發揮作用,需要滿足左前綴要求。
以 index(a,b,c) 為例,(注意和順序有關)
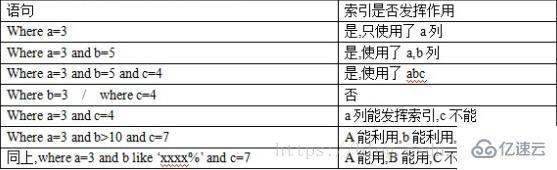
四、索引實驗
例如:select * from t4 where c1=3 and c2 = 4 and c4>5 and c3=2;
用到了哪些索引:
explain select * from t4 where c1=3 and c2 = 4 and c4>5 and c3=2 \G
如下:
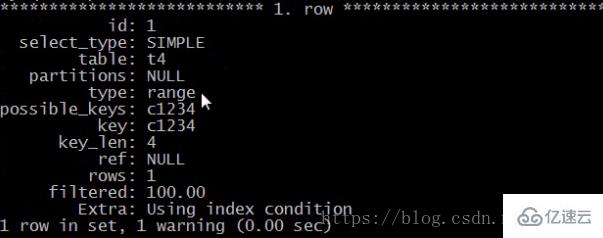
注:(key_len : 4 )
五、聚簇索引與非聚簇索引
Myisam與innodb引擎,索引文件的異同
Myisam:由news.myd和new.myi兩個文件,索引文件和數據文件是分開的,叫非聚簇索引。主索引和次索引都指向物理行(磁盤的位置)
innodb:索引和數據是聚在一起的,所以是聚簇索引。innodb的主索引文件上直接存放該行數據,次索引指向對主鍵索引的引用。
注意:innodb來說:
1、主鍵索引 即存放索引值,又在葉子中存儲行的數據。
2、如果沒有主鍵(primary key),則會unique key做主鍵。
3、如果沒有unique,則系統生成一個內部的rowid做主鍵。
4、像innodb中,主鍵的索引結構中,即存儲了主鍵值又存儲了行數據,這種結構稱為聚簇索引。
聚簇索引
優勢:根據主鍵查詢條目比較少時,不用回行(數據就在主鍵節點下)
劣勢:如果碰到不規則數據插入時,造成頻繁的頁分裂
關于“MySQL大數據查詢性能優化的示例”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





