溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Java阻塞隊列SynchronousQueue實例分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Java阻塞隊列SynchronousQueue實例分析”吧!
分析
其實SynchronousQueue 是一個特別有意思的阻塞隊列,就我個人理解來說,它很重要的特點就是沒有容量。
直接看一個例子:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
/**
* @author Dongguabai
* @description
* @date 2021-09-01 21:52
*/
public class TestSynchronousQueue {
public static void main(String[] args) {
SynchronousQueue synchronousQueue = new SynchronousQueue();
boolean add = synchronousQueue.add("1");
System.out.println(add);
}
}代碼很簡單,就是往 SynchronousQueue 里放了一個元素,程序卻拋異常了:
Exception in thread "main" java.lang.IllegalStateException: Queue full at java.util.AbstractQueue.add(AbstractQueue.java:98) at dongguabai.test.juc.test.TestSynchronousQueue.main(TestSynchronousQueue.java:14)
而異常原因是隊列滿了。剛剛使用的是 SynchronousQueue#add 方法,現在來看看 SynchronousQueue#put 方法:
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
synchronousQueue.put("1");
System.out.println("----");
}看到 InterruptedException 其實就能猜出這個方法肯定會阻塞當前線程。
通過這兩個例子,也就解釋了 SynchronousQueue 隊列是沒有容量的,也就是說在往 SynchronousQueue 中添加元素之前,得先向 SynchronousQueue 中取出元素,這句話聽著很別扭,那可以換個角度猜想其實現原理,調用取出方法的時候設置了一個“已經有線程在等待取出”的標識,線程等待,然后添加元素的時候,先看這個標識,如果有線程在等待取出,則添加成功,反之則拋出異常或者阻塞。
接下來從 SynchronousQueue#put 方法開始進行分析:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}可以發現是調用的 Transferer#transfer 方法,這個 Transferer 是在構造 SynchronousQueue 的時候初始化的:
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}SynchronousQueue 有兩種模式,公平與非公平,默認是非公平,非公平使用的就是 TransferStack,是基于單向鏈表做的:
static final class SNode {
volatile SNode next; // next node in stack
volatile SNode match; // the node matched to this
volatile Thread waiter; // to control park/unpark
Object item; // data; or null for REQUESTs
int mode;
...
}那么重點就是 SynchronousQueue.TransferStack#transfer 方法了,從方法名都可以看出這是用來做數據交換的,但是這個方法有好幾十行,里面各種 Node 指針搞來搞去,這個地方我覺得沒必要過于糾結細節,老規矩,抓大放小,而且隊列這種,很方便進行 Debug 調試。
再理一下思路:
今天研究的是阻塞隊列,關注阻塞的話,更應該關系的是 take 和 put 方法;
Transferer 是一個抽象類,只有一個 transfer 方法,即 take 和 put 共用,那就肯定是基于入參進行功能的區分;
take 和 put 方法底層都調用的 SynchronousQueue.TransferStack#transfer 方法;
將上面 SynchronousQueue#put 使用的例子修改一下,再加一個線程take:
package dongguabai.test.juc.test;
import java.util.Date;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-01 21:52
*/
public class TestSynchronousQueue {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()->{
System.out.println(new Date().toLocaleString()+"::"+Thread.currentThread().getName()+"-put了數據:"+"1");
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
System.out.println("----");
new Thread(()->{
Object take = null;
try {
take = synchronousQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(new Date().toLocaleString()+"::"+Thread.currentThread().getName()+"-take到了數據:"+take);
}).start();
TimeUnit.SECONDS.sleep(1);
System.out.println("結束...");
}
}整個程序結束,并且輸出:
----
2021-9-2 0:58:55::Thread-0-put了數據:1
2021-9-2 0:58:55::Thread-1-take到了數據:1
結束...
也就是說當一個線程在 put 的時候,如果有線程 take ,那么 put 線程可以正常運行,不會被阻塞。
基于這個例子,再結合上文的猜想,也就是說核心點就是找到 put 的時候現在已經有線程在 take 的標識,或者 take 的時候已經有線程在 put,這個標識不一定是變量,結合 AQS 的原理來看,很可能是根據鏈表中的 Node 進行判斷。
接下來看 SynchronousQueue.put 方法:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}它底層也是調用的 SynchronousQueue.TransferStack#transfer 方法,但是傳入參數是當前 put 的元素、false 和 0。再回過頭看 SynchronousQueue.TransferStack#transfer 方法:
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
//這里的參數e就是要put的元素,顯然不為null,也就是說是DATA模式,根據注釋,DATA模式就說明當前線程是producer
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
if (h == null || h.mode == mode) { // empty or same-mode
if (timed && nanos <= 0) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {
//因為第一次put那么h肯定為null,這里入參timed為false,所以會到這里,執行awaitFulfill方法,根據名稱可以猜想出是一個阻塞方法
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // wait was cancelled
clean(s);
return null;
}
....
}這里首先會構造一個 SNode,然后執行 casHead 函數,其實最終棧結構就是:
head->put_e
就是 head 會指向 put 的元素對應的 SNode。
然后會執行 awaitFulfill 方法:
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel();
SNode m = s.match;
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0; //自旋機制
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
LockSupport.park(this); //阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}最終還是會使用 LockSupport 進行阻塞,等待喚醒。
已經大致過了一遍流程了,細節方面就不再糾結了,那么假如再put 一個元素呢,其實結合源碼已經可以分析出此時棧的結果為:
head-->put_e_1-->put_e
避免分析出錯,寫個 Debug 的代碼驗證一下:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-02 02:15
*/
public class DebugPut2E {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()-> {
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
TimeUnit.SECONDS.sleep(1);
new Thread(()-> {
try {
synchronousQueue.put("2");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}在 SynchronousQueue.TransferStack#awaitFulfill 方法的 LockSupport.park(this); 處打上斷點,運行上面的代碼,再看看現在的 head:
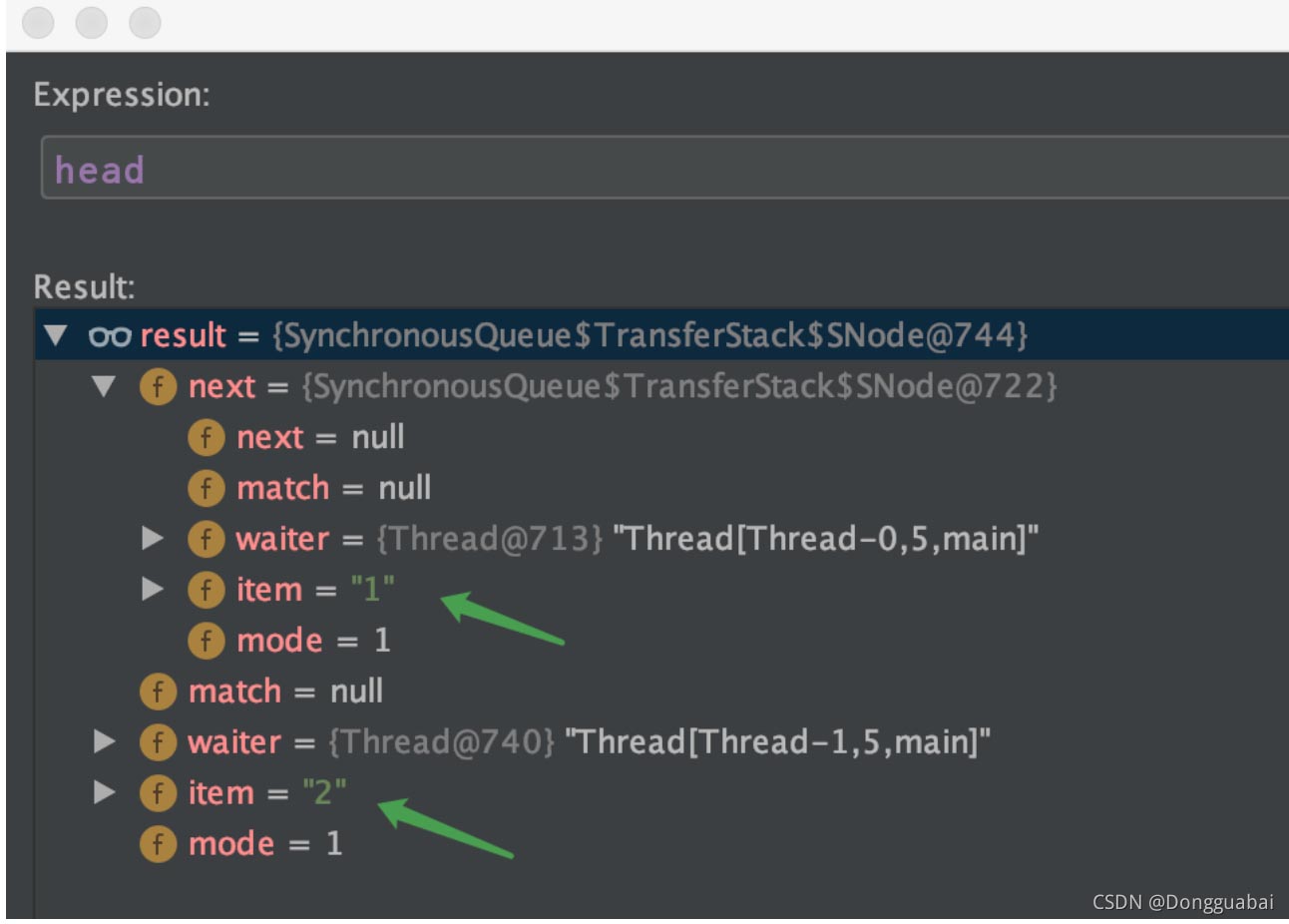
的確與分析的一致。
也就是先進后出。再看 take 方法:
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}調用的 SynchronousQueue.TransferStack#transfer 方法,但是傳入參數是 null、false 和 0。
偷個懶就不分析源碼了,直接 Debug 走一遍,代碼如下:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-02 02:24
*/
public class DebugTake {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()-> {
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-put-1").start();
TimeUnit.SECONDS.sleep(1);
new Thread(()-> {
try {
synchronousQueue.put("2");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-put-2").start();
TimeUnit.SECONDS.sleep(1);
new Thread(()->{
try {
Object take = synchronousQueue.take();
System.out.println("======take:"+take);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-Take").start();
}
}在 SynchronousQueue#take 方法中打上斷點,運行上面的代碼:
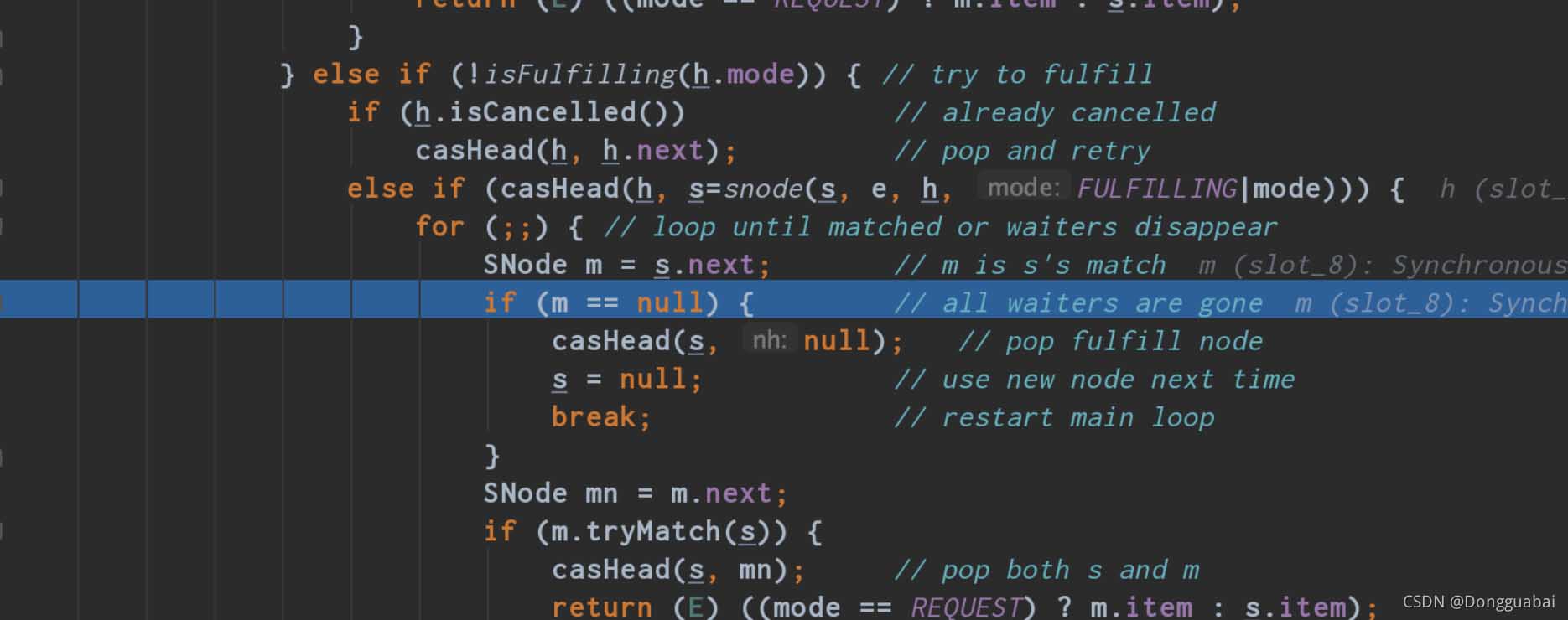
這里的 s 就是 head,m 就是棧頂的元素,也是最近一次 put 的元素。說白了 take 就是取的棧頂的元素,最后再匹配一下,符合條件就直接取出來。take 之后 head 為:
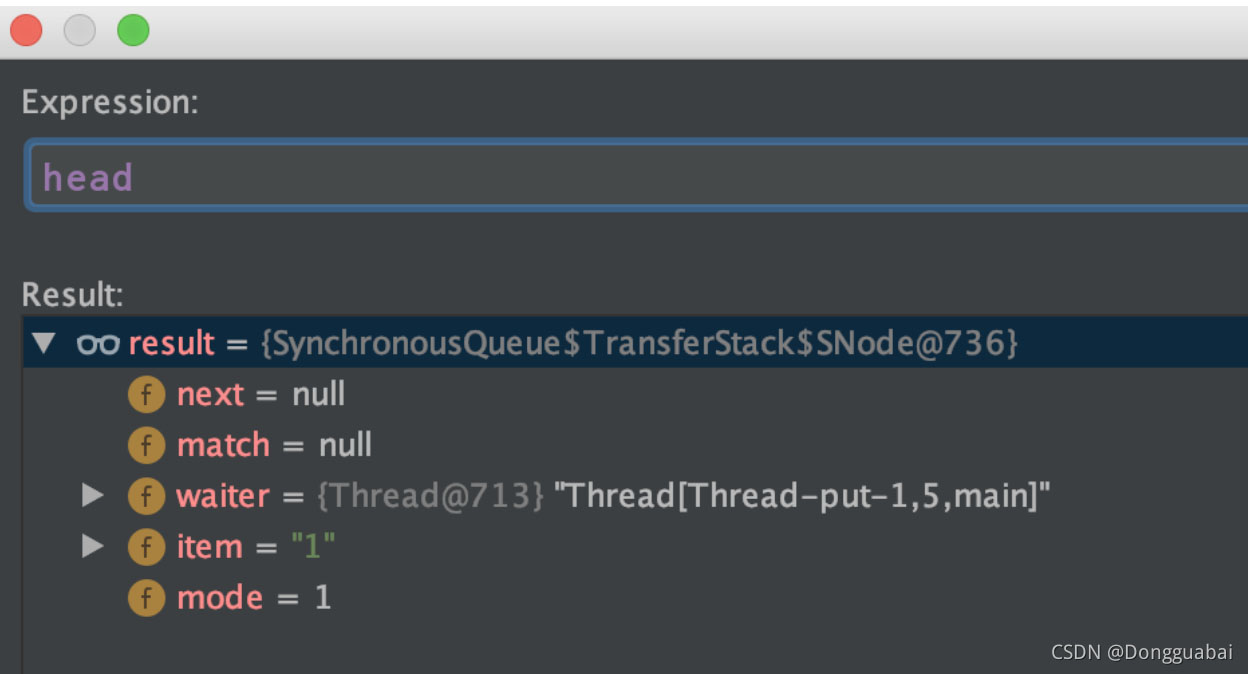
棧的結構為:
head-->put_e
最后再把整個流程梳理一遍:
執行 put 操作的時候,每次壓入棧頂;take 的時候就取棧頂的元素,即先進后出;這也就實現了非公平;
至于公平模式,結合 TransferStack 的實現,可以猜測實現就是 put 的時候放入隊列,take 的時候從隊列頭部開始取,先進先出。
那么這個隊列設計的優勢使用場景在哪里呢?個人感覺它的優勢就是完全不會產生對隊列中數據的爭搶,因為說白了隊列是空的,從某種程度上來說消費速率是很快的。
至于使用場景,我這邊的確沒有想到比較好的使用場景。結合組內同學的使用來看,他選擇使用這個隊列的原因是因為它不會在內存中生成任務隊列,當服務宕機后不用擔心內存中任務的丟失(非優雅停機的情況)。經過討論后發現即使使用了 SynchronousQueue 也無法有效的避免任務丟失,但這的確是一個思路,沒準以后在其他場景中用得上。
感謝各位的閱讀,以上就是“Java阻塞隊列SynchronousQueue實例分析”的內容了,經過本文的學習后,相信大家對Java阻塞隊列SynchronousQueue實例分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





