溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Java流中如何收集數據解析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
收集器的接口是java.util.stream.Collector,我們只需要調用流的collect方法并傳遞給一個Collector接口的一個實現(也就是給Stream中元素做匯總的方法),就可以了。例如java.util.stream.Collectors類的toList()方法,該方法就會返回一個按順序給每個元素生成一個列表的Collector接口的實現。
收集器非常有用,因為它可以簡介而靈活地定義collect用來生成結果集合的標準。更具體地說,對流調用collect方法將對流中的元素觸發一個規約操作(由Collector來參數化)。
JDK為我們提供了java.util.stream.Collectors類,其為我們提供了很多靜態工廠方法,可以方便地創建常見的收集器實例,而我們只要拿來用就可以了。最直接和最常用的收集器是toList靜態方法,它會把流中所有的元素收集到一個List中。
將流元素規約和匯總為一個值
元素分組
元素分區
注意:因為其為我們提供的都是靜態方法,我們可以通過靜態導入的方式簡化代碼的書寫。
Collectors為我們提供了counting方法,為我們提供了統計元素數量的收集器。實例:
long howManyDishes = menu.stream().collect(Collectors.counting());
上面的示例是利用預定義收集器實現的,其實Stream接口定義了count方法,因此我們也可以直接調用Stream提供的預定義方法來實現,如下:
long howManyDishes = menu.stream().count();
功能一樣用哪個才好呢?其實如果你的需求只是統計流中元素的數量的時候,二者皆可。最大的區別在于count()是一個終端操作,而counting返回的是一個收集器,其可以和其它收集器聯合使用。
Collectors為我們提供了maxBy方法和mixBy方法,為我們提供了計算流中的最大或最小值的收集器。實例:
Comparator<Dish> dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories); Optional<Dish> mostCalorieDish = menu.stream().collect(maxBy(dishCaloriesComparator));
求和
Collectors類專門為匯總提供了一個工廠方法: Collectors.summingInt。它可接受一個把對象映射為求和所需int的函數,并返回一個收集器;該收集器在傳遞給普通的collect方法后即執行我們需要的匯總操作。
類Collectors.summingLong和Collectors.summingDouble方法的作用完全一樣,可以用于求和字段為long或double的情況。
求出菜單列表的總熱量的示例:
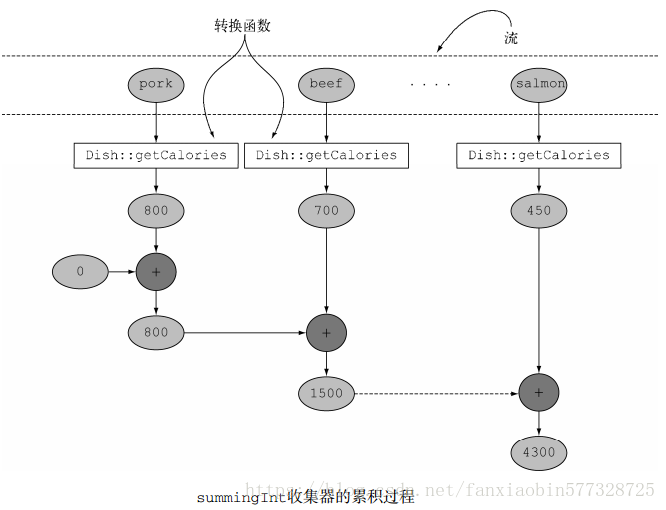
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
上面代碼的收集過程下圖所示。在遍歷流時,會把每一道菜都映射為其熱量,然后把這個數字累加到一個累加器(這里的初始值0)。
平均值
Collectors類的averagingInt、averagingLong 和 averagingDouble 可以為我們生成計算數值的平均數的收集器:
double avgCalories = menu.stream().collect(averagingInt(Dish::getCalories));
綜合匯總
Collectors類為我們提供了summarizingInt工廠方法,其返回的收集器可以一次性統計出總數、總和、平均值、最大值和最小值。
例如,通過一次summarizing操作你可以就數出菜單中元素的個數,并得到菜肴熱量總和、平均值、最大值和最小值:
IntSummaryStatistics menuStatistics = menu.stream().collect(summarizingInt(Dish::getCalories));
這個收集器會把所有這些信息收集到一個叫作IntSummaryStatistics的類里,它提供了方便的取值方法來訪問結果。打印menuStatisticobject會得到以下輸出:
IntSummaryStatistics{count=9, sum=4300, min=120, average=477.777778, max=800}同樣,相應的summarizingLong和summarizingDouble工廠方法有相關的LongSummaryStatistics 和DoubleSummaryStatistics 類 型 , 適用于收集的屬性是原始類型 long 或 double 的情況。
Collectors類為我們提供的joining工廠方法返回的收集器會把對流中每一個對象應用toString方法得到的所有字符串連接成一個字符串。
這意味著你把菜單中所有菜肴的名稱連接起來,如下所示:
String shortMenu = menu.stream().map(Dish::getName).collect(joining());
注意: joining在內部使用了StringBuilder來把生成的字符串逐個追加起來。
此外joining工廠方法有一個重載版本可以接受元素之間的分界符,這樣你就可以得到一個逗號分隔的菜肴名稱列表:
String shortMenu = menu.stream().map(Dish::getName).collect(joining(", "));廣義的規約匯總
前面所提及的收集器都是一個可以用reducing工廠方法定義的規約過程的特殊情況而已。Collectors.reducing工廠方法是所有這些特殊情況的一般化。
public static <T,U> Collector<T,?,U> reducing(U identity, Function<? super T,? extends U> mapper, BinaryOperator<U> op)
參數解析:
第一個參數時規約操作的起始值,也是流中沒有元素時的返回值。
第二個參數是Function,將做一定的轉換操作。
第三個參數BinaryOperator,將兩個項目累積成一個同類型的值。
我們將上面的示例轉換一下:
Comparator<Dish> dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories); Optional<Dish> mostCalorieDish = menu.stream().collect(maxBy(dishCaloriesComparator)); // 轉換 Optional<Dish> mostCalorieDish = menu.stream().collect(reducing( (d1,d2) -> d1.getCalories() > d1.getCalories() ? d1 : d2));
上面轉換示例中,我們使用的是一個單參數的reducing工廠方法創建的收集器,其可以看做是三個參數方法的特殊情況,它把流中的第一個項目作為起點,把恒等函數(即一個函數僅僅是返回其輸入參數)作為一個轉換函數。
一個常見的數據庫操作是根據一個或多個屬性對集合中的項目進行分組。
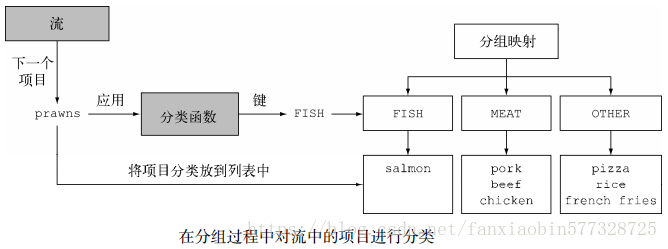
假設你要把菜單中的菜按照類型進行分類,有肉的放一組,有魚的放一組,其他的都放另一組。用Collectors.groupingBy工廠方法返回的收集器就可以輕松地完成這項任務,如下所示:
Map<Dish.Type, List<Dish>> dishesByType = menu.stream().collect(groupingBy(Dish::getType));
這里,你給groupingBy方法傳遞了一個Function(以方法引用的形式),它提取了流中每一道Dish的Dish.Type。我們把這個Function叫作分類函數,因為它用來把流中的元素分成不同的組。如下圖所示,分組操作的結果是一個Map,把分組函數返回的值作為映射的鍵,把流中所有具有這個分類值的項目的列表作為對應的映射值。在菜單分類的例子中,鍵就是菜的類型,值就是包含所有對應類型的菜肴的列表。
特殊應用示例:
public enum CaloricLevel{DIET,NORMAL,FAT}
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(groupingBy(dish -> {
if (dish.getCalories() <= 400)
return CaloricLevel.DIET;
else if (dish.getCalories() <= 700)
return CaloricLevel.NORMAL;
else
return CaloricLevel.FAT;
}));感謝各位的閱讀!關于“Java流中如何收集數據解析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





