溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“并發編程LongAdder的原理是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
一、前言
二、LongAdder類的使用
三、LongAdder原理的直觀理解
四、源碼分析
五、與AtomicInteger的比較
六、思想的抽象
ConcurrentHashMap的源碼采用了一種比較獨特的方式對map中的元素數量進行統計,自然是要好好研究一下其原理思想,同時也能更好地理解ConcurrentHashMap本身。
本文主要思路分為以下5個部分:
1.計數的使用效果
2.原理的直觀圖解
3.源碼的細節分析
4.與AtomicInteger的比較
5.思想的抽象
學習的入口自然是map的put方法
public V put(K key, V value) {
return putVal(key, value, false);
}查看putVal方法
這里并不對ConcurrentHashMap本身的原理作過多討論,因此我們直接跳到計數部分
final V putVal(K key, V value, boolean onlyIfAbsent) {
...
addCount(1L, binCount);
return null;
}每當成功添加一個元素之后,都會調用addCount方法進行數量的累加1的操作,這就是我們研究的目標
因為ConcurrentHashMap的設計初衷就是為了解決多線程并發場景下的map操作,因此在作數值累加的時候自然也要考慮線程安全
當然,多線程數值累加一般是學習并發編程的第一課,本身并非很復雜,可以采用AtomicInteger或者鎖等等方式來解決該問題
然而如果我們查看該方法,就會發現,一個想來應該比較簡單的累加方法,其邏輯看上去卻相當復雜
這里我只貼出了累加算法的核心部分
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
...
}我們就來研究一下該邏輯的實現思路。而這個思路其實是照搬了LongAdder類的邏輯,因此我們直接查看該算法的原始類
我們先看下LongAdder的使用效果
LongAdder adder = new LongAdder();
int num = 0;
@Test
public void test5() throws InterruptedException {
Thread[] threads = new Thread[10];
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
adder.add(1);
num += 1;
}
});
threads[i].start();
}
for (int i = 0; i < 10; i++) {
threads[i].join();
}
System.out.println("adder:" + adder);
System.out.println("num:" + num);
}輸出結果
adder:100000
num:40982
可以看到adder在使用效果上是可以保證累加的線程安全的
為了更好地對源碼進行分析,我們需要先從直覺上理解它的原理,否則直接看代碼的話會一臉懵逼
LongAdder的計數主要分為2個對象
一個long類型的字段:base
一個Cell對象數組,Cell對象中就維護了一個long類型的字段value,用來計數
/** * Table of cells. When non-null, size is a power of 2. */ transient volatile Cell[] cells; /** * Base value, used mainly when there is no contention, but also as * a fallback during table initialization races. Updated via CAS. */ transient volatile long base;
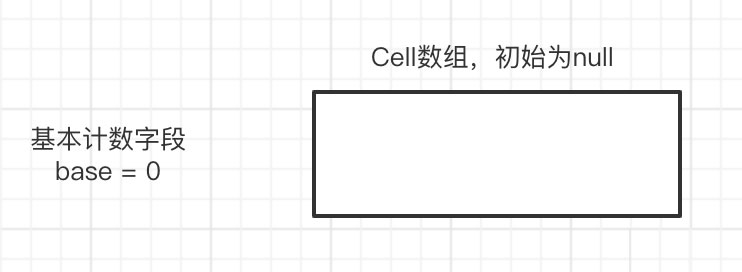
當沒有發生線程競爭的時候,累加都會發生在base字段上,這就相當于是一個單線程累加2次,只不過base的累加是一個cas操作
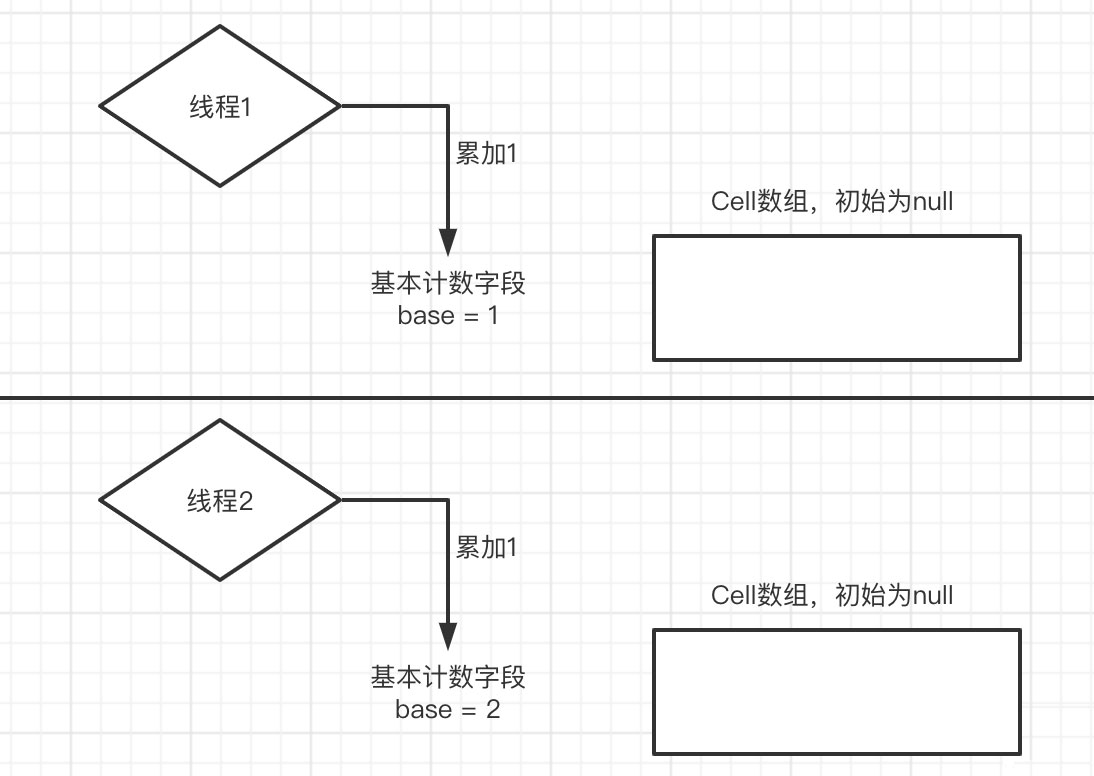
當發生線程競爭的時候,必然有一個線程對base的cas累加操作失敗,于是它先去判斷Cell是否已經被初始化了,如果沒有則初始化一個長度為2的數組,并根據線程的hash值找到對應的數組索引,并對該索引的Cell對象中的value值進行累加(這個累加也是cas的操作)
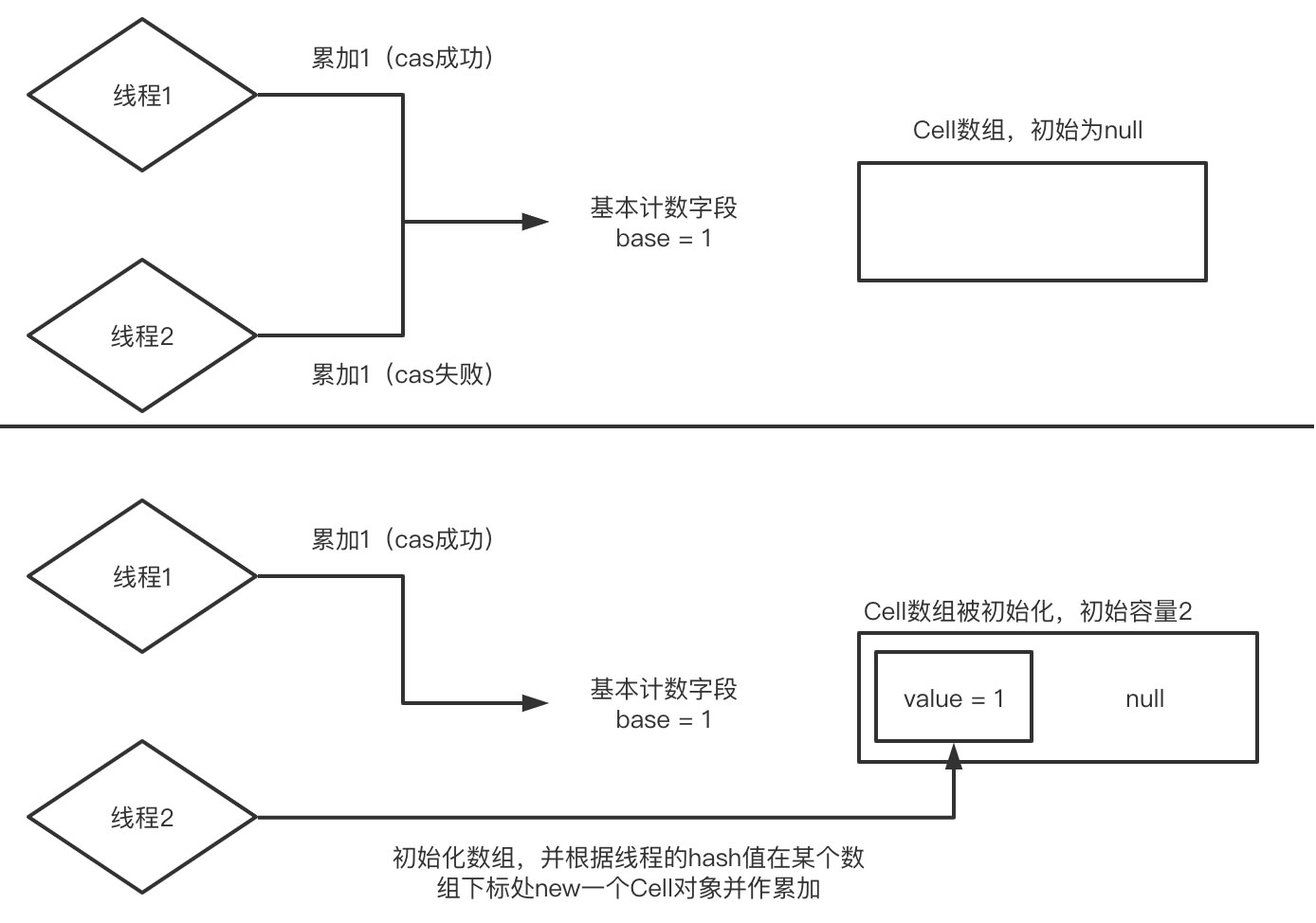
如果一共有3個線程發生了競爭,那么其中第一個線程對base的cas累加成功,剩下2個線程都需要去對Cell數組中的元素進行累加。因為對Cell中value值的累加也是一個cas操作,如果第二個線程和第三個線程的hash值對應的數組下標是同一個,那么同樣會發生競爭,如果第二個線程成功了,第三個線程就會去rehash自己的hash值,如果得到的新的hash值對應的是另一個元素為null的數組下標,那么就new一個Cell對象并對value值進行累加
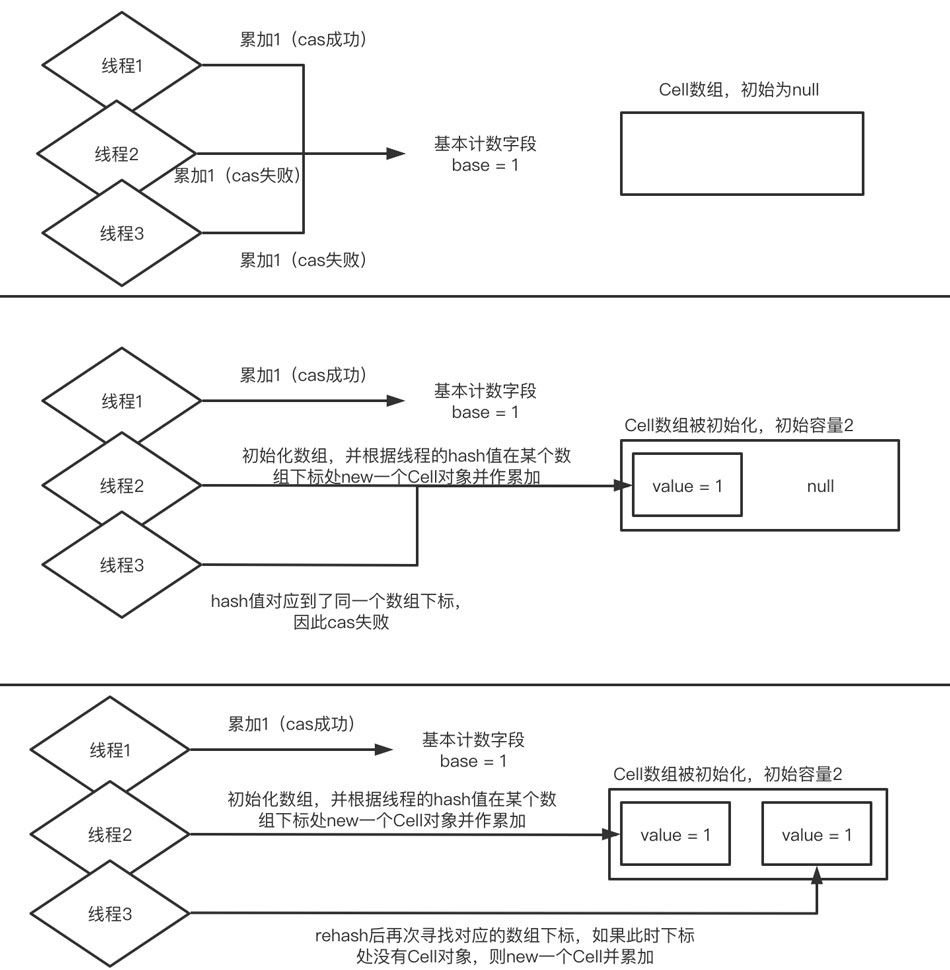
如果此時有線程4同時參與競爭,那么對于線程4來說,即使rehash后還是可能在和線程3的競爭過程中cas失敗,此時如果當前數組的容量小于系統可用的cpu的數量,那么它就會對數組進行擴容,之后再次rehash,重復嘗試對Cell數組中某個下標對象的累加
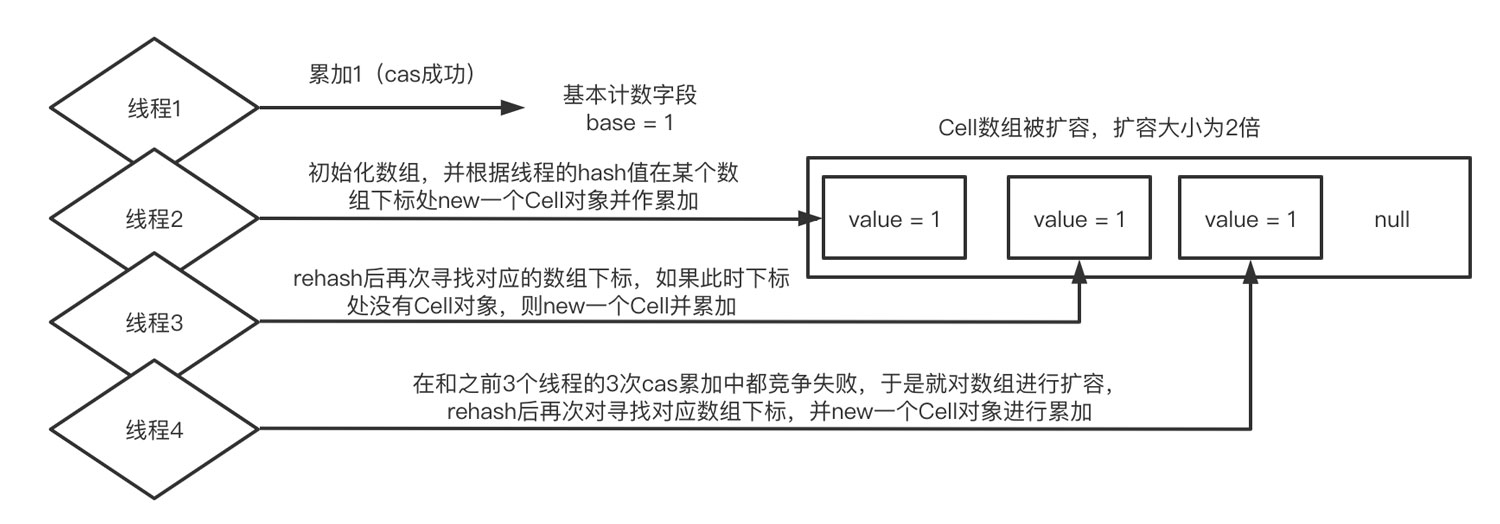
以上就是整體直覺上的理解,然而代碼中還有很多細節的設計非常值得學習,所以我們就開始進入源碼分析的環節
入口方法是add
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
/**
* 這里優先判斷了cell數組是否為空,之后才判斷base字段的cas累加
* 意味著如果線程不發生競爭,cell數組一直為空,那么所有的累加操作都會累加到base上
* 而一旦發生過一次競爭導致cell數組不為空,那么所有的累加操作都會優先作用于數組中的對象上
*/
if ((as = cells) != null || !casBase(b = base, b + x)) {
/**
* 這個字段是用來標識在對cell數組中的對象進行累加操作時是否發生了競爭
* 如果發生了競爭,那么在longAccumulate方法中會多進行一次rehash的自旋
* 這個在后面的方法中詳細說明,這里先有個印象
* true表示未發生競爭
*/
boolean uncontended = true;
/**
* 如果cell數組為空或者長度為0則直接進入主邏輯方法
*/
if (as == null || (m = as.length - 1) < 0 ||
/**
* 這里的getProbe()方法可以認為就是獲取線程的hash值
* hash值與(數組長度-1)進行位與操作后得到對應的數組下標
* 判斷該元素是否為空,如果不為空那么就會嘗試累加
* 否則進入主邏輯方法
*/
(a = as[getProbe() & m]) == null ||
/**
* 對數組下標的元素進行cas累加,如果成功了,那么就可以直接返回
* 否則進入主邏輯方法
*/
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}當不發生線程競爭的時候,那累加操作就會由第一個if中的casBase負責,對應之前圖解的情況一
當發生線程競爭之后,累加操作就會由cell數組負責,對應之前圖解的情況二(數組的初始化在longAccumulate方法中)
接著我們查看主邏輯方法,因為方法比較長,所以我會一段一段拿出來解析
longAccumulate方法
簽名中的參數
x表示需要累加的值
fn表示需要如何累加,一般傳null就行,不重要
wasUncontended表示是否在外層方法遇到了競爭失敗的情況,因為外層的判斷邏輯是多個“或”(as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null),所以如果數組為空或者相應的下標元素還未初始化,這個字段就會保持false
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
...
}首先判斷線程的hash值是否為0,如果為0則需要做一個初始化,即rehash
之后會將wasUncontended置為true,因為即使之前是沖突過的,經過rehash后就會先假設它能找到一個元素不沖突的數組下標
int h;//線程的hash值,在后面的邏輯中會用到
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}之后是一個死循環,死循環中有3個大的if分支,這3個分支的邏輯作用于數組未初始化的時候,一旦數組初始化完成,那么就都會進入主邏輯了,因此我這里把主邏輯抽取出來放到后面單獨說,也可以避免外層分支對思路的影響
/**
* 用來標記某個線程在上一次循環中找到的數組下標是否已經有Cell對象了
* 如果為true,則表示數組下標為空
* 在主邏輯的循環中會用到
*/
boolean collide = false;
/**
* 死循環,提供自旋操作
*/
for (; ; ) {
Cell[] as;
Cell a;
int n;//cell數組長度
long v;//需要被累積的值
/**
* 如果cells數組不為空,且已經被某個線程初始化成功,那么就會進入主邏輯,這個后面詳細解釋
*/
if ((as = cells) != null && (n = as.length) > 0) {
...
/**
* 如果數組為空,那么就需要初始化一個Cell數組
* cellsBusy用來標記cells數組是否能被操作,作用相當于一個鎖
* cells == as 判斷是否有其他線程在當前線程進入這個判斷之前已經初始化了一個數組
* casCellsBusy 用一個cas操作給cellsBusy字段賦值為1,如果成功可以認為拿到了操作cells數組的鎖
*/
} else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
/**
* 這里就是初始化一個數組,不解釋了
*/
boolean init = false;
try {
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
/**
* 如果當前數組是空的,又沒有競爭過其他線程
* 那么就再次嘗試去給base賦值
* 如果又沒競爭過(感覺有點可憐),那么就自旋
* 另外提一下方法簽名中的LongBinaryOperator對象就是用在這里的,不影響邏輯
*/
} else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}接著就看對cell數組元素進行累加的主邏輯
/**
* 如果cells數組不為空,且已經被某個線程初始化成功,進入主邏輯
*/
if ((as = cells) != null && (n = as.length) > 0) {
/**
* 如果當前線程的hash值對應的數組元素為空
*/
if ((a = as[(n - 1) & h]) == null) {
/**
* Cell數組并未被其他線程操作
*/
if (cellsBusy == 0) {
/**
* 這里沒有理解作者為什么會在這里初始化單個Cell
* 作者這里的注釋是Optimistically create,如果有理解的同學可以說一下
*/
Cell r = new Cell(x);
/**
* 在此判斷cell鎖的狀態,并嘗試加鎖
*/
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
/**
* 這里對數組是否為空等狀態再次進行校驗
* 如果校驗通過,那么就將之前new的Cell對象放到Cell數組的該下標處
*/
Cell[] rs;
int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
/**
* 如果創建成功,就說明累加成功,直接退出循環
*/
if (created)
break;
/**
* 走到這里說明在判空和拿到鎖之間正好有其他線程在該下標處創建了一個Cell
* 因此直接continue,不rehash,下次就不會進入到該分支了
*/
continue;
}
}
/**
* 當執行到這里的時候,因為是在 if ((a = as[(n - 1) & h]) == null) 這個判斷邏輯中
* 就說明在第一個if判斷的時候該下標處沒有元素,所以賦值為false
* collide的意義是:上一次循環中找到的數組下標是否已經有Cell對象了
* True if last slot nonempty
*/
collide = false;
/**
* 這個字段如果為false,說明之前已經和其他線程發過了競爭
* 即使此時可以直接取嘗試cas操作,但是在高并發場景下
* 這2個線程之后依然可能發生競爭,而每次競爭都需要自旋的話會很浪費cpu資源
* 因此在這里先直接增加自旋一次,在for的最后會做一次rehash
* 使得線程盡快地找到自己獨占的數組下標
*/
} else if (!wasUncontended)
wasUncontended = true;
/**
* 嘗試給hash對應的Cell累加,如果這一步成功了,那么就返回
* 如果這一步依然失敗了,說明此時整體的并發競爭非常激烈
* 那就可能需要考慮擴容數組了
* (因為數組初始化容量為2,如果此時有10個線程在并發運行,那就很難避免競爭的發生了)
*/
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
/**
* 這里判斷下cpu的核數,因為即使有100個線程
* 能同時并行運行的線程數等于cpu數
* 因此如果數組的長度已經大于cpu數目了,那就不應當再擴容了
*/
else if (n >= NCPU || cells != as)
collide = false;
/**
* 走到這里,說明當前循環中根據線程hash值找到的數組下標已經有元素了
* 如果此時collide為false,說明上一次循環中找到的下邊是沒有元素的
* 那么就自旋一次并rehash
* 如果再次運行到這里,并且collide為true,就說明明競爭非常激烈,應當擴容了
*/
else if (!collide)
collide = true;
/**
* 能運行到這里,說明需要擴容數組了
* 判斷鎖狀態并嘗試獲取鎖
*/
else if (cellsBusy == 0 && casCellsBusy()) {
/**
* 擴容數組的邏輯,這個擴容比較簡單,就不解釋了
* 擴容大小為2倍
*/
try {
if (cells == as) {
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
/**
* 這里直接continue,因為擴容過了,就先不rehash了
*/
continue;
}
/**
* 做一個rehash,使得線程在下一個循環中可能找到獨占的數組下標
*/
h = advanceProbe(h);
}到這里LongAdder的源碼其實就分析結束了,其實代碼并不多,但是他的思想非常值得我們去學習。
光分析源碼其實還差一些感覺,我們還沒有搞懂為何作者要在已經有AtomicInteger的情況下,再設計這么一個看上去非常復雜的類。
那么首先我們先分析下AtomicInteger保證線程安全的原理
查看最基本的getAndIncrement方法
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}調用了Unsafe類的getAndAddInt方法,繼續往下看
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}這里我們不再深究getIntVolatile和compareAndSwapInt方法具體實現,因為其已經是native的方法了
可以看到,AtomicInteger底層是使用了cas+自旋的方式解決原子性問題的,即如果一次賦值不成功,那么就自旋,直到賦值成功為止
那么由此可以推斷,當出現大量線程并發,競爭非常激烈的時候,AtomicInteger就有可能導致有些線程不斷地競爭失敗,不斷自旋從而影響任務的吞吐量
為了解決高并發下的自旋問題,LongAdder的作者在設計的時候就通過增加一個數組的方式,使得競爭的對象從一個值變成多個值,從而使得發生競爭的頻率降低,從而緩解了自旋的問題,當然付出的代價就是額外的存儲空間。
最后我簡單做了個測試,比較2種計數方法的耗時
通過原理可知,只有當線程競爭非常激烈的時候,LongAdder的優勢才會比較明顯,因此這里我用了100個線程,每一個線程對同一個數累加1000000次,得到結果如下,差距非常巨大,達到15倍!
LongAdder耗時:104292242nanos
AtomicInteger耗時:1583294474nanos
當然這只是一個簡單測試,包含了很多隨機性,有興趣的同學可以嘗試不同的競爭程度多次測試
最后我們需要將作者的具體代碼和實現邏輯抽象一下,理清思考的過程
1)AtomicInteger遇到的問題:單個資源的競爭導致自旋的發生
2)解決的思路:將單個對象的競爭擴展為多個對象的競爭(有那么一些分治的思想)
3)擴展的可控性:多個競爭對象需要付出額外的存儲空間,因此不能無腦地擴展(極端情況是一個線程一個計數的對象,這明顯不合理)
4)問題的分層:因為使用類的時候的場景是不可控的,因此需要根據并發的激烈程度動態地擴展額外的存儲空間(類似于synchronized的膨脹)
5)3個分層策略:當不發生競爭時,那么用一個值累加即可;當發生一定程度的競爭時,創建一個容量為2的數組,使得競爭的資源擴展為3個;當競爭更加激烈時,則繼續擴展數組(對應圖解中的1個線程到4個線程的過程)
6)策略細節:在自旋的時候增加rehash,此時雖然付出了一定的運算時間計算hash、比較數組對象等,但是這會使得并發的線程盡快地找到專屬于自己的對象,在之后就不會再發生任何競爭(磨刀不誤砍柴工,特別注意wasUncontended字段的相關注解)
“并發編程LongAdder的原理是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





