溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python中scrapy如何爬取起點中文網小說榜單,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
爬取排行榜小說的作者,書名,分類以及完結或連載
目標url:“https://www.qidian.com/rank/hotsales?style=1&page=1”
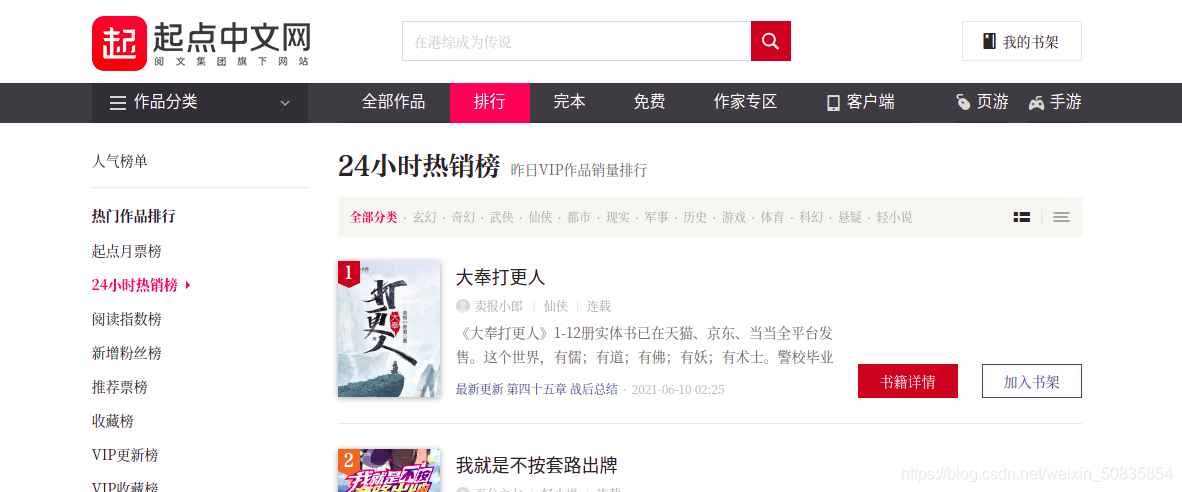
通過控制臺搜索發現相應信息均存在于html靜態網頁中,所以此次爬蟲難度較低。

通過控制臺觀察發現,需要的內容都在一個個li列表中,每一個列表代表一本書的內容。

在li中找到所需的內容

找到第兩頁的url
“https://www.qidian.com/rank/hotsales?style=1&page=1”
“https://www.qidian.com/rank/hotsales?style=1&page=2”
對比找到頁數變化
開始編寫scrapy程序。
創建項目太簡單,不說了
1.編寫item(數據存儲)
import scrapy class QidianHotItem(scrapy.Item): name = scrapy.Field() #名稱 author = scrapy.Field() #作者 type = scrapy.Field() #類型 form= scrapy.Field() #是否完載
2.編寫spider(數據抓取(核心代碼))
#coding:utf-8
from scrapy import Request
from scrapy.spiders import Spider
from ..items import QidianHotItem
#導入下需要的庫
class HotSalesSpider(Spider):#設置spider的類
name = "hot" #爬蟲的名稱
qidian_header={"user-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"} #設置header
current_page = 1 #爬蟲起始頁
def start_requests(self): #重寫第一次請求
url="https://www.qidian.com/rank/hotsales?style=1&page=1"
yield Request(url,headers=self.qidian_header,callback=self.hot_parse)
#Request發起鏈接請求
#url:目標url
#header:設置頭部(模擬瀏覽器)
#callback:設置頁面抓起方式(空默認為parse)
def hot_parse(self, response):#數據解析
#xpath定位
list_selector=response.xpath("//div[@class='book-mid-info']")
#獲取所有小說
for one_selector in list_selector:
#獲取小說信息
name=one_selector.xpath("h5/a/text()").extract()[0]
#獲取作者
author=one_selector.xpath("p[1]/a[1]/text()").extract()[0]
#獲取類型
type=one_selector.xpath("p[1]/a[2]/text()").extract()[0]
# 獲取形式
form=one_selector.xpath("p[1]/span/text()").extract()[0]
item = QidianHotItem()
#生產存儲器,進行信息存儲
item['name'] = name
item['author'] = author
item['type'] = type
item['form'] = form
yield item #送出信息
# 獲取下一頁URL,并生成一個request請求
self.current_page += 1
if self.current_page <= 10:#爬取前10頁
next_url = "https://www.qidian.com/rank/hotsales?style=1&page="+str(self.current_page)
yield Request(url=next_url,headers=self.qidian_header,callback=self.hot_parse)
def css_parse(self,response):
#css定位
list_selector = response.css("[class='book-mid-info']")
for one_selector in list_selector:
# 獲取小說信息
name = one_selector.css("h5>a::text").extract()[0]
# 獲取作者
author = one_selector.css(".author a::text").extract()[0]
# 獲取類型
type = one_selector.css(".author a::text").extract()[1]
# 獲取形式
form = one_selector.css(".author span::text").extract()[0]
# 定義字典
item=QidianHotItem()
item['name']=name
item['author'] = author
item['type'] = type
item['form'] = form
yield item3.start.py(代替命令行)
在爬蟲項目文件夾下創建start.py。
from scrapy import cmdline
#導入cmd命令窗口
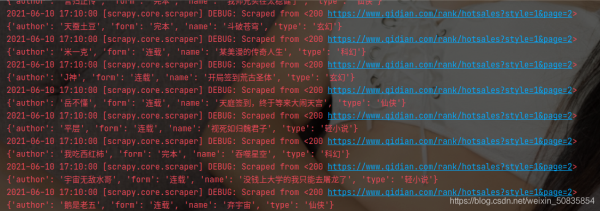
cmdline.execute("scrapy crawl hot -o hot.csv" .split())
#運行爬蟲并生產csv文件出現類似的過程代表爬取成功。
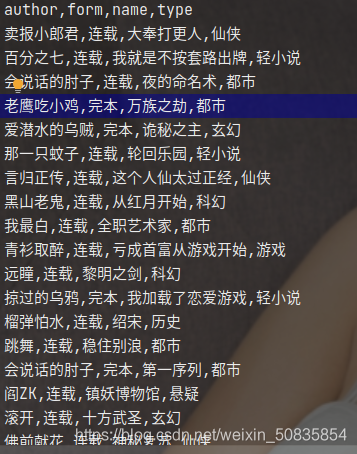
hot.csv
看完了這篇文章,相信你對“Python中scrapy如何爬取起點中文網小說榜單”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





