溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了scrapy實戰中怎樣爬取表情包,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
一、爬取表情包思路(http://www.doutula.com)
1、打開網站,點擊最新套圖
2、之后我們可以看到沒有套圖,我們需要提取每個套圖的連接
3、獲取連接之后,進入頁面提取圖片就好了
4、我們可以發現該網站還穿插有廣告,我們需要過濾點廣告
二、實戰
關于新建項目我們就不再多說了。不知道的可以看看以前文章。。。
1、首先我們提取第一頁的url
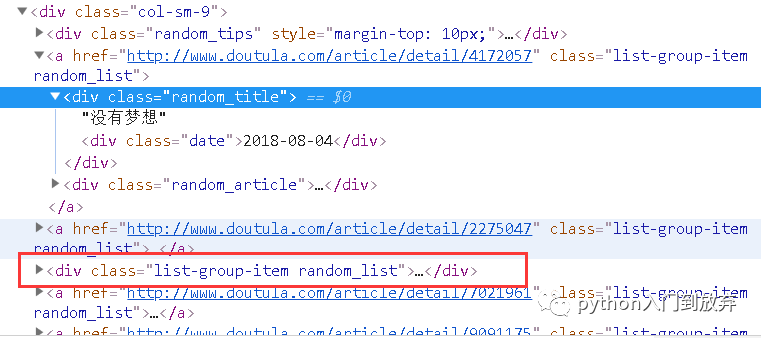
通過上圖我們可以發現我們想要的url全在class名為col-sm-9的div下,
紅色框的部分為廣告。不是a標簽,所以我們就不用過濾了。我們直接選取col-sm-9下的直接子節點即可
寫下如下代碼:
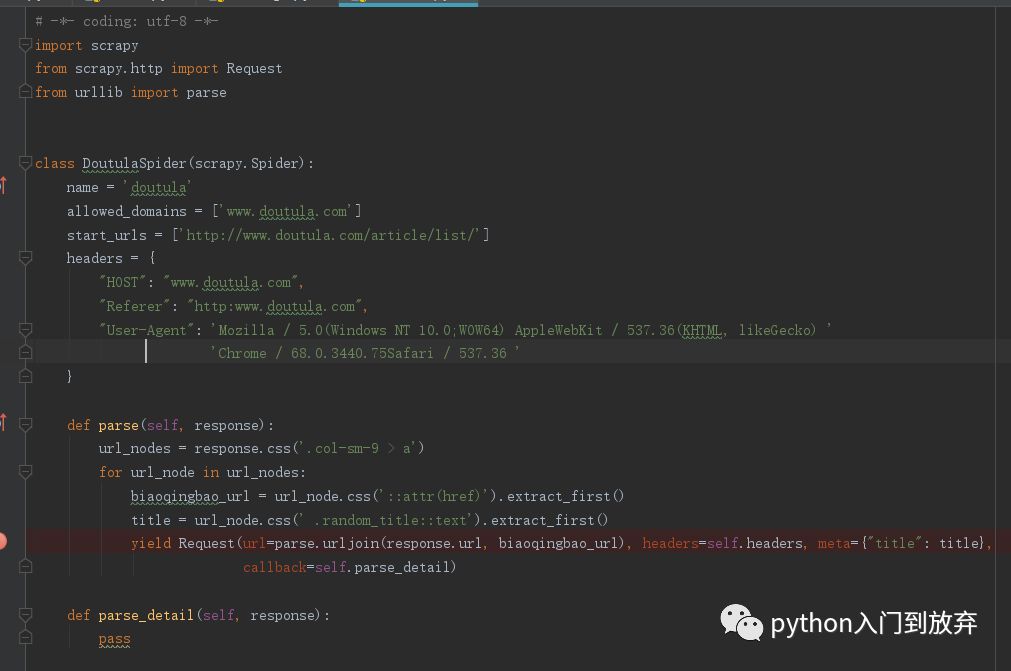
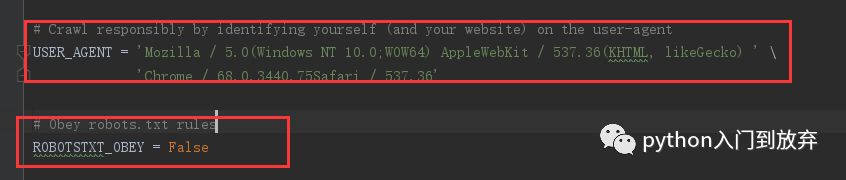
值得注意的是在settings.py中需要添加頭信息和將robots.txt協議修改為False
我們打上斷點調試一下:
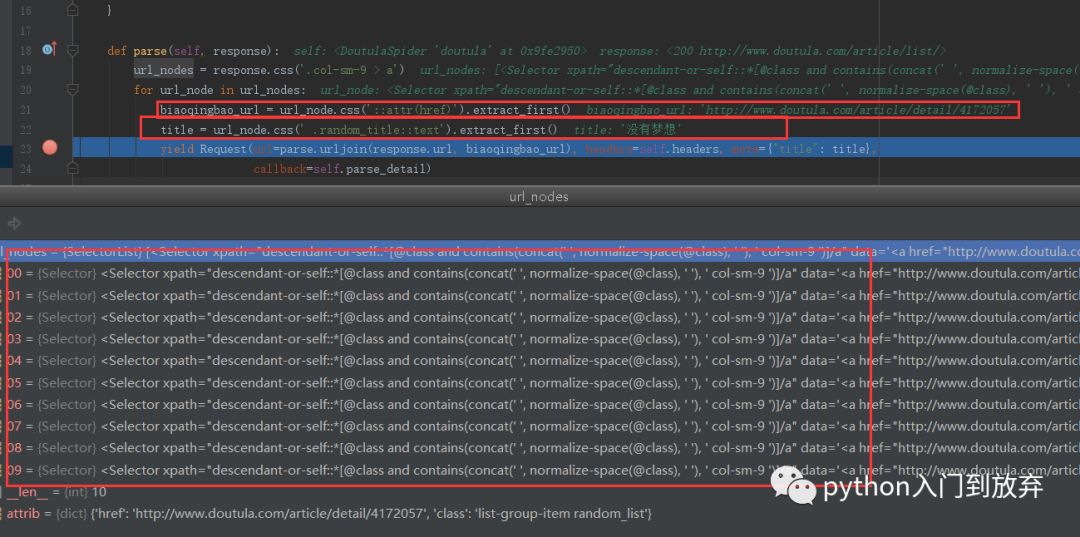
我們發現我們想要的信息已經提取出來了。
注意:在Request中的mate參數,是用來傳遞參數的,傳遞給下一個方法使用。使用方法和字典相似。
2、完善item
我們只需要三個字段,什么系列,圖片url,圖片名稱。
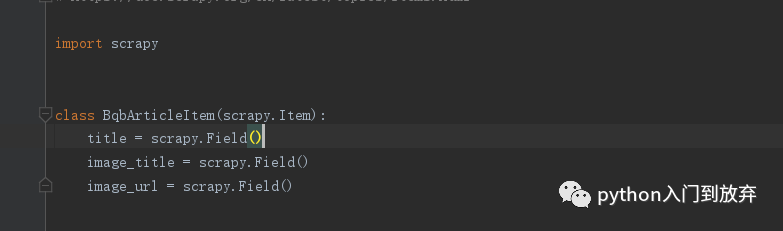
3、提取item中我們需要的字段

4、下一頁
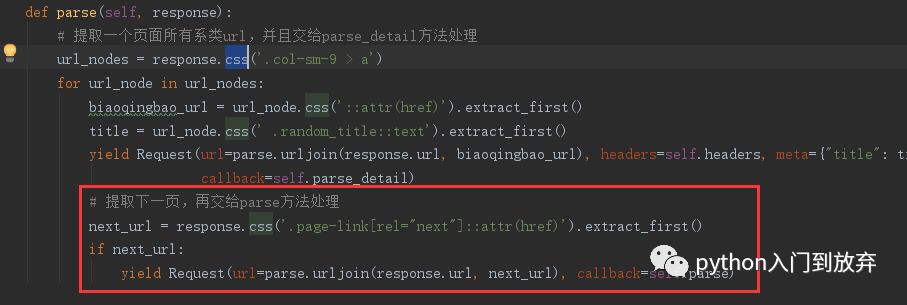
5、保存
因為對scrapy保存圖片沒有研究,所以就自己寫保存圖片的方法。
在pipelines.py種添加如下代碼:
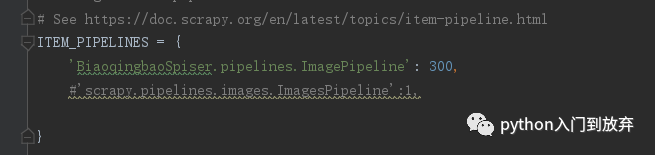
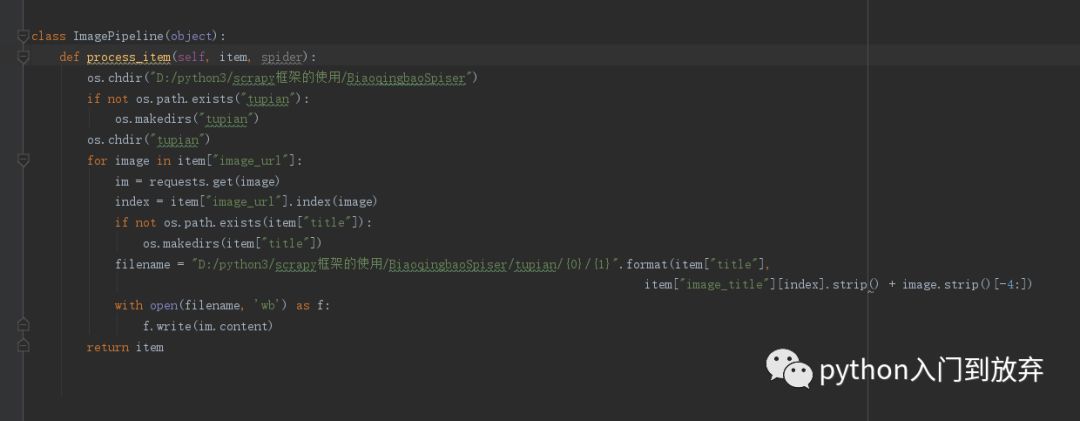 并且在settings.py中添加:
并且在settings.py中添加:
6、運行
直接報錯,因為有反扒機制,所以我們在settings.py添加頭信息
運行一段時候后又報錯了,看來需要隨機更換表頭信息。
這里我們使用第三方庫很方便,pip3 install fake_useragent
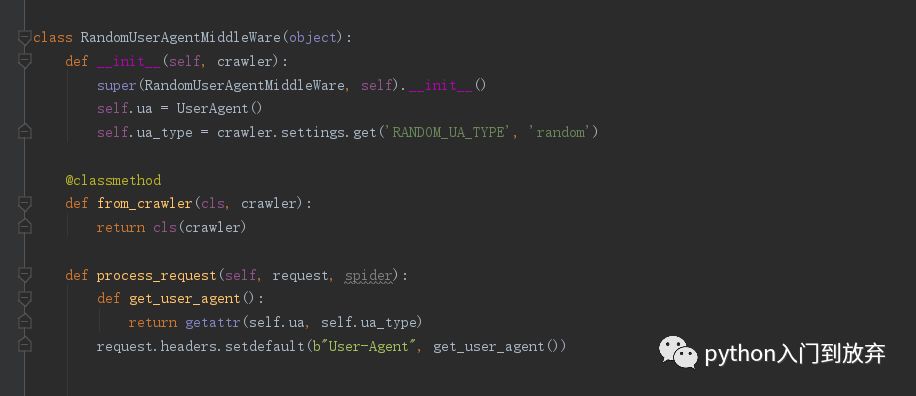
安裝成功后我們在middlewares.py中導入:from fake_useragent import UserAgent
添加如下代碼:
在settings.py文件中添加
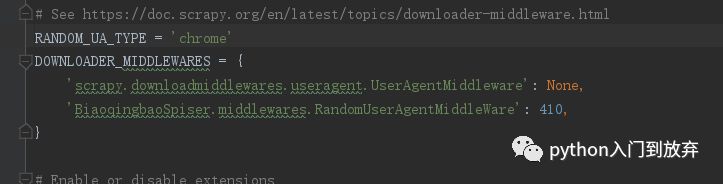
即可
運行main文件:
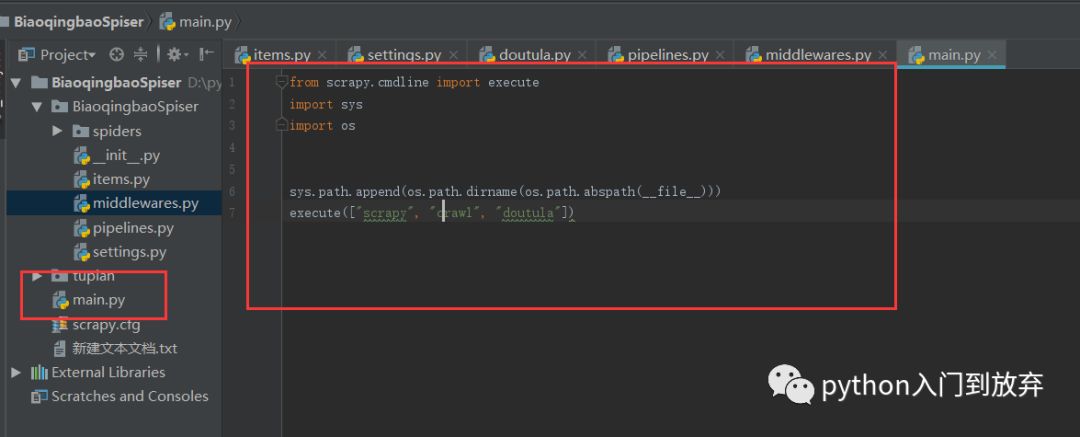
即可。
小結:
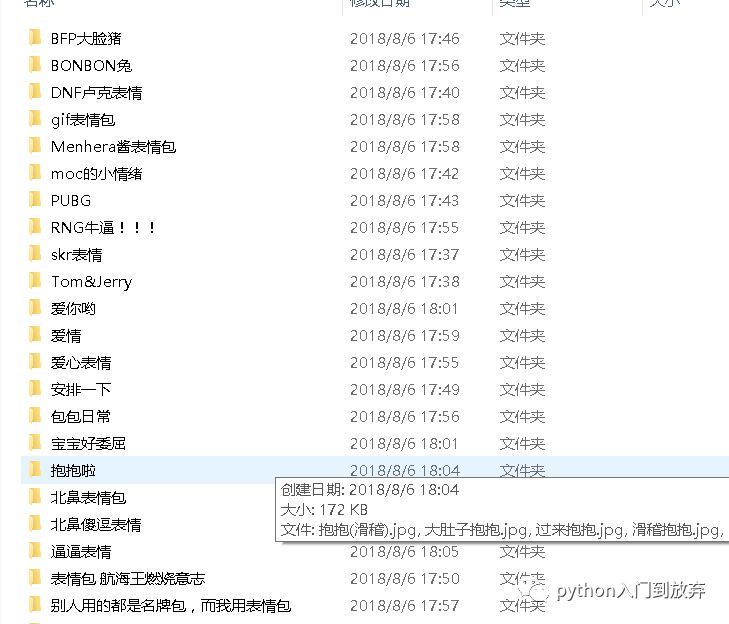
效果圖:
問題:
在運行過程中遇到了四個問題:
1、沒有獲取大到圖片連接:
可能這個網站有兩個版本獲取的css方式不一樣。
解決方法:可以使用xpath中的|(或)來解決
2、沒有獲取到圖片名稱
解決方法:同上
3、圖片名稱相同
解決方法:可以使用md5加密后添加,你也可以使用你自己的方法
4、在圖片名中含有?/\等非法字符
解決方法:可以通過正則過濾,如果md5加密,那么一下解決兩個問題。
雖然有些圖片沒有獲取到,但是還是爬取了很多。
上述內容就是scrapy實戰中怎樣爬取表情包,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





