溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關怎么在Python中實現HIVE的UDF函數,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
簡單來做個介紹
select * from(select * from table where dt='2021-03-30')a
可以寫成
with a as (select * from table where dt='2021-03-30' ) select * from a
簡單的SQL看不出這樣的優勢(甚至有點多此一舉),但是當邏輯復雜了之后我們就能看出這種語法的優勢,他能從底層抽取中間表格,讓我們只專注于當前使用的表格,進而可以將復雜的處理邏輯分解成簡單的步驟。
如下面地表格記錄了用戶適用app過程中每個行為日志地時間戳,我們想統計一下用戶今天用了幾次app,以及每次的起始時間和結束時間是什么時候,這個問題怎么解呢?

首先用with as 構建一個中間表(注意看on 和 where條件)
with t1 as (select x.uid, case when x.rank=1 then y.timestamp_ms else x.timestamp_ms end as start_time, case when x.rank=1 then x.timestamp_ms else y.timestamp_ms end as end_time from (select uid, timestamp_ms, row_number()over(partition by uid order by timestamp_ms) rank from tmp.tmpx) x left outer join (select uid, timestamp_ms, row_number()over(partition by uid order by timestamp_ms) rank from tmp.tmpx) y on x.uid=y.uid and x.rank=y.rank-1 where x.rank=1 or y.rank is null or y.timestamp_ms-x.timestamp_ms>=300)
首先我們用開窗函數錯位相減,用where條件篩選出我們需要的列,其中
x.rank=1 抽取出第一行
y.rank is null 抽取最后一樣
y.timestamp_ms-x.timestamp_ms>=300抽取滿足條件的行,如下:

當然這個結果并不是我們要的結果,需要將上述表格中某一行數據的end-time和下一條數據的start-time結合起來起來,構造出時間段
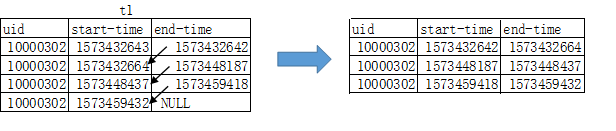
好的,按照上面我們所說的那么下面我們不用關心底層的邏輯,將注意力專注于這張中間表t1
select a.uid,end_time as start_time,start_time as end_time from (select uid,start_time,row_number()over(partition by uid order by start_time) as rank from t1) a join (select uid,end_time,row_number()over(partition by uid order by end_time) as rank from t1)b on a.uid=b.uid and a.rank=b.rank+1
同樣,排序后錯位相減,然后就可以打完收工了~
首先我們假設上述數據存儲在csv中,
用python 處理本地文件data.csv,按照python的處理方式寫代碼(這里就不一句句解釋了,會python的同學可以跳過,不會的同學不妨自己動手寫一下)
def life_cut(files): f=open(files) act_list=[] act_dict={} for line in f: line_list=line.strip().split() key=tuple(line_list[0:1]) if key not in act_dict: act_dict.setdefault(key,[]) act_dict[key].append(line_list[1]) else: act_dict[key].append(line_list[1]) for k,v in act_dict.items(): k_str=k[0]+"\t" start_time = v[0] last_time=v[0] i=1 while i<len(v)-1: if int(v[i])-int(last_time)>=300: print(k_str+"\t"+start_time+"\t"+v[i-1]) start_time=v[i] last_time = v[i] i=i+1 else: last_time = v[i] i=i+1 print(k_str+"\t"+start_time+"\t"+v[len(v)-1]) # print(k_str + "\t" + start_time + "\t" + v[i]) if __name__=="__main__": life_cut("data.csv")得到結果如下:

那么下面我們將上述函數寫成udf的形式:
#!/usr/bin/env python # -*- encoding:utf-8 -*- import sys act_list=[] act_dict={} for line in sys.stdin: line_list=line.strip().split("\t") key=tuple(line_list[0:1]) if key not in act_dict: act_dict.setdefault(key,[]) act_dict[key].append(line_list[1]) else: act_dict[key].append(line_list[1]) for k,v in act_dict.items(): k_str=k[0]+"\t" start_time = v[0] last_time=v[0] i=1 while i<len(v)-1: if int(v[i])-int(last_time)>=300: print(k_str+"\t"+start_time+"\t"+v[i-1]) start_time=v[i] last_time = v[i] i=i+1 else: last_time = v[i] i=i+1 print(k_str+"\t"+start_time+"\t"+v[len(v)-1])這個變化過程的關鍵點是將 for line in f 替換成 for line in sys.stdin,其他基本上沒什么變化
然后我們再來引用這個函數
先add這個函數的路徑add file /xxx/life_cut.py 加載udf路徑,然后再使用
select TRANSFORM (uid,timestamp_ms) USING "python life_cut.py" as (uid,start_time,end_time) from tmp.tmpx
以上就是怎么在Python中實現HIVE的UDF函數,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





