溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關這么在Spring Cloud中使用Sleuth,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
前段時間在一個交流群吹水,一個大佬說他們公司總共有上百個微服務。假如這句話真實,那么他們公司微服務調用可能會如下圖所示:

來自網絡的這張圖很好的說明了微服務調用之間的復雜性。每一次前端請求往往需要涉及到多個服務。這些服務有可能是由不同的團隊開發、可能使用不同的編程語言來實現、有可能布在了幾千臺服務器,橫跨多個不同的數據中心。因此,就需要一些可以幫助理解系統行為、用于分析性能問題的工具,以便發生故障的時候,能夠快速定位和解決問題。所以,鏈路追蹤這個思想就被人提了出來,而我們今天要討論的Sleuth就是借鑒該思想演變來的分布式追蹤解決方案。
微服務跟蹤(sleuth)其實是一個工具,它在整個分布式系統中能跟蹤一個用戶請求的過程(包括數據采集,數據傳輸,數據存儲,數據分析,數據可視化),捕獲這些跟蹤數據,就能構建微服務的整個調用鏈的視圖,這是調試和監控微服務的關鍵工具。SpringCloudSleuth有4個特點

Spring Cloud Sleuth采用的是Google的開源項目Dapper的專業術語。
鴻蒙官方戰略合作共建——HarmonyOS技術社區
Span:基本工作單元,發送一個遠程調度任務 就會產生一個Span,Span是一個64位ID唯一標識的,Trace是用另一個64位ID唯一標識的,Span還有其他數據信息,比如摘要、時間戳事件、Span的ID、以及進度ID。
Trace:一系列Span組成的一個樹狀結構。請求一個微服務系統的API接口,這個API接口,需要調用多個微服務,調用每個微服務都會產生一個新的Span,所有由這個請求產生的Span組成了這個Trace。
Annotation:用來及時記錄一個事件的,一些核心注解用來定義一個請求的開始和結束 。這些注解包括以下:
cs - Client Sent -客戶端發送一個請求,這個注解描述了這個Span的開始
sr - Server Received -服務端獲得請求并準備開始處理它,如果將其sr減去cs時間戳便可得到網絡傳輸的時間。
ss - Server Sent (服務端發送響應)–該注解表明請求處理的完成(當請求返回客戶端),如果ss的時間戳減去sr時間戳,就可以得到服務器請求的時間。
cr - Client Received (客戶端接收響應)-此時Span的結束,如果cr的時間戳減去cs時間戳便可以得到整個請求所消耗的時間。
首先我們搞一個項目,大概如下面樣子

我們引入下面的依賴
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--關鍵依賴--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency>
我們創建一個測試類:
package com.milo.sleuth.controller; import lombok.extern.slf4j.Slf4j; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @Slf4j public class Example { @RequestMapping("/") String home() { log.info("Hello world!"); return "Hello World!"; } }啟動項目以后,我們訪問一下:

這時候,我們來看看日志情況:

我們來看看它們分別代表什么意思
第一個就是我們服務名稱,對應我們配置文件中的spring.application.name
第二個就是traceId
第三個就是spanId
雖然我們現在通過日志文件也可以識別調用路徑,貌似并不是很方便,很直觀,接下里我們來了解一下Zipkin
Zipkin是一個分布式跟蹤系統。它有助于收集解決服務體系結構中的延遲問題所需的時序數據。功能包括該數據的收集和查找。
如果您在日志文件中有跟蹤ID,則可以直接跳至該跟蹤ID。否則,您可以基于諸如服務,操作名稱,標簽和持續時間之類的屬性進行查詢。將為您匯總一些有趣的數據,例如服務中花費的時間百分比以及操作是否失敗。

Zipkin UI還提供了一個依賴關系圖,該關系圖顯示了每個應用程序中跟蹤了多少個請求。這對于識別包括錯誤路徑或對不贊成使用的服務的調用在內的匯總行為可能會有所幫助。

需要對應用程序進行“儀表化”以將跟蹤數據報告給Zipkin。這通常意味著配置跟蹤器或儀器庫。向Zipkin報告數據的最流行方法是通過HTTP或Kafka,盡管存在許多其他選項,例如Apache ActiveMQ,gRPC和RabbitMQ。提供給UI的數據存儲在內存中,或持久存儲在受支持的后端(例如Apache Cassandra或Elasticsearch)中。
Zipkin 分為兩端,一個是 Zipkin 服務端,一個是 Zipkin 客戶端,客戶端也就是微服務的應用,客戶端會配置服務端的 URL 地址,一旦發生服務間的調用的時候,會被配置在微服務里面的 Sleuth 的監聽器監聽,并生成相應的 Trace 和 Span 信息發送給服務端。發送的方式有兩種,一種是消息總線的方式如 RabbitMQ 發送,還有一種是 HTTP 報文的方式發送。
首先,在剛剛的依賴文件中,我們加一個新成員
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
接著修改配置文件
# 應用名稱 spring: application: name: springcloud-sleuth # 應用服務 WEB 訪問端口 server: port: 9876 zipkin: base-url: http://localhost:9411/ # 服務端地址 sender: type: web # 數據傳輸方式,web 表示以 HTTP 報文的形式向服務端發送數據 sleuth: sampler: probability: 1.0 # 收集數據百分比,默認 0.1(10%)
Zipkin的服務端是一個可執行的jar文件,我們需要去下載
“下載地址:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
上面地址默認下載最新版本,大家也可以去下面的網址下載指定版本


現在我們啟動jar包
“java -jar zipkin-server-2.23.2-exec.jar

接下來我們訪問一下http://localhost:9411/zipkin/,結果如下:

環境搭架好了,現在我們測試一把,看看接入Zipkin之后,我們會看到什么效果?
我們訪問http://localhost:9876/之后,點擊Zipkin控制臺的Run Query查詢一下,看到如下效果:
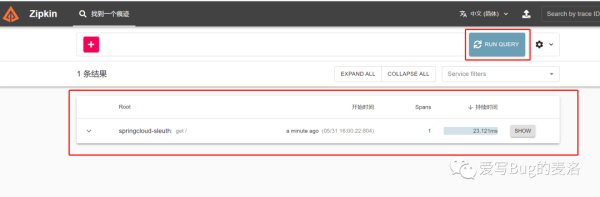
繼續點擊show,我們去看看詳情

果然很強大,執行時間,什么請求方式,請求路徑,那個類,那個方法一目了然
鑒于我們剛剛新建的只是一次很簡單的調用,不足以模擬微服務場景,接下來我們來看一個復雜一點的場景;
這里為了偷懶,我們就不去創建自己的微服務,使用官方給我們提供的測試案例brave-example,如下所示

我們把代碼搞下來,這個項目好像整合了好多技術的測試案例,看不懂,我就研究了下面的這個跑起來測試一下

我們用idea把這個項目導入進來,大概長這個鬼樣子

Backend代表后端服務
Frontend代表前端服務
現在,我們首先保證我們Zipkin的服務端是ok的,這時候你首先啟動后端服務,然后啟動前端服務,其實就是執行以下main方法,接下來我們訪問一下http://127.0.0.1:8081/,如下圖所示

現在我們去zipkin查詢一下,發現了一個新大陸,開心

就行show一下,看看里面啥情況

上述就是小編為大家分享的這么在Spring Cloud中使用Sleuth了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





