溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Spark Streaming的案例分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Spark Streaming的案例分析”吧!
為什么從SparkStreaming入手?
因為SparkStreaming 是Spark Core上的一個子框架,如果我們能夠完全精通了一個子框架,我們就能夠更好的駕馭Spark。SparkStreaming和Spark SQL是目前最流行的框架,從研究角度而言,Spark SQL有太多涉及到SQL優化的問題,不太適應用來深入研究。而SparkStreaming和其他的框架不同,它更像是SparkCore的一個應用程序。如果我們能深入的了解SparkStreaming,那我們就可以寫出非常復雜的應用程序。
SparkStreaming的優勢是可以結合SparkSQL、圖計算、機器學習,功能更加強大。這個時代,單純的流計算已經無法滿足客戶的需求啦。在Spark中SparkStreaming也是最容易出現問題的,因為它是不斷的運行,內部比較復雜。
本課內容:
1,SparkStreaming另類在線實驗
這個另類在線實驗體現在batchInterval設置的很大,5分鐘甚至更大,為了更清晰的看清楚Streaming運行的各個環境。
實驗內容是使用SparkStreaming在線統計單詞個數,SparkStreaming連接一個端口中接收發送過來的單詞數據,將統計信息輸出到控制臺中,其中使用netcat創建一個簡單的server,來開啟并監聽一個端口,接收用戶鍵盤輸入的單詞數據。
2,瞬間理解SparkStreaming的本質
結合這個實驗并通過觀察Web UI上的Job,Stage,Task等信息,再結合SparkStreaming的源碼,對SparkStreaming進行分析。
實驗環境說明:
實驗由3臺Ubuntu14.04虛擬機上運行,其中一臺作為Spark的Master,另外兩臺作為Spark的Worker。使用的Spark版本為目前最先版1.6.1,Spark checkpoint的存儲在HDFS上(hadoop的版本為2.6.0)。為了記錄SparkStreaming運行的過程信息,需要啟動Spark的HistoryServer,以下是啟廳Spark,HDFS,HistoryServer服務的腳本。
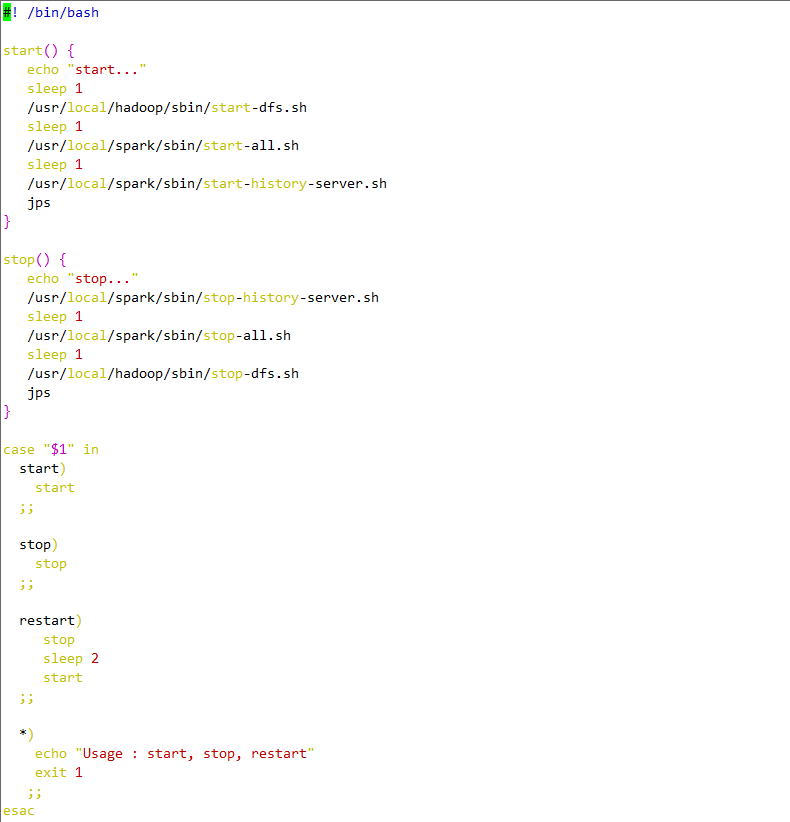
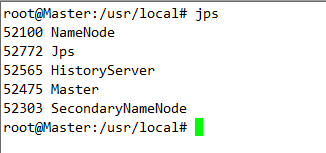
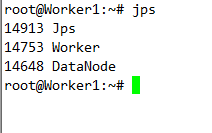
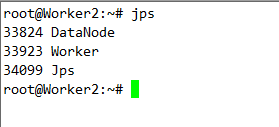
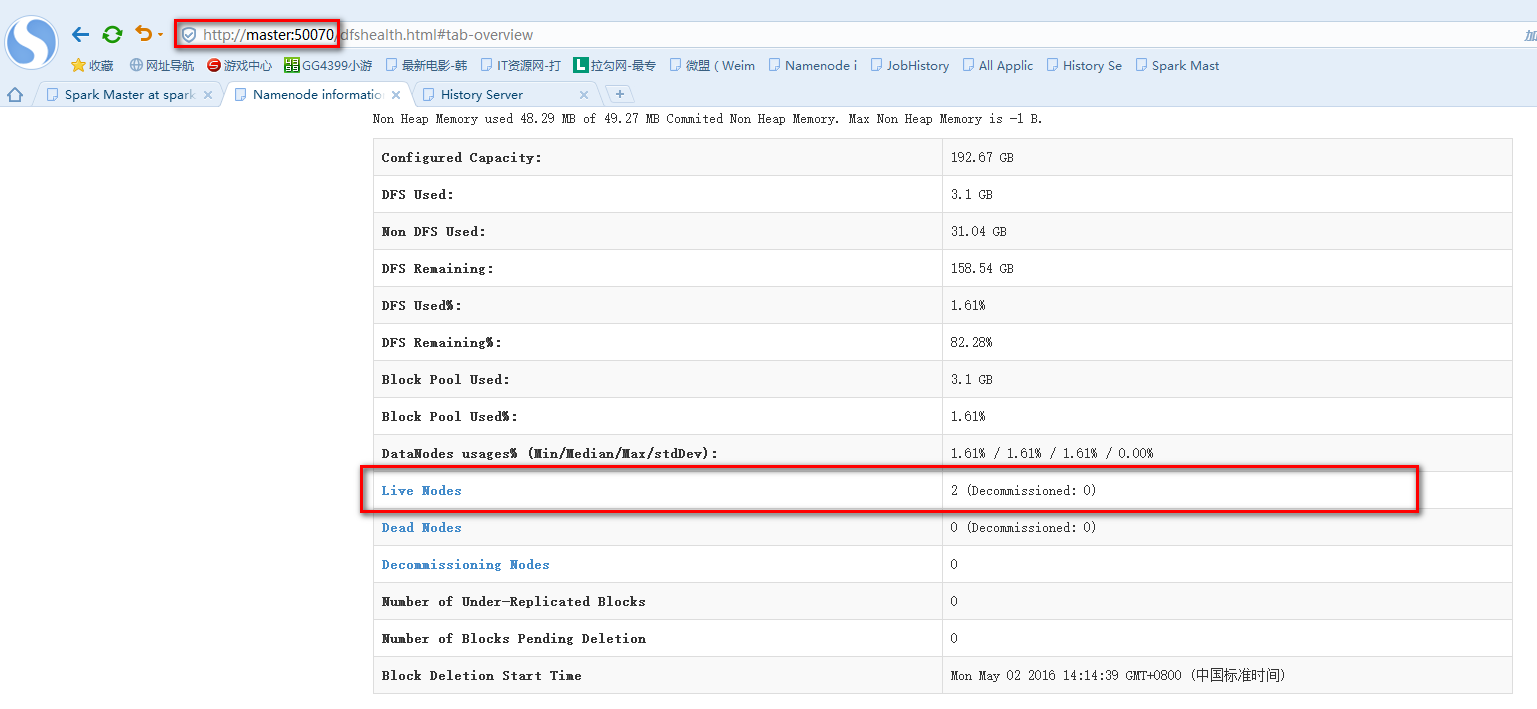
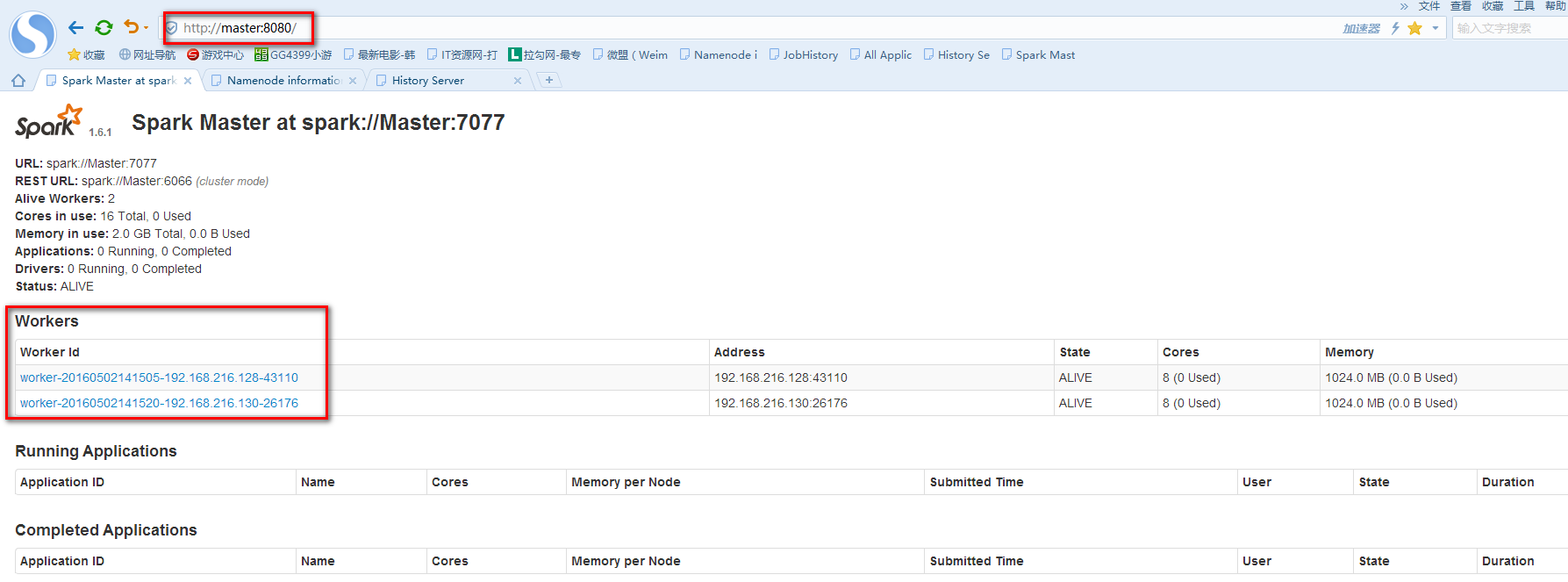
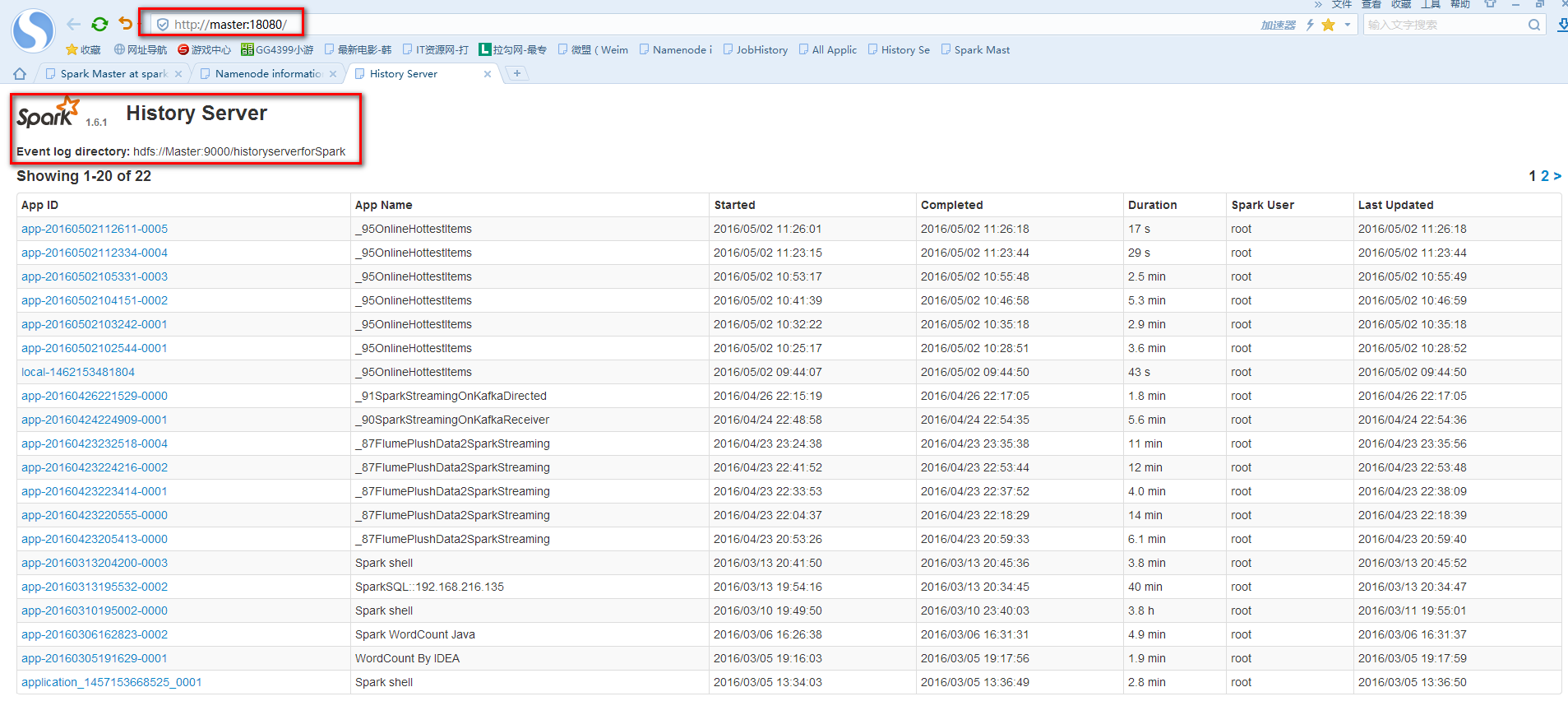
實驗代碼如下
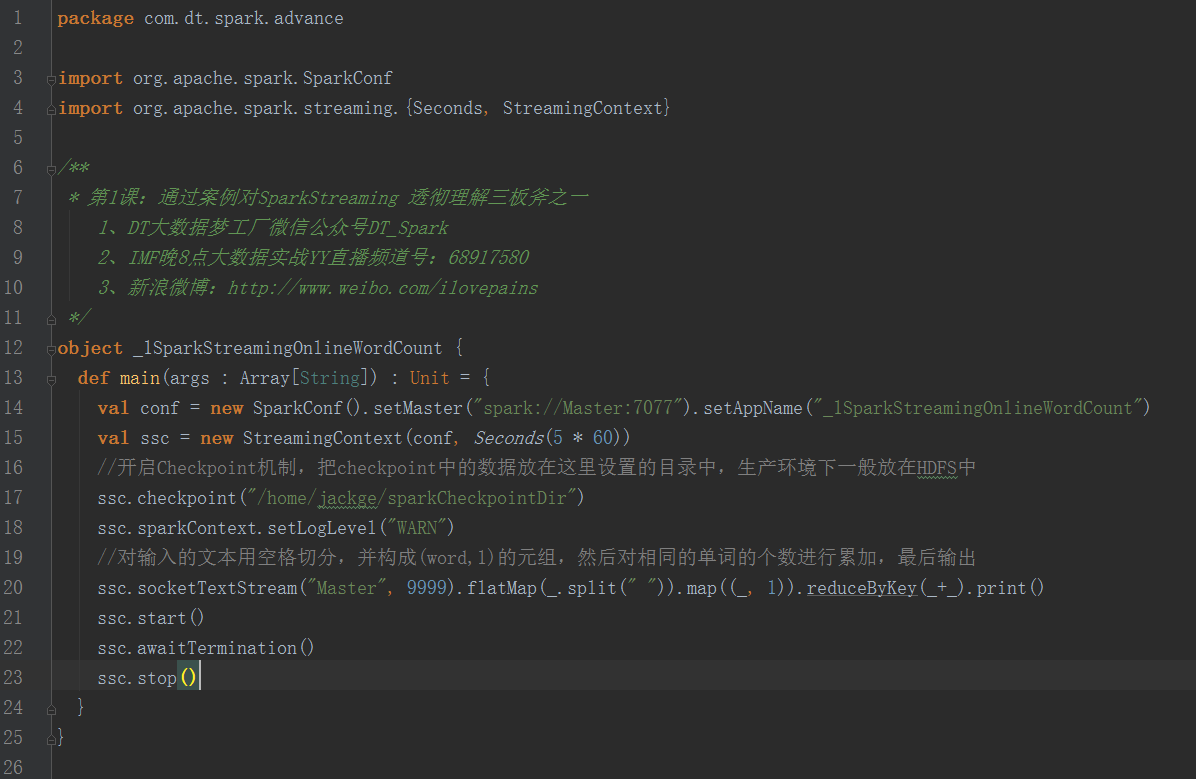
提交到Spark集群的腳本如下

首先在Master節點使用nc -lk 9999,創建一個簡單的Server,然后在運行腳本提交Spark Application。
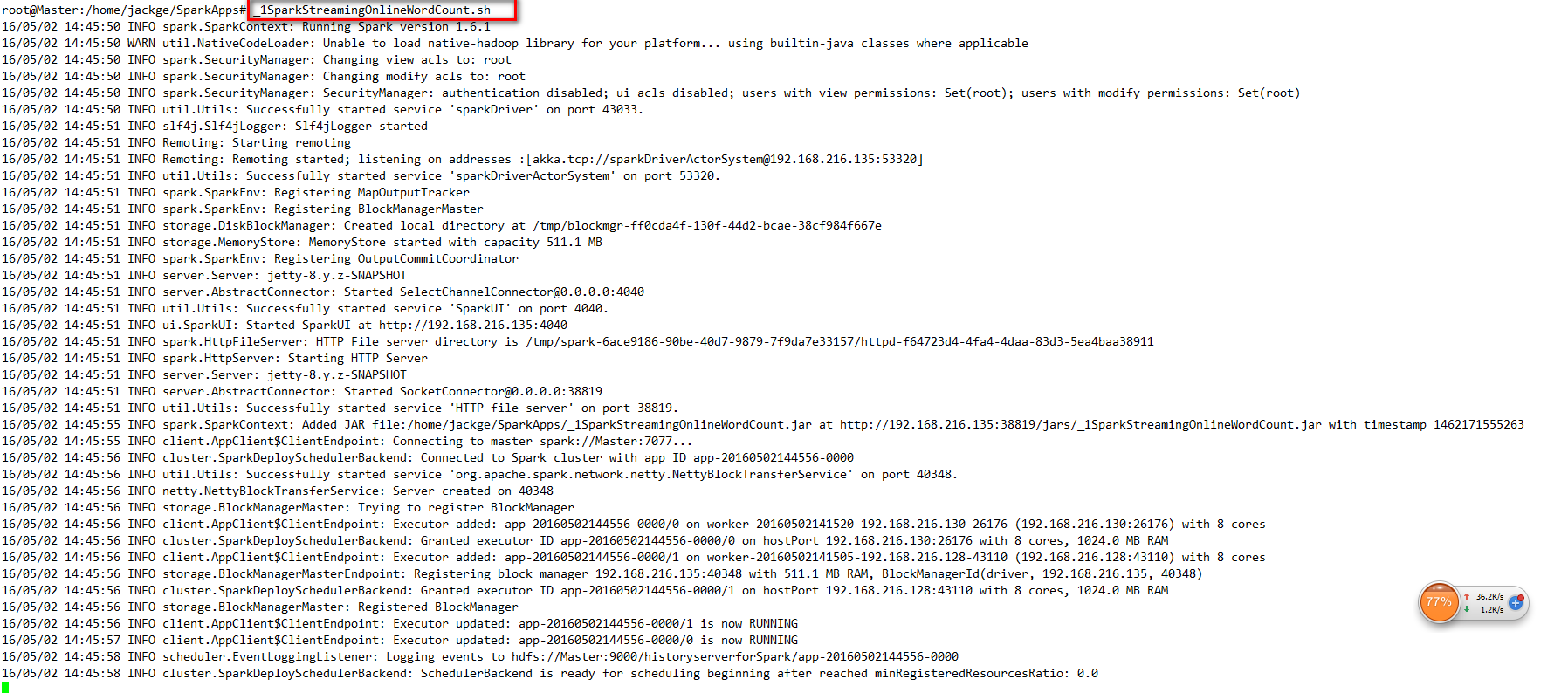
從網上找來一篇英文文章,如下

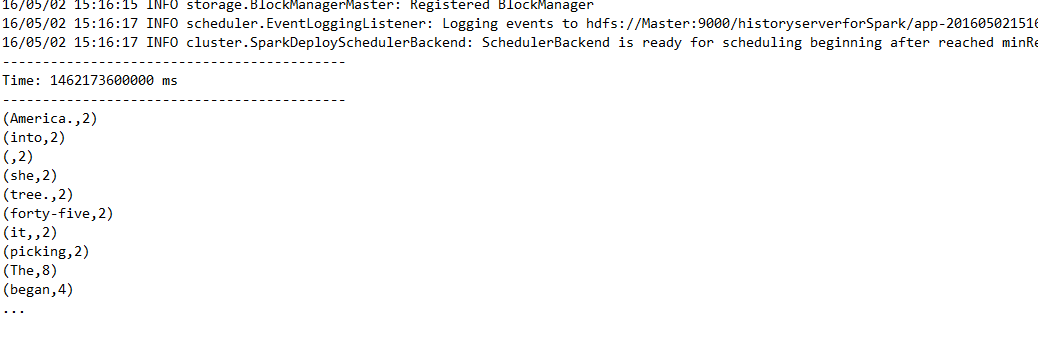
單詞統計結果如下
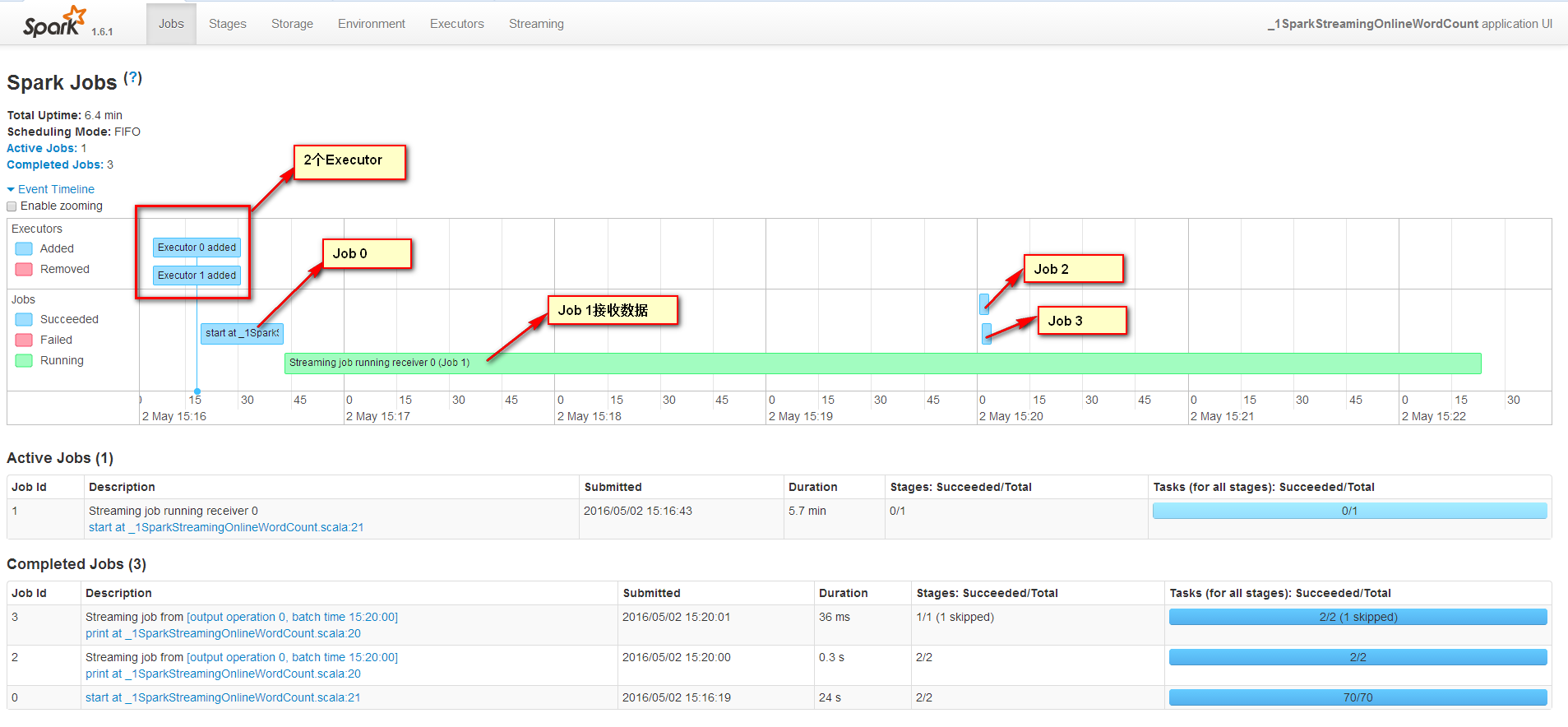
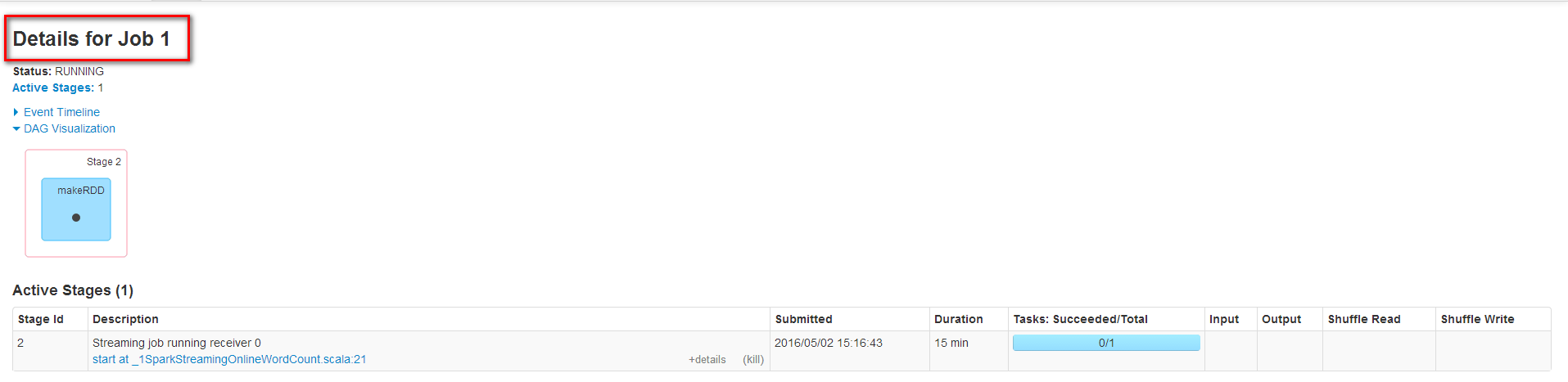
在Spark UI上觀察發現有4個Job
首先查看Job 0發現SparkStreaming在剛啟動時會提交一個Job
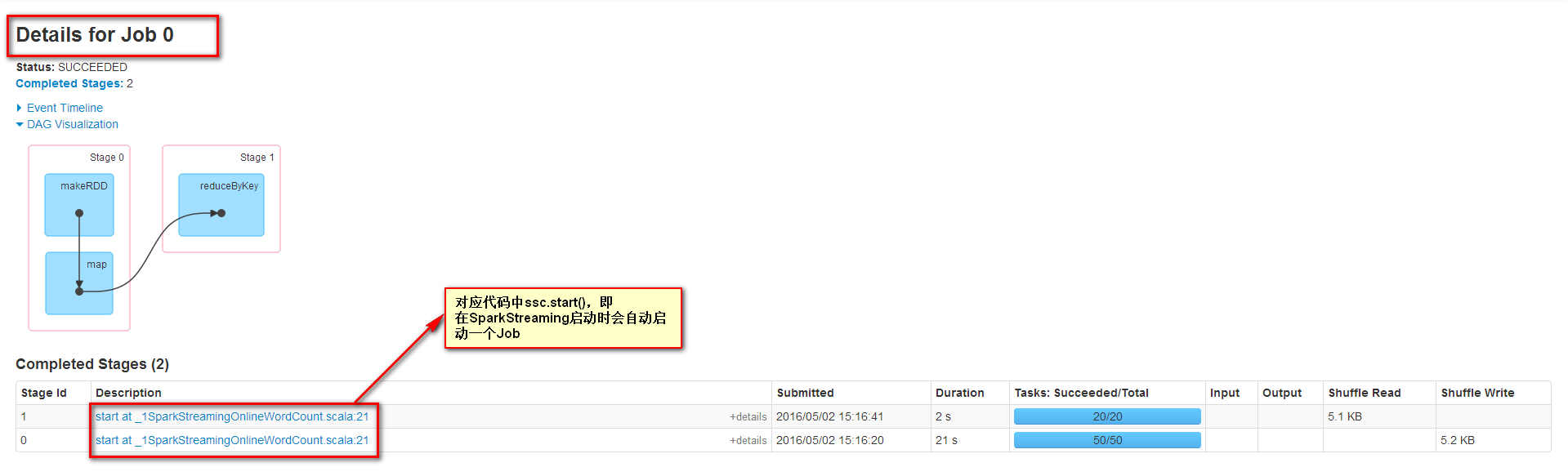
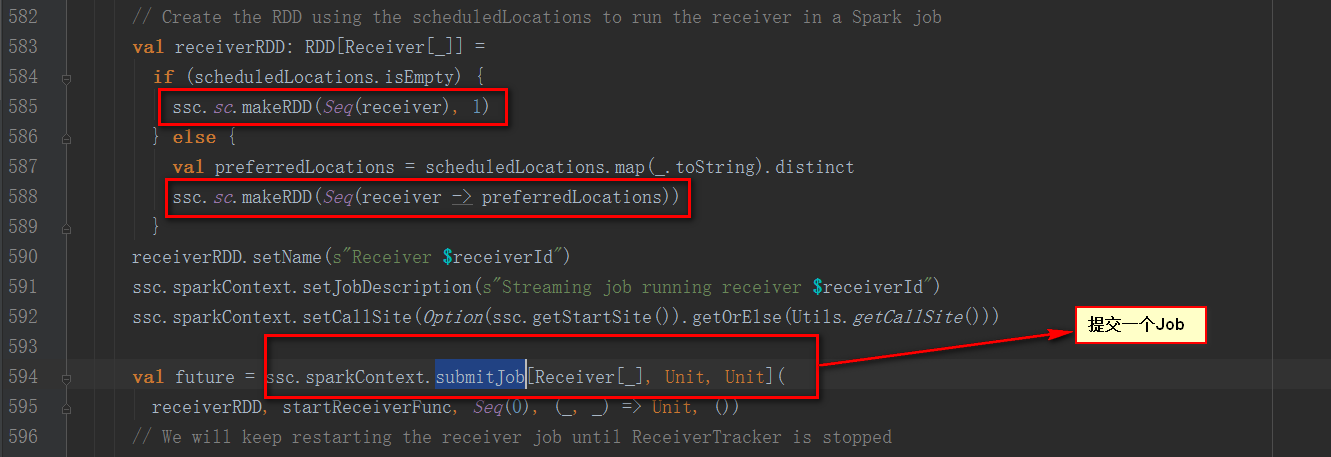
StreamingContext的start方法中調用了JobScheduler的start方法
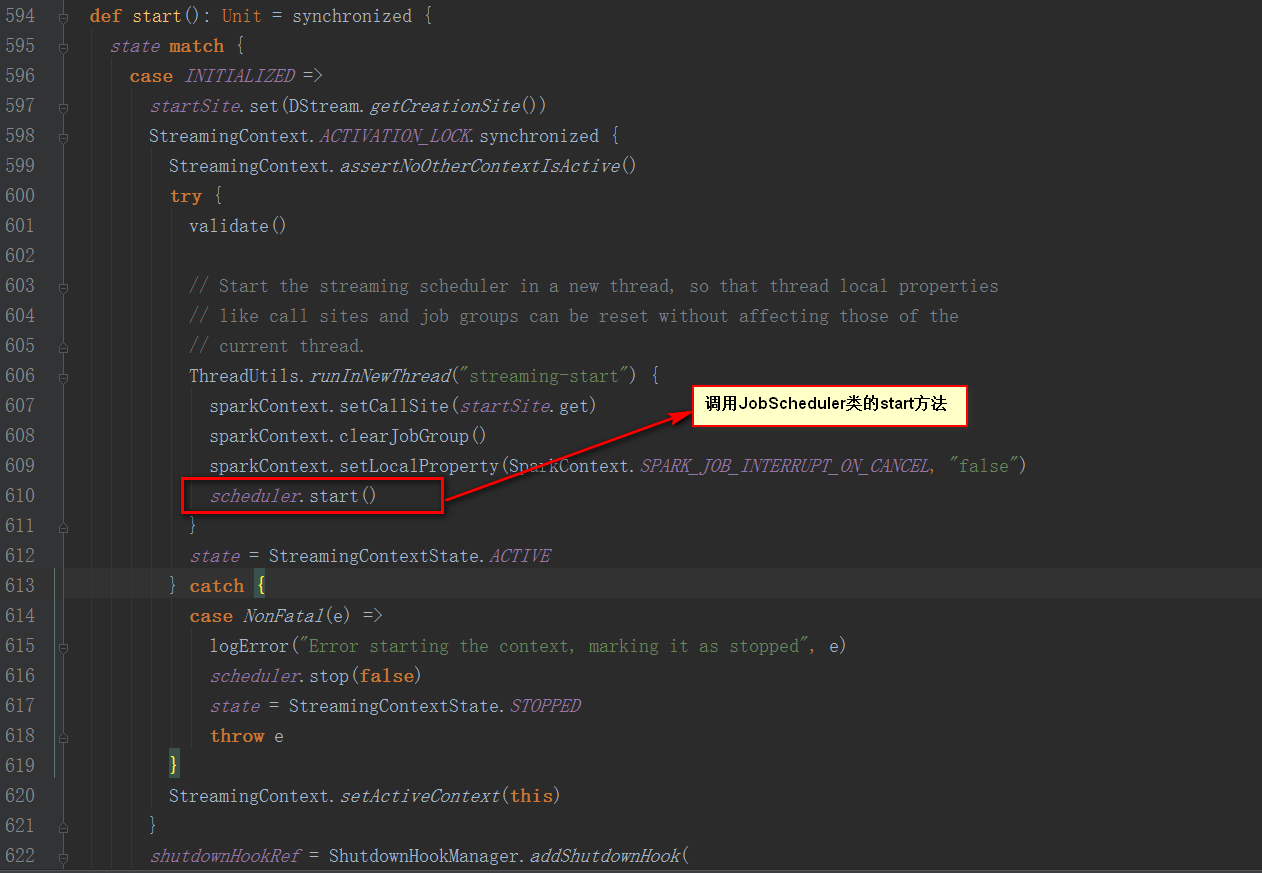
繼續看JobScheduler類的start方法
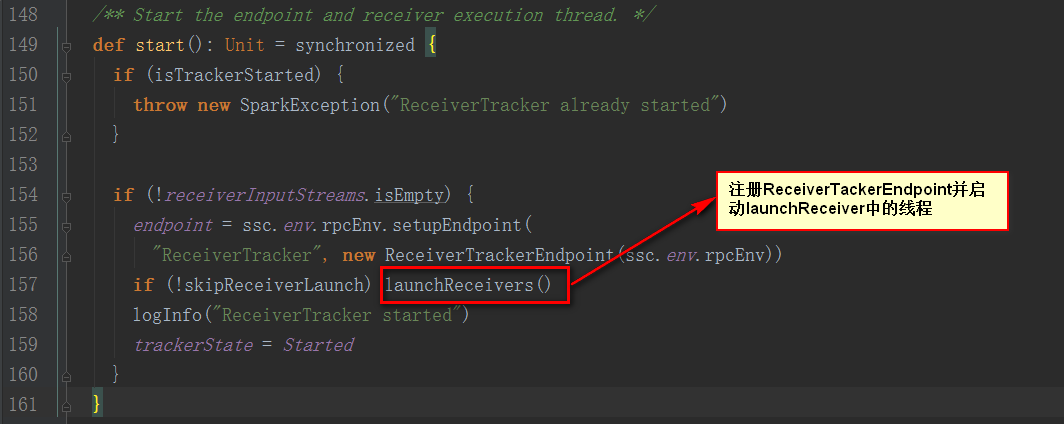
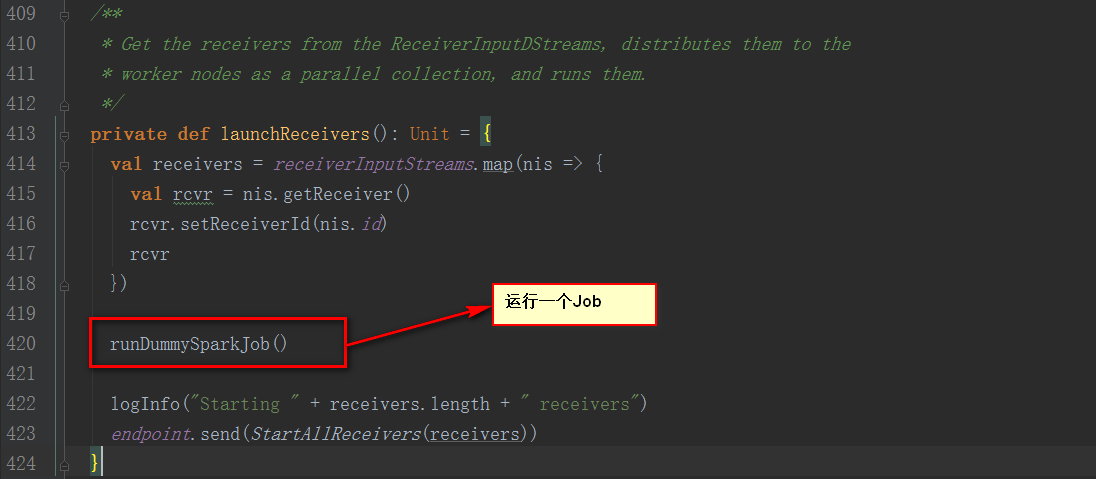
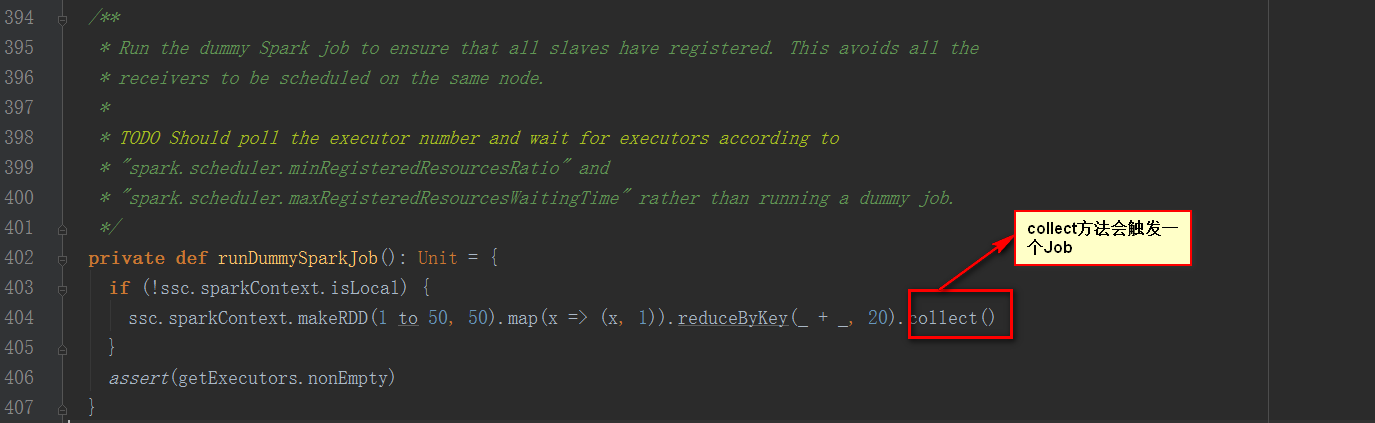
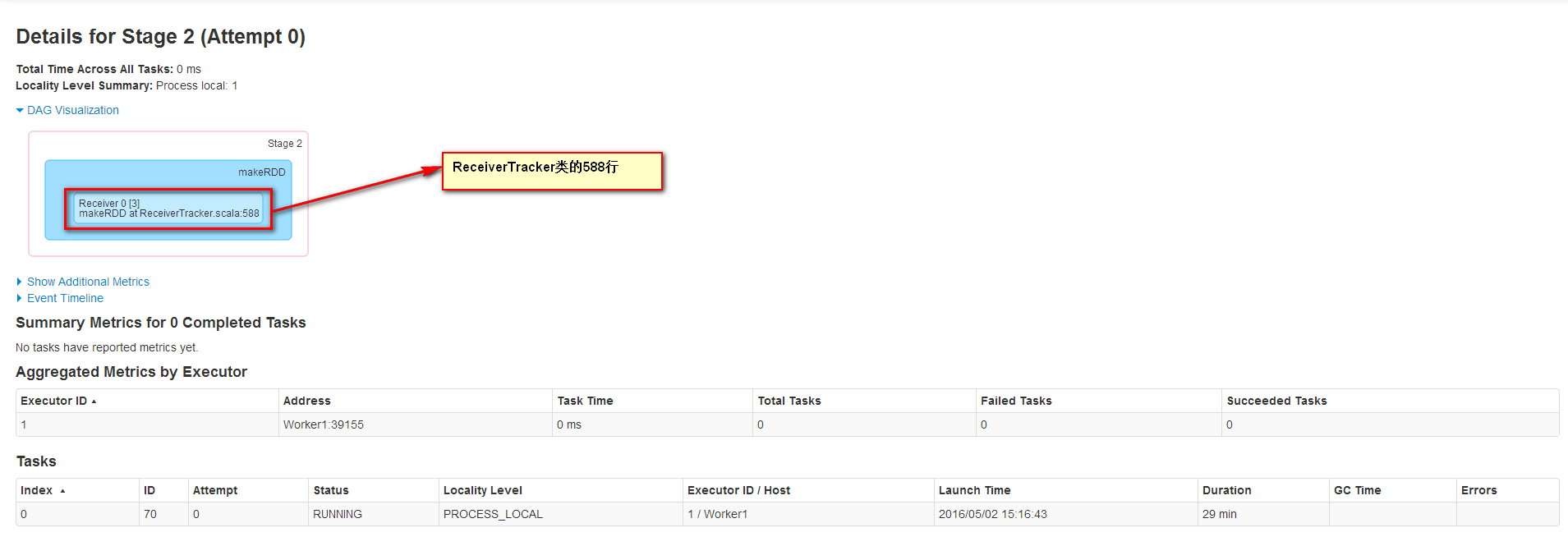
從注釋中說明該方法是為了確保每個Slave都注冊上,避免所有的Receiver在同一個節點,為了后面計算負載均衡。
Job1一直在運行是因為它不斷接收數據流中的數據,運行在Worker1上并且運行1個Task來接收數據,數據本地性為PROCESS_LOCAL,receiver接收到數據會保存到內存中。
Job2的信息如下
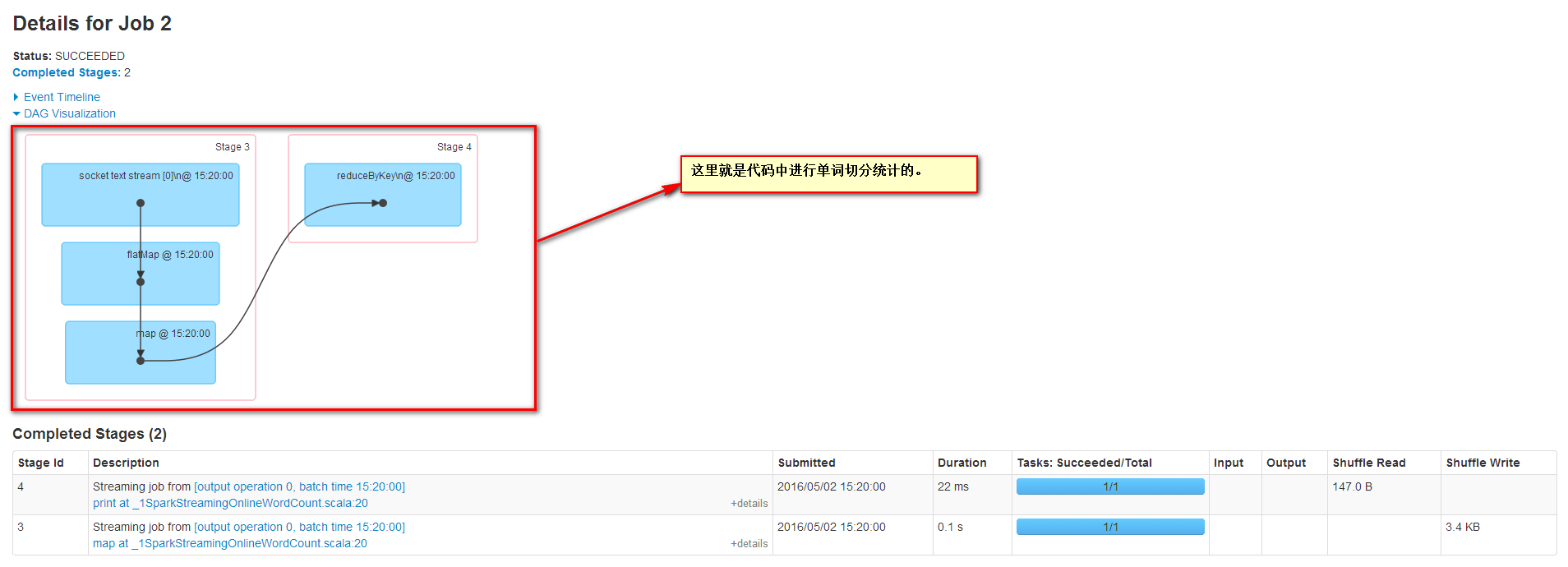
其中Stage3信息如下
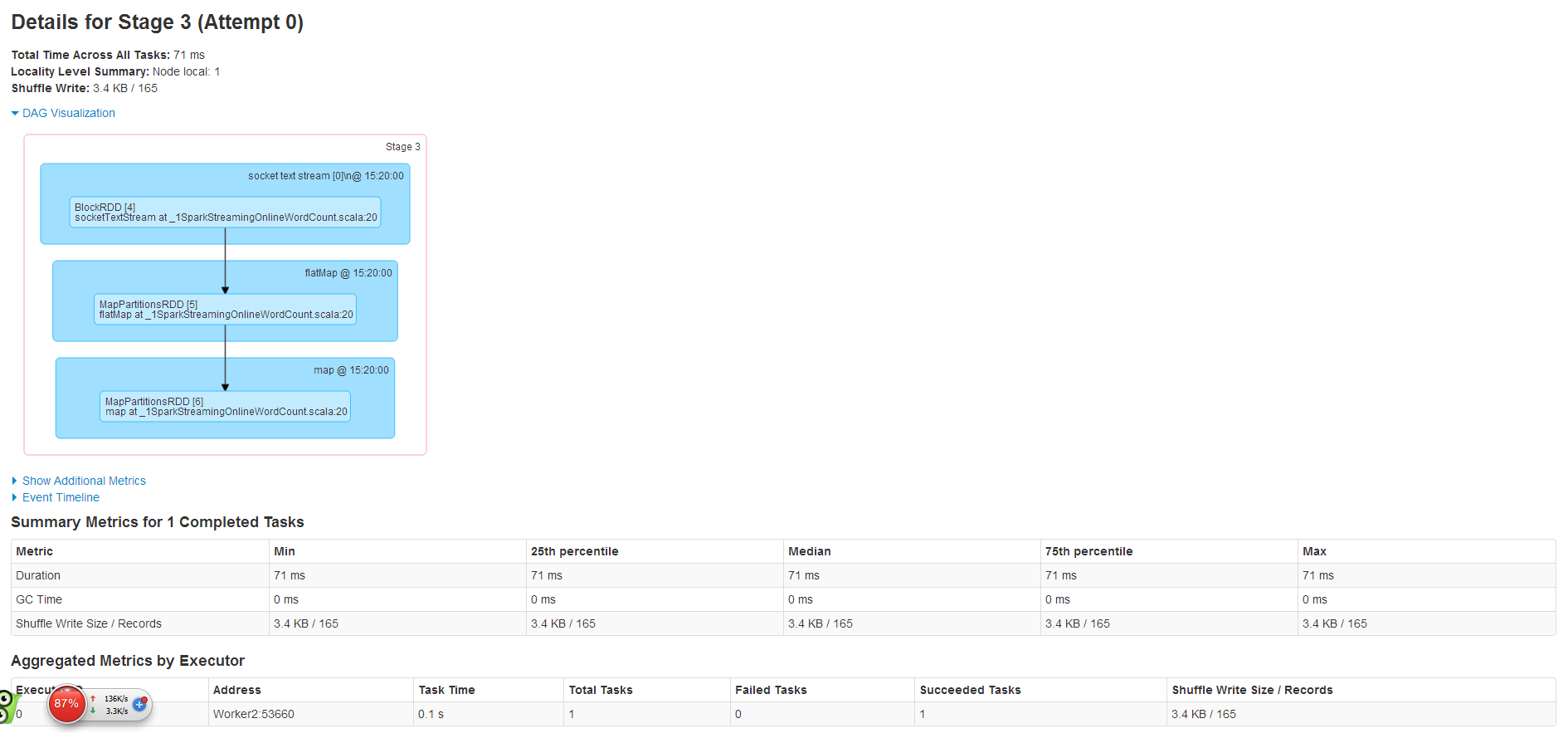
其中Stage4信息如下
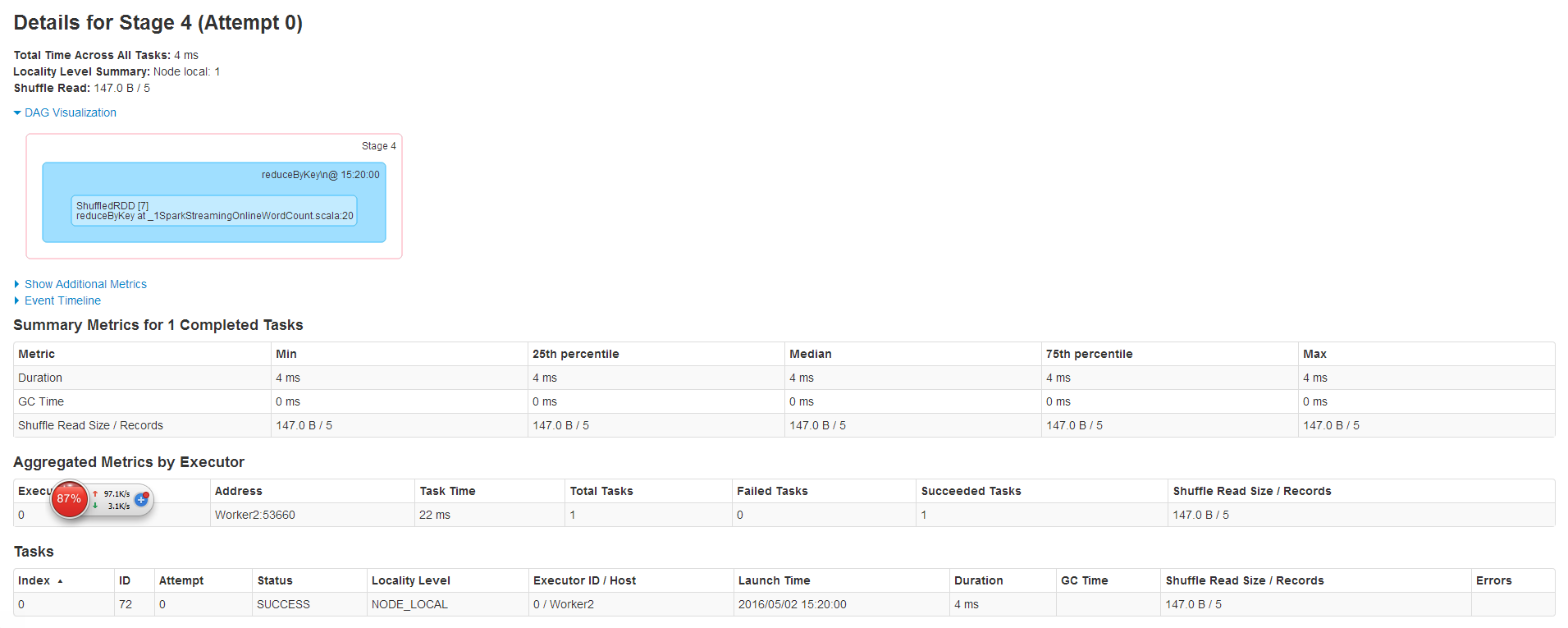
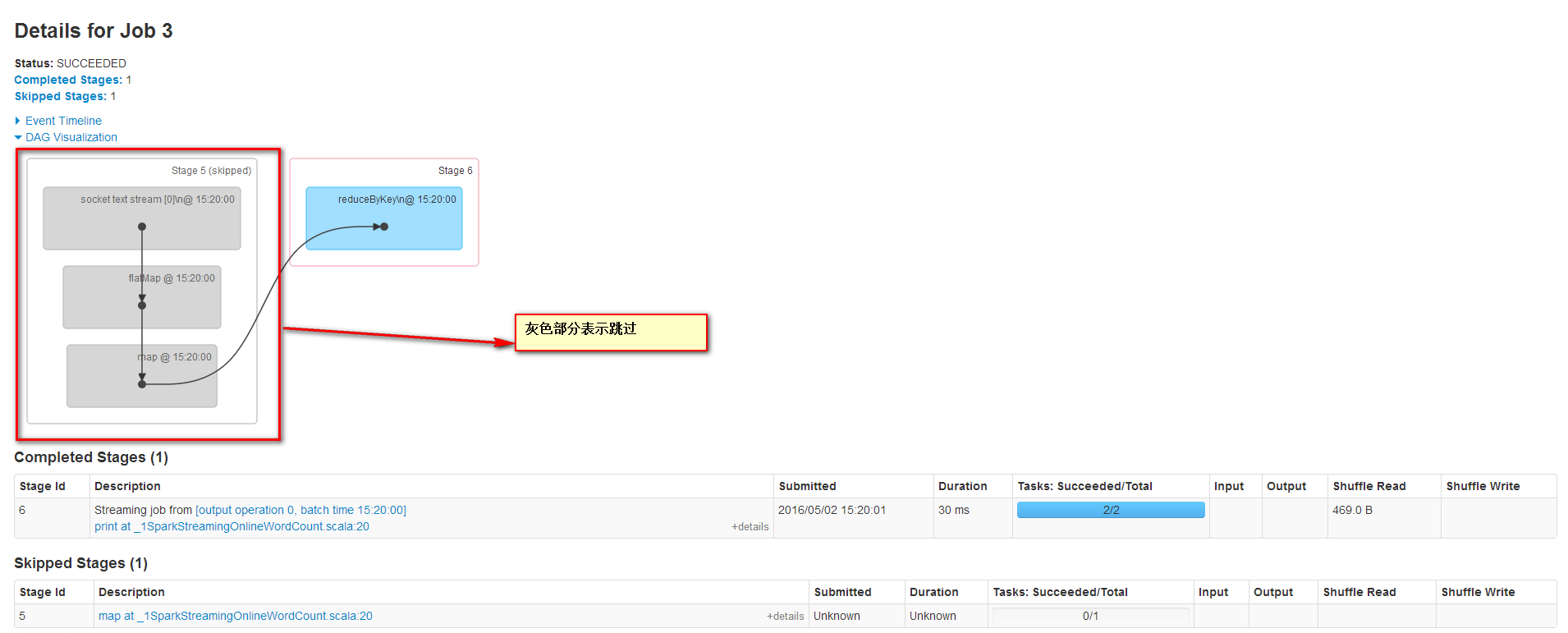
Job3的信息如下,Job3的DAG圖和Job2的DAG圖是一樣的,但是Stage5跳過了。
后面的Job都是在對單詞切分統計。
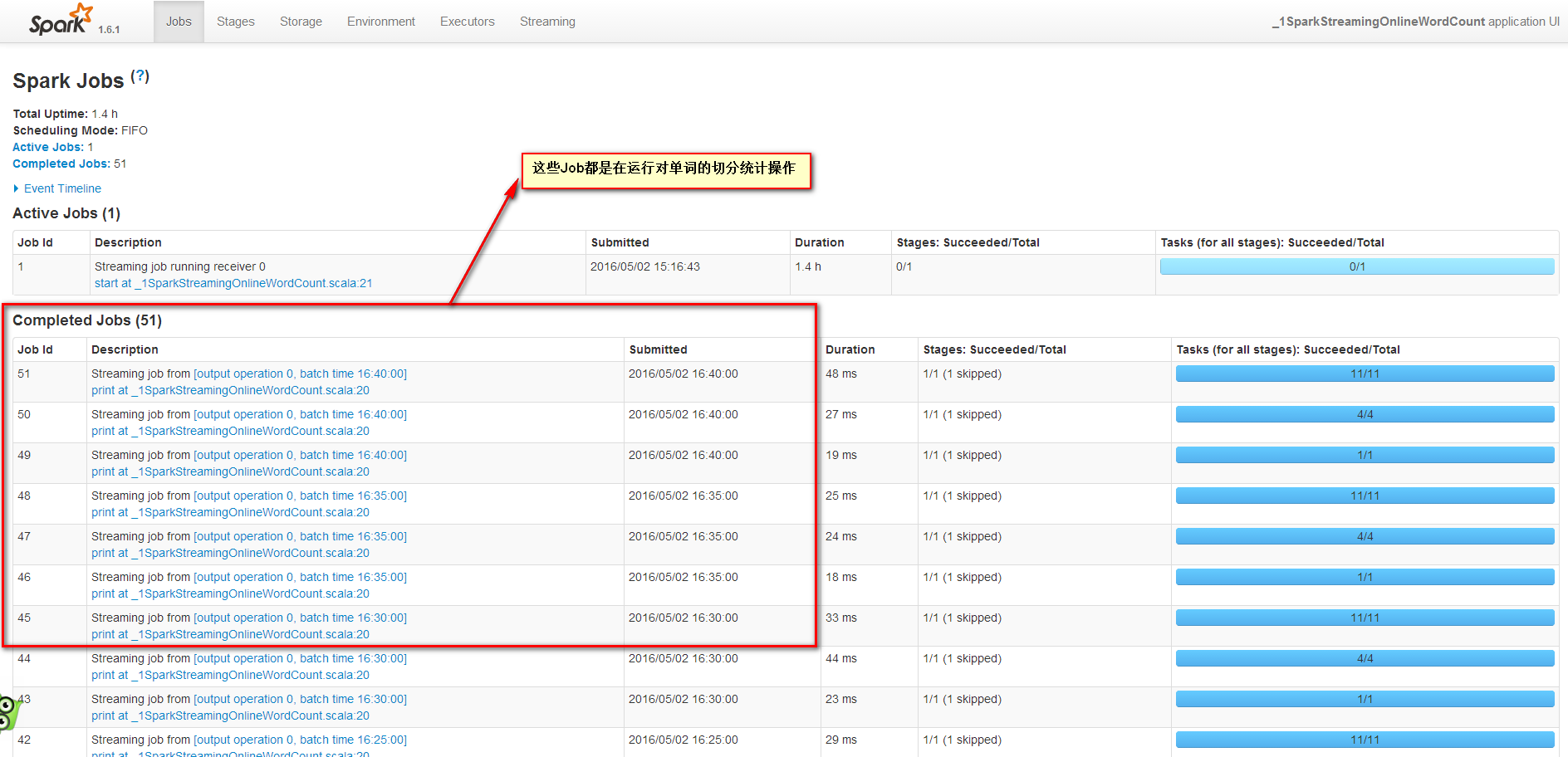
回顧這4個Job,其中2個Job是框架運行的,Job0確保所有slave都注冊上,避免所有的Receiver在同一個節點,為了后面計算負載均衡。Job1為啟動一個數據接收器,運行在一個Executor上的一個Task上,不斷接收數據量數據,然后保存到內存中。Job2和Job3在運行單詞切分統計。
感謝各位的閱讀,以上就是“Spark Streaming的案例分析”的內容了,經過本文的學習后,相信大家對Spark Streaming的案例分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





