溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Redis數據庫結構和持久化分別是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Redis數據庫,持久化
Redis服務器將所有的數據庫都保存在服務器狀態redis.h/redisServer結構的db數組中,每個項目都是一個redis.h/redisDb結構,每個redisDb結構代表一個數據庫。
struct redisServer {
//...
// 一個數組,保存這服務器中的所有數據庫
redisDb *db;
// 服務器數據庫數量
int dbnum;
// ...
}服務器初始化的時候,程序會根據服務器狀態的dbnum屬性來決定創建多少個數據庫,這個屬性值由redis.conf中配置項database選項決定,值默認是16。
切換數據庫使用select +數據庫號來切換,默認是0號數據庫。例如:select 9。
在服務器內部,客戶端狀態redisClient結構的db屬性記錄了客戶端當前的目標數據庫,這是個指向redisDb結構的指針。
typedef struct redisClient {
// ...
// 記錄客戶端當前正在使用的數據庫
redisDb *db;
// ...
} redisClient;Redis是一個key-value數據庫服務器,而每個數據庫都有redis.h/redisDb結構表示,其中dict字典(hash表)保存了數據庫中所有的鍵值對,我們將這個字典成為鍵空間(key space)。
typedef struct redisDb {
// ...
// 數據庫鍵空間,保存數據庫中的所有鍵值對
dict *dict;
// ...
} redisDb;鍵空間和用戶所見的數據庫是直接對應的:
鍵空間的鍵也就是數據庫的鍵,每一個鍵都是一個字符串對象。
鍵空間的值也就是數據庫的值,每個值都可以是字符串對象,列表對象,hash表對象,集合對象和有序對象中的其中一種。
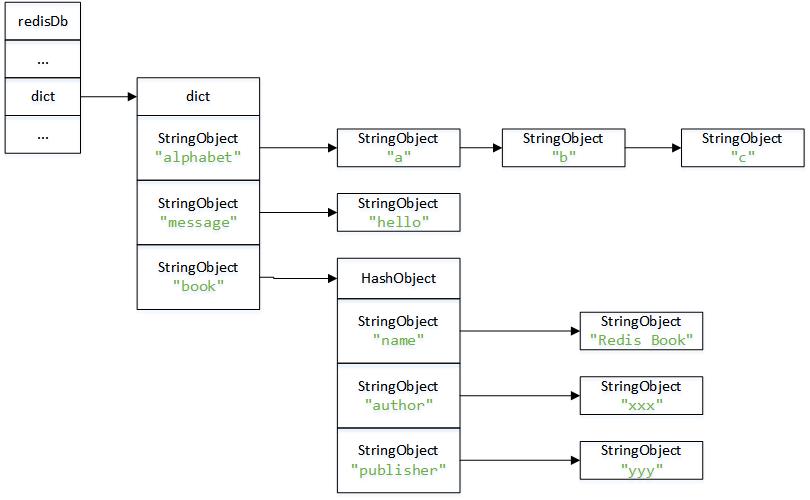
圖解:
redis> SET message "hello world" OK redis> RPUSH alphabet a b c (integer) 3 redis> HMSET book name "Redis Book" author "xxx" publisher "yyy" (integer) 3
SETEX: 這個命令只能用于字符串對象,在設置值的時候一并設置過期時間。
EXPIRE key ttl: 用于設置key存活時間ttl秒
PEXPIRE key ttl: 用于設置key存活時間ttl毫秒
EXPIREAT key timestamp: 設置key在timestamp所指定的秒數時間戳過期
PEXPIREAT key timestamp: 設置key在timestamp所指定的毫秒數時間戳過期
命令有多種,但是最終的執行在底層都會全部轉換成PEXPIRE命令,即設置key在多少時間戳的時候過期。
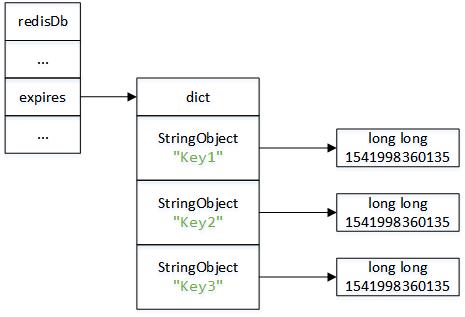
過期時間并沒有直接維護在鍵空間dict字典中,想想,鍵過期之后,我們肯定需要清理內存,這個時候如果一個一個全部遍歷所有的鍵,效率就太低了,因此redis采用了新的字典來保存過期時間。redisDb結構的expires字典保存了數據庫中所有鍵的過期時間。同樣也是dict(hash表)結構
typedef struct redisDb {
// ...
// 過期字典,保存著鍵的過期時間
dict *expires;
// ...
} redisDb;圖解
既然鍵會過期,那肯定需要將其移除,避免其一直占用到內存。那么對于怎么刪除過期的鍵,這個問題可能存在以下幾種不同的策略,我們先來看一看。
定時刪除: 在設置鍵的過期時間的同時,創建一個定時器timer,讓定時器在鍵的過期時間來臨時,立即執行對鍵的刪除操作。
惰性刪除: 放任過期的鍵不管,但是每次從鍵空間中獲取鍵時,都檢查取得的鍵是否過期,如果過期的話就刪除,如果沒有過期就返回。
定期刪除: 每隔一段時間,程序就對數據庫進行一次檢查,刪除里面的過期鍵。至于刪除多少過期鍵,以及要檢查多少個數據庫,由算法來決定。
定時刪除通過使用定時器,該策略可以保證過期鍵會盡可能快的被刪除,并釋放過期鍵所占用的內存。
但是缺點是它對CPU時間是最不友好的,在過期鍵比較多的情況下,刪除鍵這一行為可能會占用相當一部分CPU時間,在內存不緊張但是CPU時間很緊張的情況下,將CPU時間用在刪除和當前任務無關的過期鍵上,無疑是種浪費。
除此之外,創建一個定時器需要用到Redis服務器中的時間事件,而當前時間事件的實現方式是無需鏈表,因此并不能高效的處理大量的時間事件,而且還需要創建大量的定時器。
當過期鍵過多的時候,這種方式有點不太現實。
惰性刪除策略對CPU時間來說是最又好的,程序只會在取出鍵時才對鍵進行過期檢查,這可以保證刪除過期鍵的操作只會在非做不可的情況下進行,并且刪除的目標僅限于當前鍵,該策略不會在刪除其他無關的過期鍵上話費任何CPU時間。
但是這種方式也有缺點,就是對內存是最不友好的。想想如果一個鍵已經過期,而這個鍵又仍然保存在數據庫中,那么只要我們不訪問這個鍵,那么這個鍵就永遠不會被刪除,它所占用的內存就不會釋放(預防杠精,修正一下,down機等事故不算在內)。
使用此種策略時,如果數據庫中存在非常多的過期鍵,而這些件又恰好沒有被訪問到,這時redis就呵呵了吧~~
從上面定時刪除和惰性刪除來看,這兩種方式在單一使用時都有明顯的缺陷。
定時刪除占用太多CPU時間,影響服務器的響應時間和吞吐量。
多想刪除浪費太多內存,有內存泄漏的危險。
定期刪除策略當然就是為了折中這倆東西,這種策略采用每隔一段時間執行一次刪除過期鍵的操作,并限制刪除操作執行的時長和頻率來減少刪除對CPU時間的影響。通過定期刪除,有效的見啥過期鍵帶來的內存浪費。
那么問題來了,每次執行時長多少合適,頻率多少合適呢?如果執行的太頻繁或者時間太長,是不是又退化成了定時刪除。如果執行的太少,或者時間太短,那么也會出現內存浪費的情況。
因此這種情況,就需要很有經驗的大佬來根據情況指定。接下來說說Redis的刪除策略。
Redis服務器在實際使用的是惰性刪除和定期刪除兩種策略,通過配合使用,服務器可以很好的在合理使用CPU時間和避免浪費內存空間之間取得平衡。
其實就是在定期刪除實現的同時,在取值的時候也加上過期驗證而已,很好理解吧。
因為采用了定期刪除的策略,因此肯定存在過期了但是還來不及刪除的情況,這種情況對于Redis的持久化和主從復制有什么影響呢?呵呵,TM的當然沒有影響,有影響就是bug了。
RDB
如果開啟了RDB功能
如果是master,載入RDB文件時程序會對文件保存的鍵進行檢查,只載入未過期的鍵。
如果是slave: 載入所有,但是不影響,因為主從服務器在進行同步的時候,從服務器的數據庫就會被清空。
AOF
AOF模式持久化運行時,如果是數據庫某個鍵已經過期,對AOF不會產生影響,AOF一樣會將此鍵記錄,當鍵被刪除的時候,程序會向AOF文件追加一條DEL命令,來顯示的記錄該鍵已被刪除。
AOF重寫過程中,和生成RDB文件類似,過期的鍵不會保存到重寫后的AOF文件中。
當運行在復制模式下時:
主服務器在刪除一個過期鍵之后,會顯式的向所有從服務器發送一個DEL命令,告知從服務器刪除這個過期鍵。
從服務器再執行客戶端發送的讀命令時,即使碰到過期鍵也不會將其刪除,當然如果過期了,由于會判斷,因此也不會向客戶端返回。
從服務器只有在接到主服務發來的DEL命令之后,才會刪除過期鍵。
通過由主服務器來控制從服務器統一地刪除過期鍵,可以保證主從服務器的數據一致性。
生成RDB文件有兩個命令。
SAVE: 阻塞服務器進程,阻塞期間不能處理任何命令請求,直到RDB文件創建完畢。
BGSAVE: 派生子進程,由子進程負責創建RDB文件,主進程繼續處理命令請求。
RDB文件的載入是在服務器啟動的時候自動執行的,所有Redis并沒有專門用于載入RDB文件的命令,只要服務器再啟動的時候檢測到RDB文件存在,就會自動載入RDB文件(AOF未開啟的情況下)。
看日志:
32188:M 25 Jun 2019 18:34:01.999 # Server initialized 32188:M 25 Jun 2019 18:34:01.999 * DB loaded from disk: 0.000 seconds 32188:M 25 Jun 2019 18:34:01.999 * Ready to accept connections
Redis允許用戶通過配置服務器的save選項,讓服務器每隔一點時間自動執行一次BGSAVE命令。
用戶可以設置多個保存條件,只要其中任一滿足,就會執行BGSAVE命令。
舉例:
# 在900秒之內,對數據庫至少進行了1次修改 save 900 1 # 在300秒之內,對數據庫至少進行了10次修改 save 300 10 # 在60秒之內,對數據庫至少進行了10000次修改 save 60 10000
服務器redisServer維護了dirty和lastsave屬性,用來保存修改計數和上一次執行保存的時間。
struct redisServer {
// ...
// 修改計數器
long long dirty;
// 上一次執行保存的時間
time_t lastsave;
// ...
}每次服務器成功執行一個修改命令之后,程序就會讀dirty計數器進行更新。
為了檢查保存條件是否滿足,Redis的服務器周期性操作函數serverCron默認每隔100毫秒就會執行一次,該函數用于對正在運行的服務器進行維護,他的其中一項工作就是檢查所設置的保存條件是否滿足,如果滿足,就執行BGSAVE命令。

REDIS: 這部分長5個字節,保存著“REDIS” 5個字符,通過這5個字符,程序可以在載入文件時,快速檢查所載入文件是否是RDB文件。
db_version: 長4個字節,它的值是一個字符串表示的整數,記錄了RDB的版本號。
database: 這部分包含著0個或任意多個數據庫以及各個數據庫中的鍵值對數據,如果數據庫為空,那么這個部分也為空,長度為0字節。
EOF: 一個常量,長度為1字節,這個常量標志著RDB文件正文內容結束。
check_sum: 一個8字節無符號整數,保存著一個校驗和,通過對之前4個部分的內容進行計算得出的,用啦檢查RDB文件是否有出錯或者損壞的情況出現。
一個RDB文件的databases部分可以保存任意多個非空數據庫。
比如0號和3號數據庫非空,那么將創建如下一RDB文件,database 0代表0好數據庫中的所有鍵值對數據,database 3代表3號數據庫中的所有鍵值對數據。

每個非空數據庫database num在RDB文件都可以保存為SELECTDB、db_number、key_value_pair三個部分。

SELECTDB: 常量,1字節,當程序遇到這個值的時候,就知道即將讀入的是一個數據庫號碼。
db_num: 保存著一個數據庫號碼,根據號碼的大小不同,這個部分長度科可以是1個2個或5個字節。
key_value_pair: 保存著所有的鍵值對。
當讀入數據庫號碼之后,服務器就會調用SELECT命令切換數據庫,使得之后讀入的鍵值對可以載入到正確的數據庫中。
日常貼個圖:

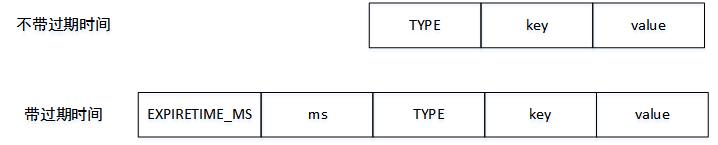
這個部分保存著所有的鍵值對,如果鍵值對帶有過期時間,那么過期時間也會被保存在內。
不帶過期時間的鍵值對在RDB文件中由TYPE、key、value三部分組成。
帶有過期時間的鍵值對在RDB文件中由EXPIRETIME_MS、ms、TYPE、key、value五部分組成。
日常貼個圖。
 ")
")
TYPE表明了當前key的類型(比如REDIS_RDB_TYPE_SET),決定了接下來redis如何讀入和解釋value數據。
key總是一個字符串對象。
value會根據TYPE類型的不同以及保存內容長度的不同而有所不同,這部分就不一一解釋了,喜歡的自己去百度吧。
AOF持久化功能的實現可以分為追加(append)、文件寫入、文件同步(sync)三個步驟。
當AOF持久化功能打開時,服務器再執行完一個寫命令之后,會以協議的格式將其追加到服務器狀態的aof_buf緩沖區末尾。
struct redisServer {
// ...
// AOF緩沖區
sds aof_buf;
// ...
}比如:
redis> set mKey mValue OK
那么服務器知性溫婉之后會將其轉成協議的格式,追加到aof_buf緩沖區末尾
協議格式 *3\r\n$3\r\nSET\r\n$4\r\nmKey\r\n$6\r\nmValue\r\n
Rdis的服務器進程就是一個事件循環,這個循環中的文件事件負責接收客戶端的命令請求,以及向客戶端發送命令回復,而時間事件則負責執行想serverCron函數這樣需要定時運行的函數。
因為服務器在處理文件事件時可能會執行寫命令,使得這些命令內容被追加到aof_buf緩沖區,所有在服務器每次結束一個事件循環之前,他都會調用相應函數(flushAppendOnlyFile),考慮是否需要將aof_buf緩沖區的內容寫入和保存到AOF文件中。
flushAppendOnlyFile函數的行為有服務器配置appendfsync選項的值來決定。
| appendfsync值 | 函數行為 |
|---|---|
| always | 將aof_buf緩沖區的所有內容寫入并同步到AOF文件 |
| everysec | 【系統默認值】將aof_buf緩沖區中的內容寫入到AOF文件,如果上次同步AOF文件的時間已經超過一秒鐘,那么再次對AOF文件進行同步,并且這個同步操作是由一個線程專門負責執行的 |
| no | 將aof_buf緩沖區中的所有內容寫入到AOF文件,單并不對AOF文件進行同步,合適同步由操作系統來決定 |
AOF的優先級比RDB高哦!
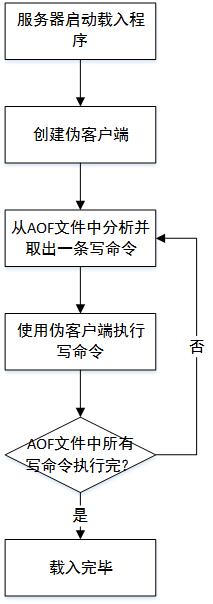
因為AOF文件里面包含了重建數據庫狀態所需的所有寫命令,所以服務器只要讀入并重新執行一遍AOF文件里面保存的寫命令,就可以還原服務器狀態了。因為redis的命令只能在客戶端上下文中執行,所以這里需要使用一個偽客戶端(fake client)。
流程圖:
因為AOF持久化是通過保存被執行的寫命令來記錄數據庫狀態的,隨著服務器運行時間的增加,AOF文件中的內容會越來越多,文件的體積也會越來越大,還原所需的時間也就越多。
比如說一些過期的鍵,在最開始會被寫入,然后后續又會被DEL,又或者我們使用了很多條RPUSH命令來操作一個key的列表數據,等等之類的情況。
這個時候就需要重寫AOF文件,使用新的文件替換掉舊的文件。文件的重寫不需要對現有的AOF文件進行任何讀取分析等操作,而是根據當前數據庫狀態來實現的。
當然,如果列表,hash表,集合。,有序集合這四總可能會帶有多個元素的鍵時,會先檢查數量,如果過多的話,是會分成多條命令來記錄的,而不是單單使用一條命令,REDIS_AOF_REWRITE_ITEMS_PRE_CMD常量的值(64)決定了這個數量,也就是說每條指令最多將寫入64個元素,剩下的將繼續判斷并決定用幾條指令來寫入
AOF的重寫也是有子程序執行,這樣主程序可以繼續執行命令請求。這個時候服務器接收的新的命令也有可能對數據庫進行了修改,從而導致當前數據庫狀態和重寫后的AOF文件所保存的數據庫狀態不一致。
因此Redis服務器設置了一個AOF重寫緩沖區,這個緩沖區在服務器創建子進程之后開始使用,當執行完一個寫命令之后,它會同時將這個寫命令發送給AOF緩沖區和AOF重寫緩沖區。
這樣一來AOF緩沖區的內容會定期被寫入和同步到AOF文件,對現有的AOF文件的處理工作照常進行。
當完成AOF重寫工作后,子進程會向父進程發送一個信號,父進程接收到信號之后,調用一個信號函數處理器,并執行以下工作:
將AOF重寫緩沖區的所有內容寫入到新AOF文件中,這是新AOF文件數據庫狀態和當前一致。
對新的AOF文件進行重命名,原子的(atomic)覆蓋現有的AOF文件,完成新舊AOF文件的替換。
日常流程:
| 時間 | 服務器進程(父進程) | 子進程 |
|---|---|---|
| T1 | SET k1 v1 | |
| T2 | SET k1 v2 | |
| T3 | SET k1 v3 | |
| T4 | 創建子進程,執行AOF文件重寫 | 開始AOF文件重寫 |
| T5 | SET k2 v2 | 執行重寫操作 |
| T6 | SET k3 v3 | 執行重寫操作 |
| T7 | SET k4 v4 | 完成AOF重寫,向父進程發送信號 |
| T8 | 接收到子進程發來的信號,將命令SET k2 v2,SET k3 v3,SET k4 v4追加到新的AOF文件末尾 | |
| T9 | 用新AOF文件覆蓋舊AOF文件 |
“Redis數據庫結構和持久化分別是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





