溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關elasticsearch7.x中的IDF該怎么調試,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
TF-IDF 是elasticsearch中的默認打分機制(與Lucene一樣),解釋:
一個詞條出現在某個文檔中的次數越多,它就越相關。但是詞條出現在不同文檔中的次數越多,它就越不相關。
TF 詞頻,詞條在文檔中出現的次數
比如現在有這樣兩個文檔,搜索Elasticsearch時,文檔2應該具有更高的得分,文檔1的詞頻是1,文檔2的詞頻是2
1、We will discuss Elasticsearch at the nex Big Data group 2、Tuesday the Elasticsearch team will gather to answer questions about Elasticsearch
IDF 逆文檔頻率,詞條在索引下所有文檔中出現的次數
比如現在有這樣三個文檔,the在每一個文檔中都存在,假如我們搜索the score時,如果沒有IDF的話,最先返回的文檔可能是不準確的,IDF均衡了常見詞的相關性影響
1、We ues Elasticsearch to power the search for our website 2、The developers like Elasticsearch so far 3、The scoring of documents is calculated by the scoring formula
當查詢結果與我們預期出現不符時,可以使用"explain": true來調試
GET /full_text_test123/_search
{
"query": {
"match": {
"content": "北京市"
}
},
"explain": true
}在知道文檔ID的情況下,如果想查詢某文檔為什么沒有被查詢出來可以使用_explain API
GET /full_text_test123/_explain/1
{
"query": {
"match": {
"content": "云南省"
}
}
}使用boost字段來設置評分系數 ,當使用 bool 或 and/or/not 等組合查詢時,boost查詢才更有意義
bool 查詢指定"北京市"優先級為10,云南省為1
GET /full_text_test123/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": {
"query" : "北京市",
"boost" : 10
}
}
},
{
"match": {
"content": {
"query" : "云南省",
"boost" : 1
}
}
}
]
}
}
}查詢的結果,可以看到北京市的幾個鎮排列在前
"hits" : [
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "1",
"_score" : 7.315132,
"_source" : {
"title" : "回龍觀鎮",
"content" : "中華人民共和國北京市昌平區回龍觀鎮",
"geolocation" : "40.0764332591,116.3429765651",
"clicknum" : 102,
"date" : "2019-01-01"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "3",
"_score" : 7.315132,
"_source" : {
"title" : "小湯山鎮",
"content" : "中華人民共和國北京市昌平區小湯山鎮",
"geolocation" : "40.1809900000,116.3915700000",
"clicknum" : 202,
"date" : "2019-03-03"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "2",
"_score" : 7.156682,
"_source" : {
"title" : "沙河鎮",
"content" : "中華人民共和國北京市昌平區沙河鎮",
"geolocation" : "40.1481760748,116.2889957428",
"clicknum" : 92,
"date" : "2019-02-02"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.4350727,
"_source" : {
"title" : "勐侖鎮",
"content" : "中華人民共和國云南省西雙版納自治州勐臘縣孟侖鎮",
"geolocation" : "21.9481406582,100.4479980469",
"clicknum" : 330,
"date" : "2019-10-05"
}
}
]如果我們使用的是multi_match查詢,該如何指定評分系數呢,可以使用^符合,如下content字段評分系數是3,title是4,所以以title匹配的結果優先content次之
GET /full_text_test123/_search
{
"query": {
"multi_match": {
"query": "北京市",
"fields": ["content^3","title^4"]
}
}
}上面兩種是比較簡單的評分方法,讓我們看一看elasticsearch為用戶提供的更高一級的方式
function_score 還提供了其他五種修改評分的方法分別是:
filter,設置內容符合過濾條件的文檔為指定評分
field_value_factor,使用文檔中的參數作為系數來影響評分,如消息的評論數量越多評分越高
script_score,使用腳本來計算評分系數,可以使用doc['fieldname']訪問文檔中某字段的值,比如使用Math.log(doc['attendees'].values.size()) * myweight,其中myweight是查詢時params字段中指定的參數
random_score,隨機分配一個數值,在某些場景下希望每次返回的數據都不一樣可以使用這個函數
衰減功能(linear線性曲線、gauss高斯曲線、exp指數曲線)
搜索出北京市昌平區關鍵字的文檔,通過functions設置評分,根據需求設置優先級
這里的weight和上面示例中的boost的區別是,普通boost是按照標準化來增加分數,而weight是乘以一個常數
GET full_text_test123/_search
{
"query": {
"function_score": {
"query": {"match": {
"content": "北京市昌平區"
}},
"functions": [
{
"weight": 2,
"filter": {"match":{"content":"沙河鎮"}}
},
{
"weight": 3,
"filter": {"match":{"content":"回龍觀鎮"}}
}
],
"score_mode": "max",
"boost_mode": "replace"
}
}
}結果
"hits" : [
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "1",
"_score" : 3.0,
"_source" : {
"title" : "回龍觀鎮",
"content" : "中華人民共和國北京市昌平區回龍觀鎮",
"geolocation" : "40.0764332591,116.3429765651",
"clicknum" : 102,
"date" : "2019-01-01"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "2",
"_score" : 3.0,
"_source" : {
"title" : "沙河鎮",
"content" : "中華人民共和國北京市昌平區沙河鎮",
"geolocation" : "40.1481760748,116.2889957428",
"clicknum" : 92,
"date" : "2019-02-02"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "小湯山鎮",
"content" : "中華人民共和國北京市昌平區小湯山鎮",
"geolocation" : "40.1809900000,116.3915700000",
"clicknum" : 202,
"date" : "2019-03-03"
}
}
]score_mode,從每個單獨的函數而來的得分是如何合并的,分別有如下幾種設置
multiply,默認值
sum
avg
first
max
min
boost_mode,從函數得到的得分如何同原始得分合并,原始得分指的是示例中的content:"北京市昌平區"的查詢,分別有如下幾種設置
sum,評分_score與函數值間的和
max,評分_score與函數值間的較大值
min,評分_score與函數值間的較小值
replace,將函數得分替換為原始得分
field_value_factor,使用文檔中的參數作為系數來影響評分
field:指定是文檔中的哪個字段名稱參與計算
factor:點擊次數要乘以的評分倍數
modifier:評分的計算方式,默認為none,共分為以下幾種(log、log1p、log2p、ln、ln1p、ln2p、square、sqrt、reciprocal)
點擊率越高優先級越高
GET full_text_test123/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "北京市"
}
},
"functions": [
{
"field_value_factor": {
"field": "clicknum",
"factor": 2.2,
"modifier": "log1p"
}
}
],
"score_mode": "max",
"boost_mode": "replace"
}
}
}結果
[
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.6487503,
"_source" : {
"title" : "小湯山鎮",
"content" : "中華人民共和國北京市昌平區小湯山鎮",
"geolocation" : "40.1809900000,116.3915700000",
"clicknum" : 202,
"date" : "2019-03-03"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "1",
"_score" : 2.352954,
"_source" : {
"title" : "回龍觀鎮",
"content" : "中華人民共和國北京市昌平區回龍觀鎮",
"geolocation" : "40.0764332591,116.3429765651",
"clicknum" : 102,
"date" : "2019-01-01"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.308351,
"_source" : {
"title" : "沙河鎮",
"content" : "中華人民共和國北京市昌平區沙河鎮",
"geolocation" : "40.1481760748,116.2889957428",
"clicknum" : 92,
"date" : "2019-02-02"
}
}
]使用腳本來計算評分系數,可以使用doc['fieldname']訪問文檔中某字段的值,比如使用Math.log(doc['attendees'].values.size()) * myweight,其中myweight是查詢時params字段中指定的參數
source:腳本函數(在7.x版本和舊版有細微的差別,在source中指定腳本)
params:我們自定義的對象
GET full_text_test123/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "北京市"
}
},
"functions": [
{
"script_score": {
"script": {
"source": "doc['clicknum'].value * params.myweight",
"params": {
"myweight":3
}
}
}
}
],
"score_mode": "max",
"boost_mode": "replace"
}
}
}結果
[
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "3",
"_score" : 606.0,
"_source" : {
"title" : "小湯山鎮",
"content" : "中華人民共和國北京市昌平區小湯山鎮",
"geolocation" : "40.1809900000,116.3915700000",
"clicknum" : 202,
"date" : "2019-03-03"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "1",
"_score" : 306.0,
"_source" : {
"title" : "回龍觀鎮",
"content" : "中華人民共和國北京市昌平區回龍觀鎮",
"geolocation" : "40.0764332591,116.3429765651",
"clicknum" : 102,
"date" : "2019-01-01"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "2",
"_score" : 276.0,
"_source" : {
"title" : "沙河鎮",
"content" : "中華人民共和國北京市昌平區沙河鎮",
"geolocation" : "40.1481760748,116.2889957428",
"clicknum" : 92,
"date" : "2019-02-02"
}
}
]隨機分配一個數值,在某些場景下希望每次返回的數據都不一樣可以使用這個函數
seed:隨機數的種子,如果兩次查詢seed相同,那么結果頁相同
官網對seed和field字段的解釋
Random
The
random_scoregenerates scores that are uniformly distributed from 0 up to but not including 1. By default, it uses the internal Lucene doc ids as a source of randomness, which is very efficient but unfortunately not reproducible since documents might be renumbered by merges.In case you want scores to be reproducible, it is possible to provide a
seedandfield. The final score will then be computed based on this seed, the minimum value offieldfor the considered document and a salt that is computed based on the index name and shard id so that documents that have the same value but are stored in different indexes get different scores. Note that documents that are within the same shard and have the same value forfieldwill however get the same score, so it is usually desirable to use a field that has unique values for all documents. A good default choice might be to use the_seq_nofield, whose only drawback is that scores will change if the document is updated since update operations also update the value of the_seq_nofield.
翻譯如下(使用軟件翻譯的湊合看吧)
可以在不設置字段的情況下設置種子,但不建議這樣做,因為這需要在_id字段上加載fielddata,這會消耗大量內存。
默認情況下,它使用內部lucene doc id作為隨機性的來源,這是非常有效的,但不幸的是不可復制,因為文檔可能被合并重新編號。
如果您希望分數是可復制的,可以提供種子和字段。最后的得分將基于這個種子、所考慮文檔的字段最小值和基于索引名和shard id計算的salt,這樣具有相同值但存儲在不同索引中的文檔將得到不同的得分。請注意,在同一個shard中并且字段值相同的文檔將得到相同的分數,因此通常需要對所有文檔使用具有唯一值的字段一個好的默認選擇可能是使用_seq_no字段,其唯一的缺點是,如果文檔被更新,分數將改變,因為更新操作也會更新seq no字段的值
GET full_text_test123/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "北京市"
}
},
"functions": [
{
"random_score": {
"seed": 314159265359,
"field": "_seq_no"
}
}
],
"score_mode": "max",
"boost_mode": "replace"
}
}
}衰減函數根據文檔的數值字段值與用戶給定的原點之間的距離衰減函數,為文檔打分,類似于范圍的查詢。
衰減功能提供三種曲線(linear線性曲線、gauss高斯曲線、exp指數曲線),這三種類型的衰減類型可以有4個配置參數
origin,曲線的中心點或字段可能的最佳值,落在原點origin上的文檔評分_score為滿分,是用戶希望的最高峰值最高分,假如在計算 “小明” 距離 “圖書館” 位置距離的例子中表示 “小明” 當前的位置,或在某日期到今天的例子中表示今天
offset,以原點origin為中心點,為其設置一個非零的偏移量offset覆蓋一個范圍(origin+/-offset這個范圍),而不只是單個原點,在范圍內內的所有評分_score都是滿分,默認是0
scale:衰減率,即一個文檔從原點origin下落時,評分_score改變的速度。
decay:當字段吧值衰減到scale指定的值時,衰減到decay
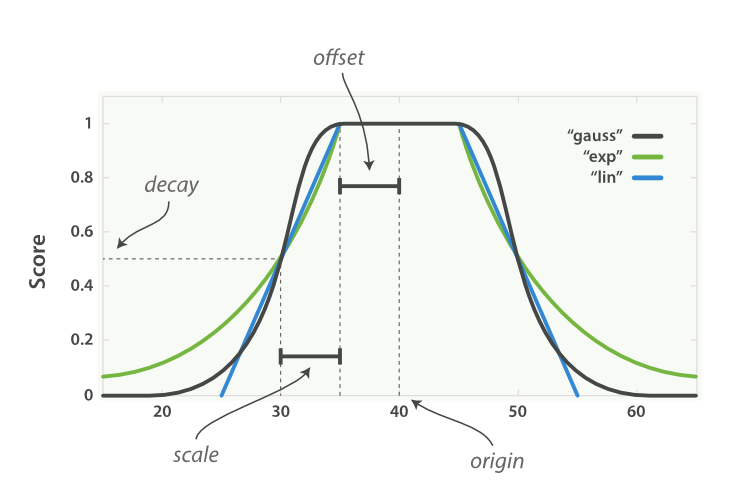
圖中所有曲線的原點origin(即中心點)的值都是40 ,office是5 ,也就是在范圍40 - 5 <= value <= 40+5內的所有值都會被當作原點origin處理——所有這些點的評分都是滿分。
在此范圍之外,評分開始衰減,衰減率由scale值(此例中的值為5)和 衰減值 decay(此例中為默認值0.5 )共同決定。結果是所有三個曲線在origin +/- (offset + scale)處的評分都是0.5,即點30和50處。
linear 、 exp 和 gauss (線性、指數和高斯)函數三者之間的區別在于范圍( origin +/- (offset + scale) )之外的曲線形狀:
linear 線性函數是條直線,一旦直線與橫軸 0 相交,所有其他值的評分都是 0.0 。
exp 指數函數是先劇烈衰減然后變緩。
gauss 高斯函數是鐘形的——它的衰減速率是先緩慢,然后變快,最后又放緩。
選擇曲線的依據完全由期望評分 _score 的衰減速率來決定,即距原點 origin 的值。
使用經緯度"47.7226969027,128.6911010742"(黑龍江省伊春市)進行查詢
GET full_text_test123/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "中華人民共和國"
}
},
"functions": [
{
"gauss": {
"geolocation": {
"origin": "47.7226969027,128.6911010742",
"offset": "1km",
"scale": "3000km",
"decay": 0.25
}
}
}
],
"score_mode": "max",
"boost_mode": "replace"
}
}
}結果
[
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.07333869,
"_source" : {
"title" : "翠烏鎮",
"content" : "中華人民共和國黑龍江省伊春市燕翠烏鎮",
"geolocation" : "47.7226969027,128.6911010742",
"clicknum" : 50,
"date" : "2019-06-05"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.06053602,
"_source" : {
"title" : "小湯山鎮",
"content" : "中華人民共和國北京市昌平區小湯山鎮",
"geolocation" : "40.1809900000,116.3915700000",
"clicknum" : 202,
"date" : "2019-03-03"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.060268145,
"_source" : {
"title" : "回龍觀鎮",
"content" : "中華人民共和國北京市昌平區回龍觀鎮",
"geolocation" : "40.0764332591,116.3429765651",
"clicknum" : 102,
"date" : "2019-01-01"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.05901804,
"_source" : {
"title" : "沙河鎮",
"content" : "中華人民共和國北京市昌平區沙河鎮",
"geolocation" : "40.1481760748,116.2889957428",
"clicknum" : 92,
"date" : "2019-02-02"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.054671418,
"_source" : {
"title" : "燕郊鎮",
"content" : "中華人民共和國河北省廊坊市三河市燕郊鎮",
"geolocation" : "39.9601300000,116.8147600000",
"clicknum" : 100,
"date" : "2019-04-05"
}
},
{
"_index" : "full_text_test123",
"_type" : "_doc",
"_id" : "6",
"_score" : 0.0073663373,
"_source" : {
"title" : "勐侖鎮",
"content" : "中華人民共和國云南省西雙版納自治州勐臘縣孟侖鎮",
"geolocation" : "21.9481406582,100.4479980469",
"clicknum" : 330,
"date" : "2019-10-05"
}
}
]以上就是elasticsearch7.x中的IDF該怎么調試,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





