溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
用戶行為日志:
為什么要記錄用戶訪問行為日志:
用戶行為日志生成渠道:
用戶行為日志大致內容:
用戶行為日志分析的意義:
離線數據處理流程:
流程示意圖: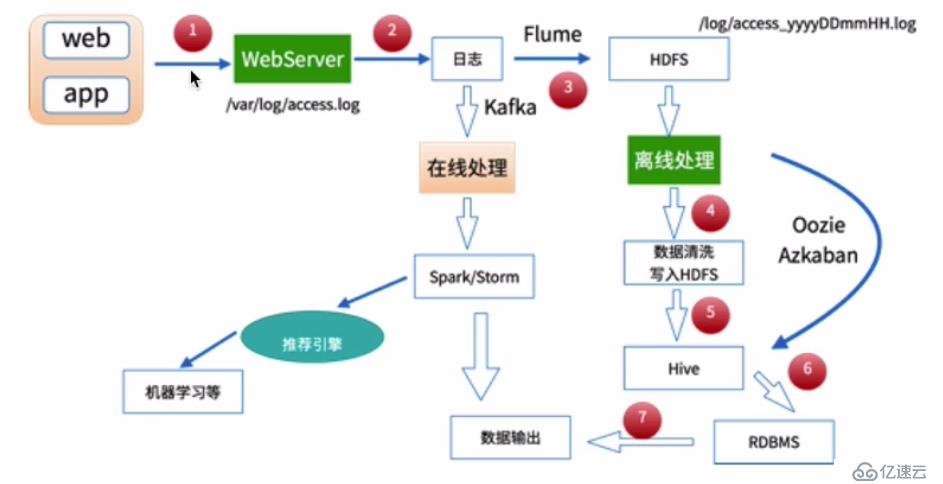
需求:
日志片段如下:
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getadv HTTP/1.1" 200 813 "www.xxx.com" "-" cid=0×tamp=1478707261865&uid=2871142&marking=androidbanner&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=f51e97d1cb1a9caac669ea8acc162b96 "mukewang/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.134.244:80 200 0.027 0.027
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh3/1.4.2" "-" - - - 0.000首先我們需要根據日志信息抽取出瀏覽器信息,針對不同的瀏覽器進行統計操作。雖然可以自己實現這個功能,但是懶得再造輪子了,所以我在GitHub找到了一個小工具可以完成這個功能,GitHub地址如下:
https://github.com/LeeKemp/UserAgentParser
通過git clone或者瀏覽器下載到本地后,使用命令行進入到其主目錄下,然后通過maven命令對其進行打包并安裝到本地倉庫里:
$ mvn clean package -DskipTest
$ mvn clean install -DskipTest安裝完成后,在工程中添加依賴以及插件:
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0-cdh6.7.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<!-- 添加UserAgent解析的依賴 -->
<dependency>
<groupId>com.kumkee</groupId>
<artifactId>UserAgentParser</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>
<!-- mvn assembly:assembly -->
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>然后我們編寫一個測試用例來測試一下這個解析類,因為之前并沒有使用過這個工具,所以對于一個未使用過的工具,要養成在工程中使用之前對其進行測試的好習慣:
package org.zero01.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
/**
* @program: hadoop-train
* @description: UserAgent解析測試類
* @author: 01
* @create: 2018-04-01 22:43
**/
public class UserAgentTest {
public static void main(String[] args) {
String source = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36";
UserAgentParser userAgentParser = new UserAgentParser();
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
String engine = agent.getEngine();
String engineVersion = agent.getEngineVersion();
String os = agent.getOs();
String platform = agent.getPlatform();
boolean isMobile = agent.isMobile();
System.out.println("瀏覽器:" + browser);
System.out.println("引擎:" + engine);
System.out.println("引擎版本:" + engineVersion);
System.out.println("操作系統:" + os);
System.out.println("平臺:" + platform);
System.out.println("是否是移動設備:" + isMobile);
}
}控制臺輸出結果如下:
瀏覽器:Chrome
引擎:Webkit
引擎版本:537.36
操作系統:Windows 7
平臺:Windows
是否是移動設備:false從打印結果可以看到,UserAgent的相關信息都正常獲取到了,我們就可以在工程中進行使用這個工具了。
創建一個類,編寫代碼如下:
package org.zero01.hadoop.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @program: hadoop-train
* @description: 使用MapReduce來完成統計瀏覽器的訪問次數
* @author: 01
* @create: 2018-04-02 14:20
**/
public class LogApp {
/**
* Map: 讀取輸入的文件內容
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
LongWritable one = new LongWritable(1);
private UserAgentParser userAgentParser;
protected void setup(Context context) throws IOException, InterruptedException {
userAgentParser = new UserAgentParser();
}
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行日志信息
String line = value.toString();
String source = line.substring(getCharacterPosition(line, "\"", 7) + 1);
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
// 通過上下文把map的處理結果輸出
context.write(new Text(browser), one);
}
protected void cleanup(Context context) throws IOException, InterruptedException {
userAgentParser = null;
}
}
/**
* Reduce: 歸并操作
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value : values) {
// 求key出現的次數總和
sum += value.get();
}
// 將最終的統計結果輸出
context.write(key, new LongWritable(sum));
}
}
/**
* 獲取指定字符串中指定標識的字符串出現的索引位置
*
* @param value
* @param operator
* @param index
* @return
*/
private static int getCharacterPosition(String value, String operator, int index) {
Matcher slashMatcher = Pattern.compile(operator).matcher(value);
int mIdex = 0;
while (slashMatcher.find()) {
mIdex++;
if (mIdex == index) {
break;
}
}
return slashMatcher.start();
}
/**
* 定義Driver:封裝了MapReduce作業的所有信息
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
// 準備清理已存在的輸出目錄
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
System.out.println("output file exists, but is has deleted");
}
// 創建Job,通過參數設置Job的名稱
Job job = Job.getInstance(configuration, "LogApp");
// 設置Job的處理類
job.setJarByClass(LogApp.class);
// 設置作業處理的輸入路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 設置map相關參數
job.setMapperClass(LogApp.MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 設置reduce相關參數
job.setReducerClass(LogApp.MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 設置作業處理完成后的輸出路徑
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}在工程目錄下打開控制臺,輸入如下命令進行打包:
mvn assembly:assembly打包成功:
將這個jar包上傳到服務器上:
[root@localhost ~]# rz # 使用的是Xshell工具,所以直接使用rz命令即可上傳文件
[root@localhost ~]# ls |grep hadoop-train-1.0-jar-with-dependencies.jar # 查看是否上傳成功
hadoop-train-1.0-jar-with-dependencies.jar
[root@localhost ~]#把事先準備好的日志文件上傳到HDFS文件系統中:
[root@localhost ~]# hdfs dfs -put ./10000_access.log /
[root@localhost ~]# hdfs dfs -ls /10000_access.log
-rw-r--r-- 1 root supergroup 2769741 2018-04-02 22:33 /10000_access.log
[root@localhost ~]#執行如下命令
[root@localhost ~]# hadoop jar ./hadoop-train-1.0-jar-with-dependencies.jar org.zero01.hadoop.project.LogApp /10000_access.log /browserout執行成功: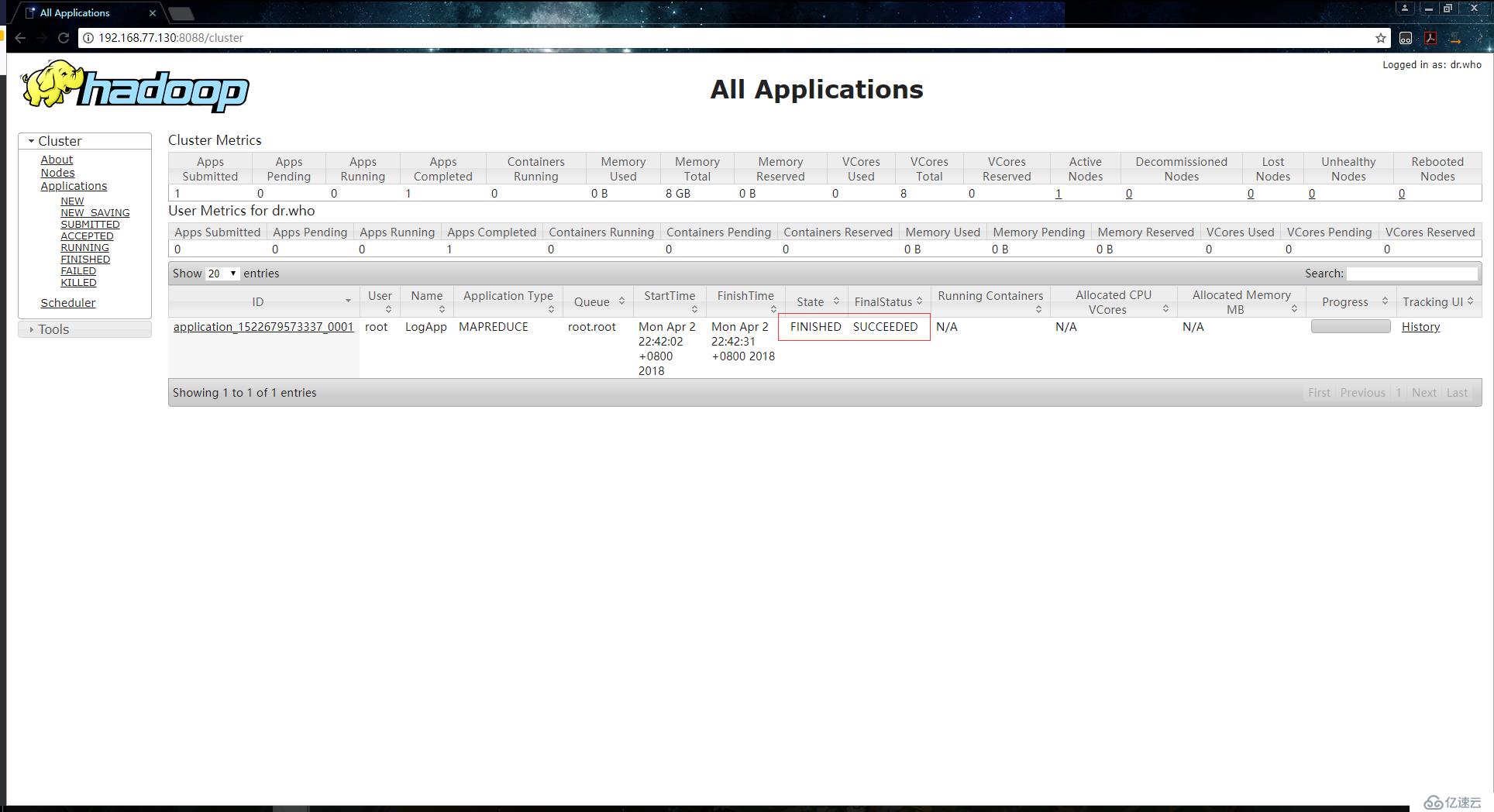
查看處理結果:
[root@localhost ~]# hdfs dfs -ls /browserout
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-04-02 22:42 /browserout/_SUCCESS
-rw-r--r-- 1 root supergroup 56 2018-04-02 22:42 /browserout/part-r-00000
[root@localhost ~]# hdfs dfs -text /browserout/part-r-00000
Chrome 2775
Firefox 327
MSIE 78
Safari 115
Unknown 6705
[root@localhost ~]# 免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





