溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Raft共識算法是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Raft共識算法是什么”吧!
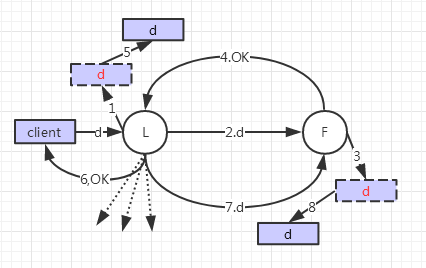
Raft算法主要應用于分布式集群系統中,如果保證高可用和數據一致性,它主要定義兩方面的規范:選主(Leader Election)和復制日志(Log Replication)
Raft定義了集群節點三個狀態:Leader(主)、Follower (從)、Candidate(候選)
主:負責與對接外部輸入 ,并保持與從的心跳
從:備份數據、主掛了的時候要挑起重擔
候選:當從timeout時間內(150ms 到 300ms,每個節點不一樣)沒有收到主的心跳,轉為此狀態
從以下幾種情形中分析選主是如何運作的
開始所有節點都是Follower狀態,當其中一個節點在timeout過后,就會轉變成Candidate并向其它節點發送投票請求,并開始新的timeout。
超過半數Follower節點收到請求并回復確認后,Candidate節點就會轉變成Leader節點,并向Follower節點發送心跳
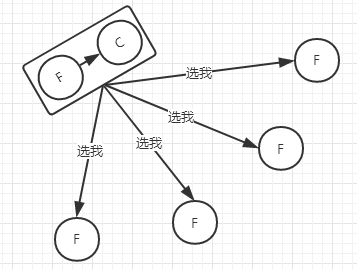

當有多個Candidate時,會向其余節點發送選舉請求,Candidate節點會拒絕其它節點的請求,Follower節點接收到其中一個Candidate節點請求后,會拒絕同一選舉輪回的其它請求,如果此時其中一個節點獲得半數節點同意,自動成為Leader,如果兩個Candidate節點沒有分出勝負后,當timeout節點會發起第二輪選舉請求,此時就看誰先timeout結束并獲得半數節點同意,就成為Leader

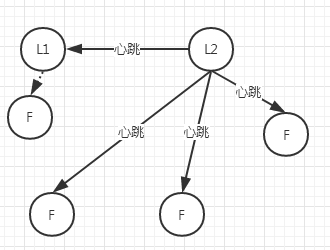
數據復制主要是為了保證數據的可靠和一致性,當數據變更時,Leader將數據同步給Follower
從以下幾種場景如何執行數據復制
大致可以分為8個步驟
外部向Leader發布數據,
1.Leader將數據保存,狀態為uncommit
2.Leader將數據通過appendEntries發送給Follower
3.Follower將數據保存,狀態為uncommit
4.Follower返回確認給Leader
5.Leader收到半數以上Follower的確認后,將數據狀態更改為commit
6.Leader返回確認
7.Leader再次通過appendEntries將數據發送給Follower
8.Follower將數據狀態更改為commit
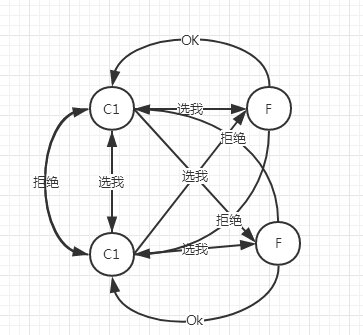
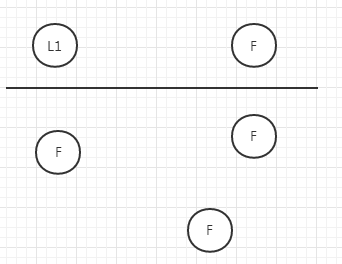
也就是在部分節點網絡問題沒法通信情況下
沒有Leader的一方,通過選舉得到leader,此Leader的選舉輪次+1
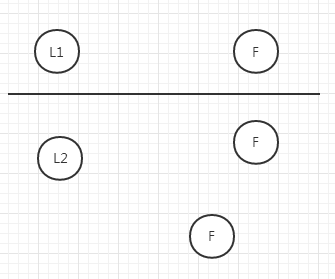
此時就出現了兩個Leader可以對外提供服務
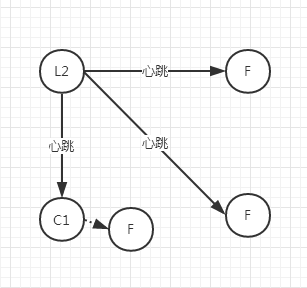
如果此時有外部數據進來,分別傳給了L1和L2,未超過半數的一方因為得到確認的數量也未達到半數,所以數據都是uncommit狀態,返回也是失敗
而超過半數的一方數據為commit
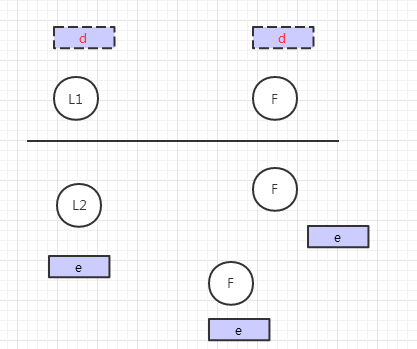
此時如果網絡恢復了,通過選舉規則,輪次高的Leader一方為繼續為Leader,另一方降級為Follower
此時uncommite的數據將被刪除,未同步的數據將會被補充
到此,相信大家對“Raft共識算法是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





