溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“hyperledger fabric中Raft共識插件的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“hyperledger fabric中Raft共識插件的示例分析”這篇文章吧。
共識算法可以讓機群協同工作,并且可以容忍部分成員主機的故障。通常我們提到主機的故障會區分兩種情況對待:拜占庭故障和非拜占庭故障。
比特幣是第一個解決了拜占庭故障的去中心化系統,它的方法是使用工作量證明共識(POW)。在一個存在拜占庭故障的系統中,不僅會發生主機崩潰的問題,而且某些成員可能會存在惡意行為去影響整個系統的決策過程。
如果一個分布式系統可以處理拜占庭故障,那么它就可以容忍任何類型的錯誤發生。常見的支持拜占庭故障的共識算法包括PoW、PoS、PBFT和RBFT。
Raft只能處理非拜占庭故障,也就是說Raft共識可以容忍系統崩潰、網絡中斷/延遲/包丟失等故障。常見的支持非拜占庭故障的共識算法或系統包括:Raft、Kafka、Paxos和Zookeeper。
那么,Hyperledger Fabric為什么不使用可以容忍拜占庭故障的共識機制呢?那樣不是更安全嗎?
一個原因在于系統的復雜性與安全性的設計折中。假設一個系統中可能同時有n個節點發生拜占庭故障,那么拜占庭容錯要求系統至少有3n+1個節點存在。例如,為了應對100個潛在的惡意節點,你至少需要部署301個節點。這就讓系統更復雜。Raft則只需要2n+1個節點來應對潛在的n個節點的非拜占庭故障,顯然復雜性和成本要低一些。因此有些分布式系統還是更傾向于Raft,尤其是考慮到像Hyperledger Fabric這種許可制的聯盟鏈環境中,通常會使用數字證書等安全機制來增強安全性,因此存在惡意節點的可能性很小。
Raft是一個分布式崩潰故障容錯共識算法,它可以保證在系統中部分節點出現非拜占庭故障的情況下,系統依然可以處理客戶端的請求。從技術上來講,Raft是一個管理復制日志(Replicated Log)的共識算法,復制日志是復制狀態機(RSM:Replicated State Machine)的組成部分。
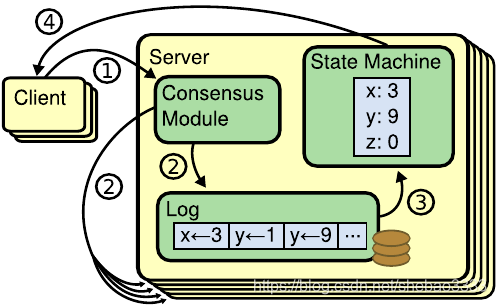
復制狀態機是用于構建分布式系統的一種比較基礎的架構。它的主要構成單元包括:包含命令序列的節點日志、共識模塊(例如Raft)和狀態機。
復制狀態機的工作原理如下:
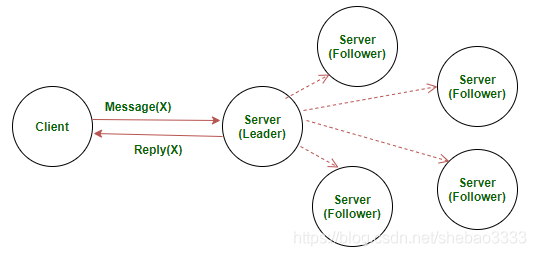
客戶端向主導節點(Leader Node)發送包含命令的請求
主導節點將收到的請求追加到其日志中,并將該請求發送給所有的 跟隨節點(Follower Node)。跟隨節點也會將該請求追加到自身的日志中 并返回一個確認消息
一旦主導節點收到大部分跟隨節點的確認消息,就會將命令日志提交給其管理的狀態機。一旦主導節點提交了日志,跟隨節點也會將日志提交給自身管理的狀態機
主導節點向客戶端返回響應結果
那么,Raft在復制狀態機架構中扮演什么角色?
Raft的作用是確保跟隨節點的日志與主導節點的日志保持一致(即:日志復制),這樣整個分布式系統的行為看起來是一致的,即使部分節點出現故障也沒有影響。
另一個問題,客戶端是否需要了解哪個是主導節點?
答案是NO,客戶端可以向任何一個節點發送請求,如果該節點是主導節點,那么它會直接處理請求,否則的話,該節點會轉發請求給主導節點。
對于Raft算法而言,每個節點只能處于三個狀態之一:
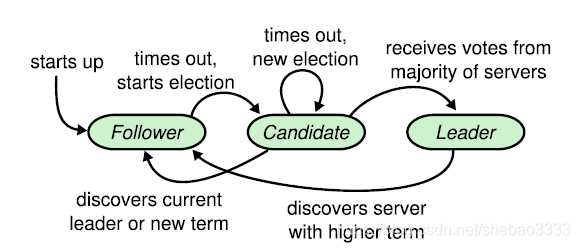
跟隨狀態:初始情況下,所有的節點都處于跟隨狀態,也就是都是跟隨節點。一旦某個跟隨節點沒有正常通信,它就轉換為候選狀態(Candidate),也就是成為一個候選節點。跟隨節點的日志可以被主導節點重寫。
候選狀態:處于候選狀態的節點會發起選舉,如果它收到集群中大多數成員的投票認可,就轉換為主導狀態。
主導狀態:處理客戶端請求并確保所有的跟隨節點具有相同的日志副本。主導節點不可以重寫其自身的日志。
如果候選節點發現已經選出了主導節點,它就會退回到跟隨狀態。同樣,如果主導節點發現另一個主導節點的任期(Term)值更高,它也會退回到跟隨狀態。
任期(Term)是一個單調遞增的整數值,用來標識主導節點的管理周期。每個任期都從選舉開始,直到下一個任期之前。
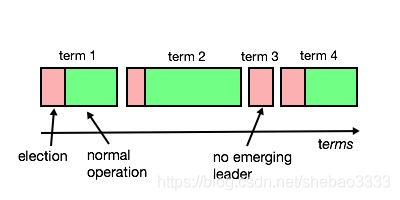
Raft使用心跳機制來出發主導節點的選舉。當節點啟動后進入跟隨狀態,只要它能從主導節點或候選節點收到有效的RPC心跳消息,就會保持在跟隨狀態。主導節點會周期性發送心跳消息(沒有日志項的AppendEntries RPC消息)給所有的跟隨節點來維持其主導地位。如果某個跟隨節點在一段時間內沒有收到心跳消息,就發生選舉超時事件,該節點就認為目前沒有主導節點并發起選舉來選出新的主導節點。
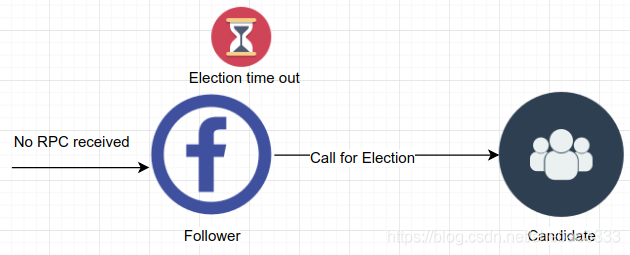
要開始一個選舉,跟隨節點會遞增其當前任期值并轉換到候選狀態。該節點首先給自己投一票,然后同時向其他節點發送請求投票的消息(RequestVote RPC消息)。
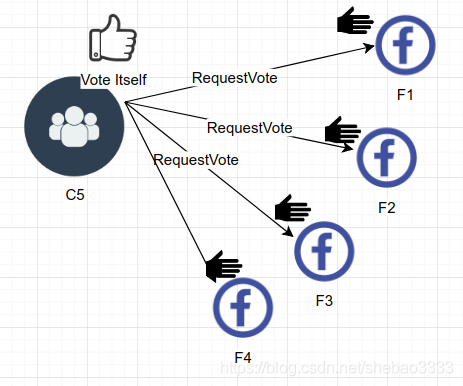
候選節點會保持在候選狀態,直到以下事件發生:
該節點勝出選舉
其他節點勝出選舉
沒有節點勝出選舉
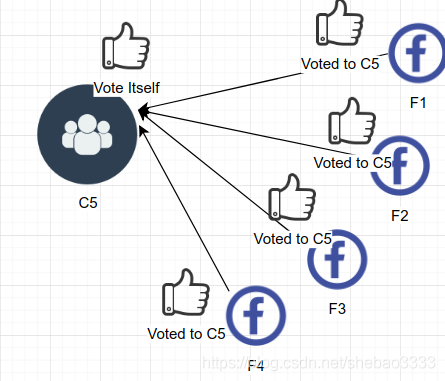
如果該節點收到大部分節點的投票認可,就可以勝出選舉,那么該節點就轉換到主導狀態成為新的主導節點。注意:每個節點只能投一票。
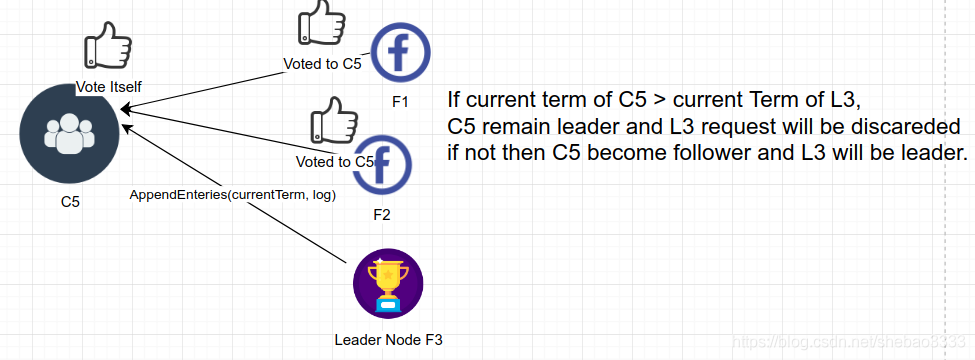
如果同時也有其他節點宣布自己是主導節點并有更高的任期值,那么任期值高的節點成為新的主導節點:
如果多個候選節點的得票情況相同,那么沒有勝出節點。
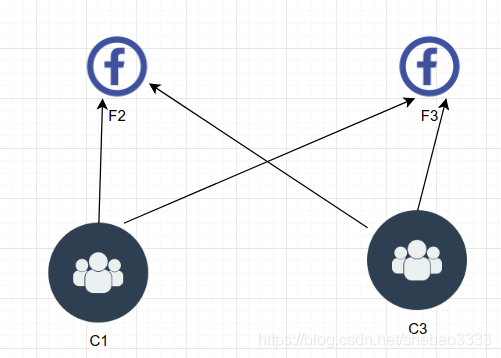
要避免出現這種情況,可以重新初始化選舉并確保每個節點的選舉超時時長是隨機的,以避免跟隨節點同時進入候選狀態。
一旦選出主導節點,它就開始處理客戶端的請求。請求中包含有復制狀態機需要執行的命令。主導節點將命令追加到自己的日志中,然后并行發送AppendEntriesRPC消息給所有跟隨節點復制這個新的日志項。當新的日志項被安全復制后,主導節點會在自身的狀態機上執行這個日志項里的命令,并將結果返回給客戶端。
如果跟隨節點崩潰、運行緩慢或網絡發生丟包問題,主導節點會無限重試發送AppendEntries RPC消息(即使它已經向客戶端返回了響應結果),直到所有的跟隨節點最終得到一致的日志副本。
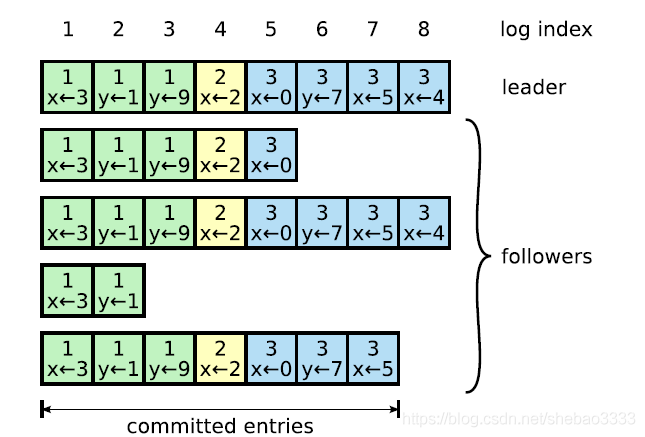
當發送AppendEntries RPC消息時,主導節點會同時發送新日志項的前序日志項的序號和任期值。如果跟隨節點在自身日志中沒有發現相同的序號和任期值,就會拒絕新的日志項。因此如果pendEntries成功返回,主導節點就知道跟隨節點的日志與自己是完全一致的。
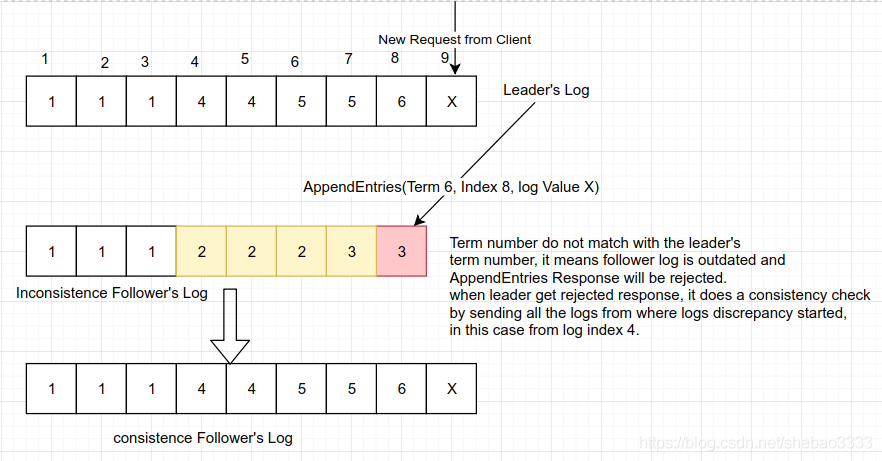
當出現不一致情況時,主導節點強制跟隨節點復制自己的日志。
基于Raft的排序服務替代了之前的Kafka排序服務。每個排序節點都有其自己的Raft復制狀態機來提交日志。客戶端利用Broadcast RPC發送交易提議。Raft排序節點基于共識生成新的區塊,當對等節點發送Deliver RPC時,將區塊發送給對等節點。
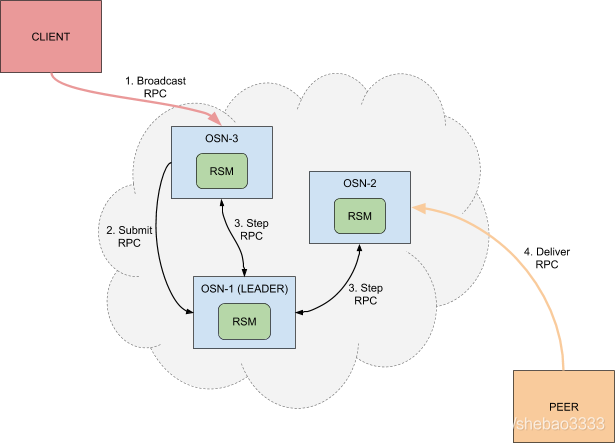
Raft排序節點的工作流程如下:
交易(例如提議、配置更新)應當自動路由到通道的當前主導節點
主導節點檢查交易驗證的配置序列號是否與當前配置序列號一致,如果不一致的 話則執行驗證,并在驗證失敗后駁回交易。通過驗證后,主導節點將收到的交易傳入區塊切割模塊的Ordered方法,創建候選區塊
如果產生了新的區塊,主導排序節點將其應用于本地的Raft有限狀態機(FSM)
有限狀態機將嘗試復制到足夠數量的排序節點,以便提交區塊
區塊被寫入接收節點的本地賬本
每個通道都會運行Raft協議的單獨實例。換句話說,有N個通道的網絡,就有N個Raft集群,每個Raft集群都有自己的主導排序節點。
我們使用BYFN組件展示raft共識模塊的使用方法。BYFN包含5個排序節點,2個組織4個對等節點,以及可選的CouchDB。在configtx.yaml文件中給出了Raft排序服務的配置。
用下面的腳本命令啟動默認的go鏈碼和raft共識,該腳本會自動生成必要的密碼學數據:
cd fabric-samples/first-network ./byfn.sh up -o etcdraft
查看排序服務:
docker logs -f ordrer3.example.com

現在我們驗證Raft的容錯能力。
首先停掉Node3:
docker stop orderer3.example.com

然后停掉Node5:
docker stop orderer5.example.com
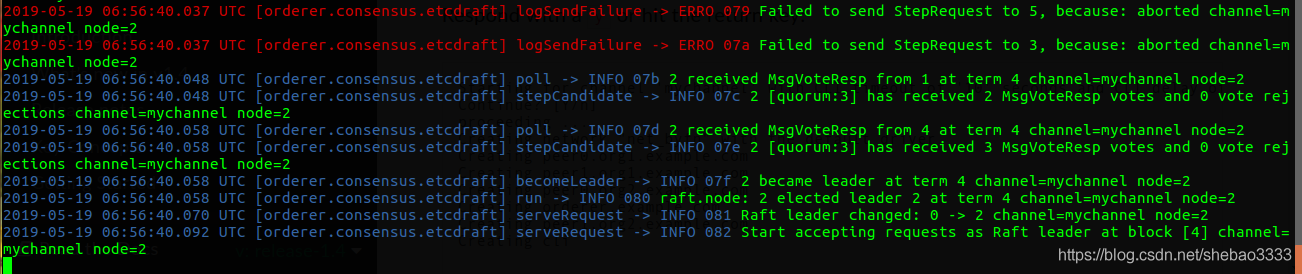
現在驗證系統的有效性,可以看到系統依然可以正常響應客戶端的請求:


以上是“hyperledger fabric中Raft共識插件的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





