溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“WebMagic爬蟲知識點有哪些”,在日常操作中,相信很多人在WebMagic爬蟲知識點有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”WebMagic爬蟲知識點有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
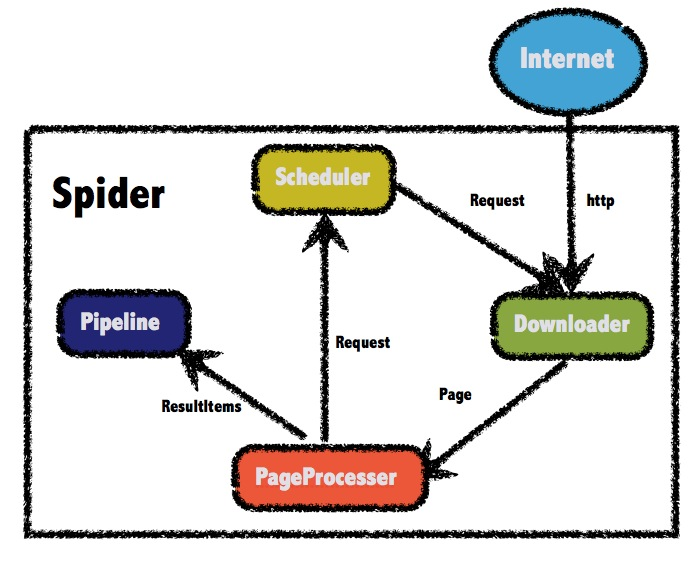
WebMagic的四個組件 1.Downloader Downloader負責從互聯網上下載頁面,以便后續處理。WebMagic默認使用了Apache HttpClient作為下載工具。
2.PageProcessor PageProcessor負責解析頁面,抽取有用信息,以及發現新的鏈接。WebMagic使用Jsoup作為HTML解析工具,并基于其開發了解析XPath的工具Xsoup。
在這四個組件中,PageProcessor對于每個站點每個頁面都不一樣,是需要使用者定制的部分。
3.Scheduler Scheduler負責管理待抓取的URL,以及一些去重的工作。WebMagic默認提供了JDK的內存隊列來管理URL,并用集合來進行去重。也支持使用Redis進行分布式管理。
除非項目有一些特殊的分布式需求,否則無需自己定制Scheduler。
4.Pipeline Pipeline負責抽取結果的處理,包括計算、持久化到文件、數據庫等。WebMagic默認提供了“輸出到控制臺”和“保存到文件”兩種結果處理方案。
Pipeline定義了結果保存的方式,如果你要保存到指定數據庫,則需要編寫對應的Pipeline。對于一類需求一般只需編寫一個Pipeline。
爬的是虎嗅的文章
<!-- webmagic 網絡爬蟲jar --> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.7.3</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version> </dependency>
package com.jinguanjia.app.exercise.spider;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.proxy.Proxy;
import us.codecraft.webmagic.proxy.SimpleProxyProvider;
/**
* @author fengpuchao
* @date 2019年7月1日
*/
public class Main {
public static void main(String[] args){
SimpleHttpClientDownloader httpClientDownloader = new SimpleHttpClientDownloader();
httpClientDownloader.setProxyProvider(
SimpleProxyProvider.from(new Proxy("101.101.101.101", 8888), new Proxy("102.102.102.102", 8888)));
//設置處理器
Spider.create(new HuXiuPageProcessor())
//設置其實url
.addUrl("https://www.huxiu.com")
//處理數據的pipeline
.addPipeline(new DataHandlerPipeline())
//下載器 設置代理
// .setDownloader(httpClientDownloader)
//調度用的,可以處理url
// .setScheduler(scheduler)
// 設置線程數
.thread(5)
.run();
}
}package com.jinguanjia.app.exercise.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.downloader.HttpClientDownloader;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.proxy.Proxy;
import us.codecraft.webmagic.proxy.SimpleProxyProvider;
/**
* @author fengpuchao
* @date 2019年7月1日
*/
public class HuXiuPageProcessor implements PageProcessor {
/**
* 設置抓取網站的相關配置
* 重試3次
* 1s中抓取一次
*/
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
@Override
public Site getSite() {
return site;
}
@Override
public void process(Page page) {
/**
* page.getHtml() 提供了很多方法讀取內容
*/
page.addTargetRequests(page.getHtml().links().regex("(https://www.huxiu.com/article/[\\[0-9]+.html)").all());
page.putField("title", page.getHtml().css("div.wrap-left.pull-left > div.article-wrap > h2","text"));
if(page.getResultItems().get("title") == null){
page.setSkip(true);
}
page.putField("portal", page.getHtml().css("div.wrap-left.pull-left > div.article-wrap > div.article-img-box > img","src"));
page.putField("createTime", page.getHtml().css("div.wrap-left.pull-left > div.article-wrap > div.article-author > div > span.article-time.pull-left","text"));
// page.putField("content", page.getHtml().css("div.article-section-wrap > div.article-section > div.container > div.wrap-left> div.article-wrap > div.article-content-wrap","tidyText"));
page.putField("content", page.getHtml().xpath("//*[@class='article-content-wrap']//tidyText()"));
page.putField("images", page.getHtml().css("img","src").all());
}
}package com.jinguanjia.app.exercise.spider;
import java.util.List;
import org.apache.commons.collections.CollectionUtils;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
/**
* @author fengpuchao
* @date 2019年7月1日
*/
public class DataHandlerPipeline implements Pipeline {
private int count = 0;
@Override
public void process(ResultItems item, Task task) {
try{
System.out.println("文章標題:" + item.get("title"));
System.out.println("文章portal:" + item.get("portal"));
System.out.println("文章創建時間:" + item.get("createTime"));
// System.out.println("文章內容:" + item.get("content"));
System.out.println("第幾篇文章:" + count ++ );
List<String> images = (List)item.get("images");
if(!CollectionUtils.isEmpty(images)){
for(String str:images){
ImageDownloader.download(str, System.currentTimeMillis()+ ".jpg", "D://images");
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}package com.jinguanjia.app.exercise.spider;
import us.codecraft.webmagic.downloader.HttpClientDownloader;
/**
* @author fengpuchao
* @date 2019年7月1日
*/
public class SimpleHttpClientDownloader extends HttpClientDownloader {
}package com.jinguanjia.app.exercise.spider;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.net.URLConnection;
import com.alibaba.druid.util.StringUtils;
/**
* @author fengpuchao
* @date 2019年7月2日
*/
public class ImageDownloader {
public static void download(String netUrl, String filename, String savePath) throws Exception {
if (StringUtils.isEmpty(netUrl) || StringUtils.isEmpty(filename) || StringUtils.isEmpty(savePath)) {
return;
}
URL url = new URL(netUrl);
URLConnection con = url.openConnection();
con.setConnectTimeout(5 * 1000);
try {
InputStream is = con.getInputStream();
// 1K的數據緩沖
byte[] bs = new byte[1024];
// 讀取到的數據長度
int len;
// 輸出的文件流
File sf = new File(savePath);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + filename);
try {
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (os != null) {
os.close();
}
if (is != null) {
is.close();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}在開始爬取之前,您必須創建一個新的Scrapy項目。 進入您打算存儲代碼的目錄中,運行下列命令:
scrapy startproject my_spider
該命令將會創建包含下列內容的 tutorial 目錄:
my_spider/ scrapy.cfg my_spider/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
這些文件分別是:
scrapy.cfg: 項目的配置文件
my_spider/: 該項目的python模塊。之后您將在此加入代碼。
my_spider/items.py: 項目中的item文件.
my_spider/pipelines.py: 項目中的pipelines文件.
my_spider/settings.py: 項目的設置文件.
my_spider/spiders/: 放置spider代碼的目錄.
Item 是保存爬取到的數據的容器;其使用方法和python字典類似, 并且提供了額外保護機制來避免拼寫錯誤導致的未定義字段錯誤。
類似在ORM中做的一樣,您可以通過創建一個 scrapy.Item 類, 并且定義類型為 scrapy.Field 的類屬性來定義一個Item。 (如果不了解ORM, 不用擔心,您會發現這個步驟非常簡單)
首先根據需要從dmoz.org獲取到的數據對item進行建模。 我們需要從dmoz中獲取名字,url,以及網站的描述。 對此,在item中定義相應的字段。編輯 tutorial 目錄中的 items.py 文件:
import scrapy class MySpiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() name = scrapy.Field() title = scrapy.Field() info = scrapy.Field()
一開始這看起來可能有點復雜,但是通過定義item, 您可以很方便的使用Scrapy的其他方法。而這些方法需要知道您的item的定義。
在 spiders 目錄下創建文件MainSpider.py ,代碼內容如下:
# -*- coding: utf-8 -*-
import scrapy
from my_spider.items import MySpiderItem
class MainSpider(scrapy.Spider):
# 用于區分別的Spider,名字必須唯一
name = "itcast"
# 允許搜索的域名范圍
allowed_domains = ['itcast.com']
# 啟動初始爬取的url
start_urls = {
"http://www.itcast.cn/channel/teacher.shtml",
}
# 是spider的一個方法。 被調用時,每個初始URL完成下載后生成的 Response 對象將會作為唯一的參數傳遞給該函數。 該方法負責解析返回的數據(response data),提取數據(生成item)以及生成需要進一步處理的URL的 Request 對象
def parse(self,response):
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 將我們得到的數據封裝到一個 `ItcastItem` 對象
item = MySpiderItem()
# extract()方法返回的都是unicode字符串
name = each.xpath("h4/text()").extract()
title = each.xpath("h5/text()").extract()
info = each.xpath("p/text()").extract()
# xpath返回的是包含一個元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后數據
return itemssettings.py文件設置utf-8編碼
ROBOTSTXT_OBEY = False
在 my_spider目錄下運行爬蟲,輸出到 teachers.json 文件中
scrapy crawl itcast -o teachers.json
到此,關于“WebMagic爬蟲知識點有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





