溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
spring中怎么使用責任連模式,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
1. 外部控制模式
??對于外部控制的方式,這種方式比較簡單,鏈的每個節點只需要專注于各自的邏輯即可,而當前節點調用完成之后是否繼續調用下一個節點,這個則由外部控制邏輯決定。這里我們以一個過濾器的實現邏輯進行講解,在平常工作中,我們經常需要根據一系列的條件對某個東西進行過濾,比如任務服務的設計,在執行某個任務,其需要經過諸如時效性的檢驗,風控攔截,任務完成次數等的過濾條件的檢驗之后才能判斷當前任務是否能夠執行,只有在所有的過濾條件都完成之后,我們才能執行該任務。那么,這里我們可以抽象出一個Filter接口,設計如下:
public interface Filter {
/**
* 用于對各個任務節點進行過濾
*/
boolean filter(Task task);
}??這里的Filter.filter方法只有一個參數Task,主要就是控制當天task是否需要過濾掉,其中有個boolean類型的返回值,通過該返回值告知外部控制邏輯是否需要將該task過濾掉。對于該接口的子類,我們只需要將其聲明為spring所管理的一個bean即可:
@Component
public class DurationFilter implements Filter {
@Override
public boolean filter(Task task) {
System.out.println("時效性檢驗");
return true;
}
}@compoment
public class Risk implements Filter {
@override
public boolean filter(Task task){
System.out.println("風控攔截");
return true;
}
}@Component
public class TimesFilter implements Filter {
@Override
public boolean filter(Task task) {
System.out.println("次數限制檢驗");
return true;
}
}??上面我們模擬聲明了3個Filter的子類,用于設計一系列的控制當天task是否需要被過濾的邏輯,結構上的邏輯其實比較簡單,主要就是需要將其聲明為spring所管理的一個bean。下面是我們的控制邏輯:
@Service
public class ApplicationService {
@Autowired
private List<Filter> filters;
public void mockedClient() {
Task task = new Task(); // 這里task一般是通過數據庫查詢得到的
for (Filter filter : filters) {
if (!filter.filter(task)) {
return;
}
}
// 過濾完成,后續是執行任務的邏輯
}
}??上述的控制邏輯中,對于過濾器的獲取,只需要通過spring的自動注入即可,這里的注入是一個List<Filter>,就是說,如果我們有新的Filter實例需要參與責任鏈的過濾,只需要聲明為一個Spring容器所管理的bean即可。
??這種責任鏈設計方式的優點在于鏈的控制簡單,只需要實現一個統一的接口即可,基本上滿足大部分的邏輯控制,但是對于某些動態調整鏈的需求就無能為力了。比如在執行到某個節點之后需要動態的判斷師傅執行下一個節點,或者說要執行,某些分叉點的節點等。這個時候,我們就需要將鏈節點的傳遞工作交個各個節點執行。
1. 外部控制模式
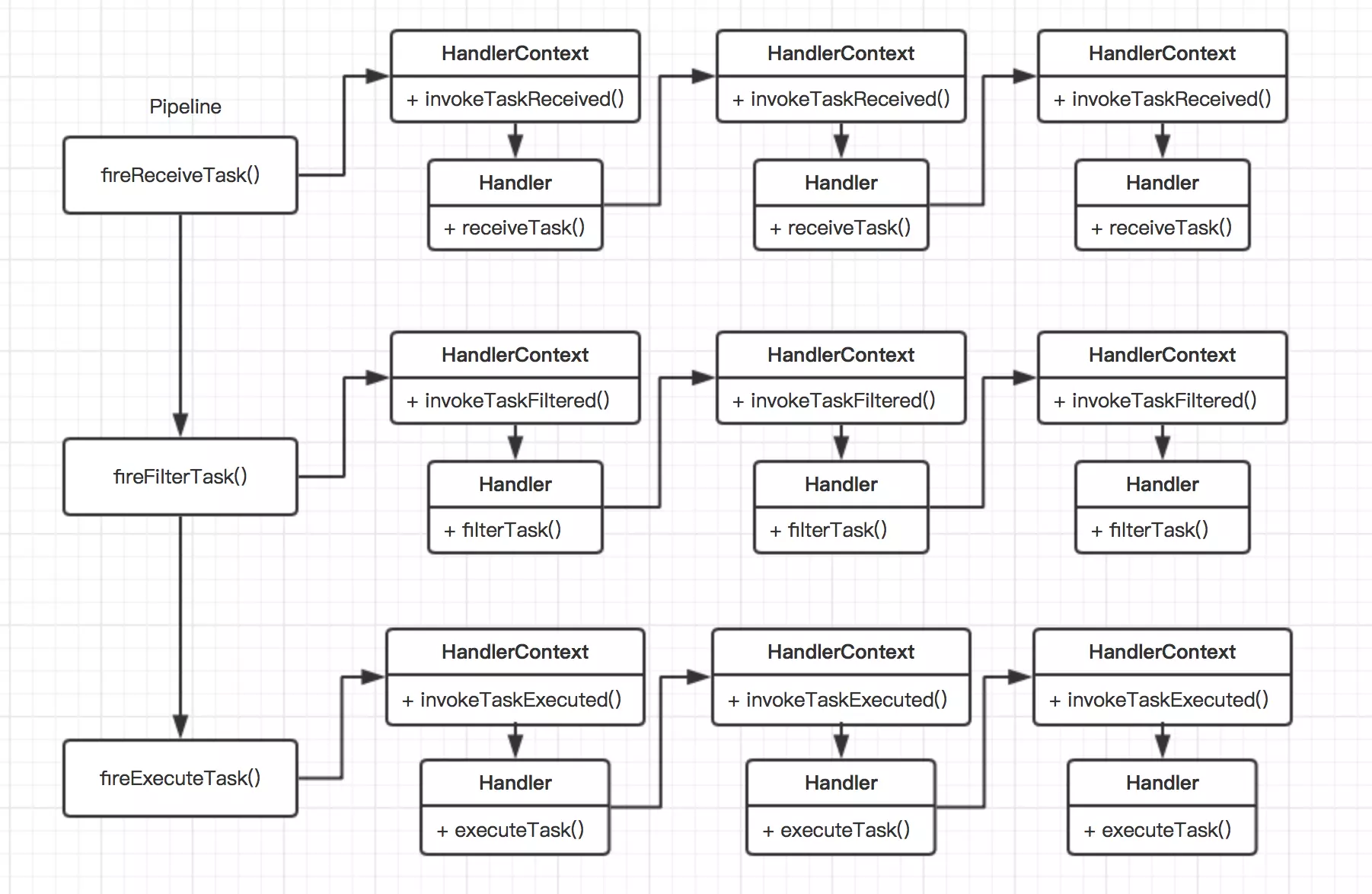
對于節點控制調用的方式,其主要有三個控制點:Handler,HandlerContext和PipeLine。Handle是用于編寫具體的業務代碼,HandlerContext用于對Handler進行包裹,并且用于控制下一個節點的調用;PipeLine則主要是用于控制整體的流程調用的,比如對于任務的執行,其有任務查詢,任務的過濾和執行任務等等流程,這些流程整體的邏輯控制就是有pipeline控制,在每個流程中又包含了一些列的子流程,這些子流程則是由一個個的HandlerContext和Handler進行梳理的,這種責任鏈的控制方式整體邏輯如下圖所示:
 ![]
![]
從上圖可以看出,我們整個流程通過pipeline對象進行了抽象,這里主要分為了3個步驟:查詢task,過濾task和執行task。在每個步驟中,我們都是用一系列的鏈式調用。途中需要注意的是,在每次調用鏈的下一個節點的時候,我們都是通過具體的Handler進行的,也就是說進行鏈的下一個節點的調用,我們是通過業務實現方來進行動態的控制。
關于該模式的設計,我們首先需要強調的就是Handler接口的設計,其設計如下所示:
public interface Handler {
/**
* 處理接收到前端請求的邏輯
*/
default void receiveTask(HandlerContext ctx, Request request) {
ctx.fireTaskReceived(request);
}
/**
* 查詢到task之后,進行task過濾的邏輯
*/
default void filterTask(HandlerContext ctx, Task task) {
ctx.fireTaskFiltered(task);
}
/**
* task過濾完成之后,處理執行task的邏輯
*/
default void executeTask(HandlerContext ctx, Task task) {
ctx.fireTaskExecuted(task);
}
/**
* 當實現的前面的方法拋出異常時,將使用當前方法進行異常處理,這樣可以將每個handler的異常
* 都只在該handler內進行處理,而無需額外進行捕獲
*/
default void exceptionCaught(HandlerContext ctx, Throwable e) {
throw new RuntimeException(e);
}
/**
* 在整個流程中,保證最后一定會執行的代碼,主要是用于一些清理工作
*/
default void afterCompletion(HandlerContext ctx) {
ctx.fireAfterCompletion(ctx);
}
}這里的Handler接口主要是對具體的業務邏輯的一個抽象,對于該Handler主要有如下幾點需要說明:
在前面圖中pipline的每個層級中對應于改Handler都有一個方法,在需要進行具體的業務處理的時候,用戶只需要聲明一個bean,具體實現某個業務所需要處理的層級的方法即可,無需管其他的邏輯;
每個層級的方法都有默認的實現,默認實現方式就是將鏈的調用繼續往下進行傳遞
每個層級的方法中,第一個參數都是一個Handler類型的,該參數主要是用于進行流程控制的,比如是否需要將當前層級的調用鏈繼續往下傳遞,這里的鏈的傳遞工作主要是通過ctx.filterXXX()方法進行
每個Handler中都有一個exceptionCaught()和afterCompletion()方法,這兩個方法分別用于異常的控制和所有調用完成之后的清理,這里的異常控制主要是捕獲當前Handler中的異常,而afterCompetition()方法則會保證所有步驟之后一定會進行調用的,五路是否拋出異常;
對于Handler的使用,我們希望能夠達到的目的是,使用方只需要實現該接口,并且使用某個注解來將其標志位spring bean即可,無需管整個pipeline的組裝和流程控制。通過這種方式,我們既保留了每個spring提供給我們的便利性,也使用了pipeline模式的靈活性
上述流程代碼中,我們注意到,每個層級的方法中都有一個HandlerContext用于傳遞鏈的相關控制信息,我們來看下關于這部分的源碼:
@Component
@Scope("prototype")
public class HandlerContext {
HandlerContext prev;
HandlerContext next;
Handler handler;
private Task task;
public void fireTaskReceived(Request request) {
invokeTaskReceived(next(), request);
}
/**
* 處理接收到任務的事件
*/
static void invokeTaskReceived(HandlerContext ctx, Request request) {
if (ctx != null) {
try {
ctx.handler().receiveTask(ctx, request);
} catch (Throwable e) {
ctx.handler().exceptionCaught(ctx, e);
}
}
}
public void fireTaskFiltered(Task task) {
invokeTaskFiltered(next(), task);
}
/**
* 處理任務過濾事件
*/
static void invokeTaskFiltered(HandlerContext ctx, Task task) {
if (null != ctx) {
try {
ctx.handler().filterTask(ctx, task);
} catch (Throwable e) {
ctx.handler().exceptionCaught(ctx, e);
}
}
}
public void fireTaskExecuted(Task task) {
invokeTaskExecuted(next(), task);
}
/**
* 處理執行任務事件
*/
static void invokeTaskExecuted(HandlerContext ctx, Task task) {
if (null != ctx) {
try {
ctx.handler().executeTask(ctx, task);
} catch (Exception e) {
ctx.handler().exceptionCaught(ctx, e);
}
}
}
public void fireAfterCompletion(HandlerContext ctx) {
invokeAfterCompletion(next());
}
static void invokeAfterCompletion(HandlerContext ctx) {
if (null != ctx) {
ctx.handler().afterCompletion(ctx);
}
}
private HandlerContext next() {
return next;
}
private Handler handler() {
return handler;
}
}在HandlerContext中,我們需要說明幾點:
之前Handler接口默認實現的ctx.filterXXX()方法,這里都委托給了對應的invokeXXX方法進行調用,而且我們注意到,在傳遞invokeXXX()方法的參數里,傳入的HandlerContext對象都是通過next()方法獲取到的。也就是說我們在Handler中調用ctx.filterXXX方法時,都是在調用當前Handler的下一個Handler對應的層級方法,通過這種方式我們就可以實現鏈式的傳遞調用;
在上一點中我們說到,在某個Handler中如果想讓鏈往下傳遞,只需要調用FilterXXX()方法即可,如果我們在某個Handler中,根據業務,當前層級已經調用完成,而無需調用后續的Handler,那么我們就不需要調用ctx.filterXXX()方法即可;
在HandlerContext中,我們也實現了invokeXXX()方法,該方法的作用是提供給外部的pipeline調用的,開啟每個層級的鏈;
在每個invokeXXX()方法中,我們都是用try...catch將當前層級的調用拋出異常捕獲了,然后調用ctx.handler().exceptionCaught()方法即可,異常捕獲流程就是在這里的HandlerContext()中處理的;
在HandlerContext的聲明處,我們需要注意到,其使用了@conpoment和@("prototype")注解進行標注了,這說明我們的HandlerContext是有spring 容器管理的,并且由于我們每個Handler實際都由HandlerContext維護,所以這里必須聲明為prototype類型。通過這種方式,我們的HandlerContext也就具備著諸如spring相關的bean的功能,能夠根據業務需求進行一些額外的處理;
前面我們講解了Handler和HandlerContext的具體實現,以及實現的過程需要注意的一些問題,下面我們將來看進行流程控制的pipeline是如何實現的,如下是其接口的定義:
public interface Pipeline {
Pipeline fireTaskReceived();
Pipeline fireTaskFiltered();
Pipeline fireTaskExecuted();
Pipeline fireAfterCompletion();
}這里主要是定義了一個pipeline接口,該接口定義了一些列的層級調用,是每個層級的入口方法,如下是該接口的實現類:
@Component("pipeline")
@Scope("prototype")
public class DefaultPipeline implements Pipeline, ApplicationContextAware, InitializingBean {
// 創建一個默認的handler,將其注入到首尾兩個節點的HandlerContext中,其作用只是將鏈往下傳遞
private static final Handler DEFAULT_HANDLER = new Handler() {};
// 將ApplicationContext注入進來的主要原因在于,HandlerContext是prototype類型的,因而需要
// 通過ApplicationContext.getBean()方法來獲取其實例
private ApplicationContext context;
// 創建一個頭結點和尾節點,這兩個節點內部沒有做任何處理,只是默認的將每一層級的鏈往下傳遞,
// 這里頭結點和尾節點的主要作用就是用于標志整個鏈的首尾,所有的業務節點都在這兩個節點中間
private HandlerContext head;
private HandlerContext tail;
// 用于業務調用的request對象,其內部封裝了業務數據
private Request request;
// 用于執行任務的task對象
private Task task;
// 最初始的業務數據需要通過構造函數傳入,因為這是驅動整個pipeline所需要的數據,
// 一般通過外部調用方的參數進行封裝即可
public DefaultPipeline(Request request) {
this.request = request;
}
// 這里我們可以看到,每一層級的調用都是通過HandlerContext.invokeXXX(head)的方式進行的,
// 也就是說我們每一層級鏈的入口都是從頭結點開始的,當然在某些情況下,我們也需要從尾節點開始鏈
// 的調用,這個時候傳入tail即可。
@Override
public Pipeline fireTaskReceived() {
HandlerContext.invokeTaskReceived(head, request);
return this;
}
// 觸發任務過濾的鏈調用
@Override
public Pipeline fireTaskFiltered() {
HandlerContext.invokeTaskFiltered(head, task);
return this;
}
// 觸發任務執行的鏈執行
@Override
public Pipeline fireTaskExecuted() {
HandlerContext.invokeTaskExecuted(head, task);
return this;
}
// 觸發最終完成的鏈的執行
@Override
public Pipeline fireAfterCompletion() {
HandlerContext.invokeAfterCompletion(head);
return this;
}
// 用于往Pipeline中添加節點的方法,讀者朋友也可以實現其他的方法用于進行鏈的維護
void addLast(Handler handler) {
HandlerContext handlerContext = newContext(handler);
tail.prev.next = handlerContext;
handlerContext.prev = tail.prev;
handlerContext.next = tail;
tail.prev = handlerContext;
}
// 這里通過實現InitializingBean接口來達到初始化Pipeline的目的,可以看到,這里初始的時候
// 我們通過ApplicationContext實例化了兩個HandlerContext對象,然后將head.next指向tail節點,
// 將tail.prev指向head節點。也就是說,初始時,整個鏈只有頭結點和尾節點。
@Override
public void afterPropertiesSet() throws Exception {
head = newContext(DEFAULT_HANDLER);
tail = newContext(DEFAULT_HANDLER);
head.next = tail;
tail.prev = head;
}
// 使用默認的Handler初始化一個HandlerContext
private HandlerContext newContext(Handler handler) {
HandlerContext context = this.context.getBean(HandlerContext.class);
context.handler = handler;
return context;
}
// 注入ApplicationContext對象
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.context = applicationContext;
}
}關于defaultPipeline的實現,有以下幾點需要說明:
defaultpipeline 使用@compoment和@scope("prototype")注解進行了標注,當前一個注解用于將其聲明為一個spring容器所管理的bean,而后一個注解則用于表征defaultPipeline是個多例類型,很明顯的,這里的pipeLine是有狀態的。這里需要進行說明的是,'有狀態'主要是因為我們可能會根據業務情況的動態的調整整個鏈的節點情況,而且這里的request和task對象都是與具體的業務相關的,因為必須聲明為prototype類型;
上面的示例中,request對象是通過構造pipeline對象的時候傳進來的,而task對象則是在pipeline的流轉過程中生成的,這里比如通過完成filterTaskReceived()鏈的調用之后,就需要通過外部請求request得到一個task對象,從而進行后續的處理;
對于后續寫業務代碼的人而言,其只需要實現一個Handler接口即可,無需要處理鏈相關的所有邏輯,以為我們需要獲取到所有實現Handler接口的bean;
將實現了Handler接口的bean通過Handlercontext進行封裝,然后將其添加到pipeline中
這里的第一個問題好處理,因為通過ApplicationContext就可以獲取實現了某個接口的所有bean,而第二個問題我們可以通過聲明了BeanPostProcessoor接口的類來實現。如下是具體的實現代碼:
verride
public void setApplicationContext(ApplicationContext applicationContext) {
this.context = applicationContext;
}
}
關于DefaultPipeline的實現,主要有如下幾點需要說明:
DefaultPipeline使用@Component和@Scope("prototype")注解進行了標注,前一個注解用于將其聲明為一個Spring容器所管理的bean,而后一個注解則用于表征DefaultPipeline是一個多例類型的,很明顯,這里的Pipeline是有狀態的。這里需要進行說明的是,"有狀態"主要是因為我們可能會根據業務情況動態的調整個鏈的節點情況,而且這里的Request和Task對象都是與具體的業務相關的,因而必須聲明為prototype類型;
上面的示例中,Request對象是通過構造Pipeline對象的時候傳進來的,而Task對象則是在Pipeline的流轉過程中生成的,這里比如通過完成fireTaskReceived()鏈的調用之后,就需要通過外部請求Request得到一個Task對象,從而進行整個Pipeline的后續處理;
這里我們已經實現了Pipeline,HandlerContext和Handler,知道這些bean都是被Spring所管理的bean,那么我們接下來的問題主要在于如何進行整個鏈的組裝。這里的組裝方式比較簡單,其主要需要解決兩個問題:
對于后續寫業務代碼的人而言,其只需要實現一個Handler接口即可,而無需處理與鏈相關的所有邏輯,因而我們需要獲取到所有實現了Handler接口的bean;
將實現了Handler接口的bean通過HandlerContext進行封裝,然后將其添加到Pipeline中。
這里的第一個問題比較好處理,因為通過ApplicationContext就可以獲取實現了某個接口的所有bean,而第二個問題我們可以通過聲明一個實現了BeanPostProcessor接口的類來實現。如下是其實現代碼:
@Component
public class HandlerBeanProcessor implements BeanPostProcessor, ApplicationContextAware {
private ApplicationContext context;
// 該方法會在一個bean初始化完成后調用,這里主要是在Pipeline初始化完成之后獲取所有實現了
// Handler接口的bean,然后通過調用Pipeline.addLast()方法將其添加到pipeline中
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean instanceof DefaultPipeline) {
DefaultPipeline pipeline = (DefaultPipeline) bean;
Map<String, Handler> handlerMap = context.getBeansOfType(Handler.class);
handlerMap.forEach((name, handler) -> pipeline.addLast(handler));
}
return bean;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.context = applicationContext;
}
}這里我們整個鏈路的維護工作就完成,可以看到,現在基本已經實現了鏈式流程控制。這里需要說明的一點是,上面的HandlerBeanProcessor.postProcessAfterInitialization()方法的執行是在InitializingBean.afterPropertySet()方法之后執行的,也就是說這里的HandlerBeanProcessor在執行的時候,整個pipeline就是已經完成初始化的了。下面我們來看下外部客戶端如何進行這個鏈路流程的控制:
HandlerBeanProcessor在執行時,整個Pipeline是已經初始化完成了的。下面我們來看一下外部客戶端如何進行整個鏈是流程的控制:
@Service
public class ApplicationService {
@Autowired
private ApplicationContext context;
public void mockedClient() {
Request request = new Request(); // request一般是通過外部調用獲取
Pipeline pipeline = newPipeline(request);
try {
pipeline.fireTaskReceived();
pipeline.fireTaskFiltered();
pipeline.fireTaskExecuted();
} finally {
pipeline.fireAfterCompletion();
}
}
private Pipeline newPipeline(Request request) {
return context.getBean(DefaultPipeline.class, request);
}
}這里我們模擬一個客戶端的調用,首先創建了一個pipeline對象,然后依次調用各個層級的方法,并且這里我們使用try....finally結構來保證Pipeline.fireAfterCompletion()方法一定會執行。如此我們就完成了整個責任鏈路模式的構造。這里我們使用前面用到的時效性的filter來作為示例來實現一個Handler:
@Component
public class DurationHandler implements Handler {
@Override
public void filterTask(HandlerContext ctx, Task task) {
System.out.println("時效性檢驗");
ctx.fireTaskFiltered(task);
}
}關于這里具體的業務我們需要說明的有如下幾點:
改Handler必須使用@compoment注解來將其聲明為spring容器管理的bean,這樣我們前面實現的HandlerBeanProcessor 才能動態的添加到整個pipeline中;
在每個Handler中,需要根據當前的業務需要來實現具體的層級方法,比如這里是進行時效性檢驗的,就是"任務過濾"這一層級的邏輯,因為時效性檢驗通過我們才能執行這個task,因而這里需要實現的是Handler.filterTask()方法,如果我們需要實現的是執行task的邏輯,那么需要實現的是Handler.executeTask()方法; 在實現完具體的業務邏輯之后,我們可以根據當前的業務需要看是否需要將當前層級的鏈繼續往下傳遞,也就是這里的ctx.fireTaskFiltered(task);方法的調用,我們可以看前面HandlerContext.fireXXX()方法就是會獲取當前節點的下一個節點,然后進行調用。如果根據業務需要,不需要將鏈往下傳遞,那么就不需要調用ctx.fireTaskFiltered(task);
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





