溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Java光學字符的識別方式”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
開發具有一定價值的符號是人類特有的特征。對于人們來說識別這些符號和理解圖片上的文字是非常正常的事情。與計算機那樣去抓取文字不同,我們完全是基于視覺的本能去閱讀它們。
另一方面,計算機的工作需要具體的和有組織的內容。它們需要數字化的表示,而不是圖形化的。
有時候,這是不可能的。有時,我們希望自動化的完成用雙手從圖像重寫文本的任務。
針對這些任務,光學字符識別(OCR)被設計成一種允許計算機以文本形式“閱讀”圖形化內容的方法,和人類工作的方式相似。雖然這些系統相對準確,但仍然可能有相當大的偏差。即便如此,修復系統的錯誤結果也遠比手工從頭開始要更加容易和快速。
就像所有的系統一樣,本質上是相似的,光學字符識別軟件在準備好的數據集上進行訓練,這些數據集提供了足夠多的數據用來幫助學習字符間的差異。如果我們想讓結果更加準確,那么這些軟件如何學習也是非常重要的話題,不過這將是另外一篇文章的內容了。
與其重新造輪或者想出一個非常復雜(但有用)的解決方案,不如我們先坐下來看看已有的解決方案。
科技巨頭 Google 一直在開發一個 OCR 引擎 Tesseract ,它從最初誕生到現在已有數十年的歷史。它為許多語言提供了API,不過我們將專注于 Tesseract 的 Java API 。
很容易使用 Tesseract 來實現一個簡單的功能。它主要用于讀取計算機在黑白圖片上生成的文字,并且結果的準確度較好。但這不是針對真實世界的文本。
對于現實世界中,我們最好使用像谷歌 Vision 這樣的更高級的光學字符識別軟件,這將在另一篇文章中討論。
我們只需要簡單的添加一個依賴,就可以將引擎引入到我們的項目:
<dependency> <groupid>net.sourceforge.tess4j</groupid> <artifactid>tess4j</artifactid> <version>3.2.1</version> </dependency>
使用 Tesseract 毫不費力:
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("E://DataScience//tessdata");
System.out.println(tesseract.doOCR(new File("...")));我們先實例化一個 Tesseract 實例,然后為已訓練好的 LSTM (長短期記憶網絡)模型設置數據路徑。
數據可以從官方GitHub帳號處下載。
然后我們調用 doOCR() 方法,該方法接受一個文件參數并且返回一個字符串——提取的內容。
讓我們給它提供一張有著大而清晰的黑色字符的白色背景圖片:

提供這樣一張圖片會獲得完美的結果:
Optical Character Recognition in Java is made easy with the help of Tesseract'
不過這張圖片掃描起來過于簡單了。它已經被歸一化,而且有高分辨率和一致的字體。
讓我們來試試在紙上手寫一些字符并將該圖片提供給應用程序,這將會發生些什么呢:

我們可以立即看到結果的改變:
A411“, written texz: is different {mm compatar generated but有一些單詞十分準確,并且你可以很輕松的辨認出 “written text is different from computer generated” ,但是第一個和最后一個單詞差得有點多。
現在,為了讓程序使用起來更簡單,我們把它轉換成一個十分簡單的 Spring Boot 應用程序,用更加舒適的圖形化界面來展示結果。
首先,從使用Spring Initializr創建我們的項目開始。它包含spring-boot-starter-web和spring-boot-starter-thymeleaf依賴。然后我們手動導入Tesseract:
該應用程序只需要一個控制器,它將為我們提供兩個頁面的展示、處理圖片上傳和光學字符識別功能:
@Controller
public class FileUploadController {
@RequestMapping("/")
public String index() {
return "upload";
}
@RequestMapping(value = "/upload", method = RequestMethod.POST)
public RedirectView singleFileUpload(@RequestParam("file") MultipartFile file,
RedirectAttributes redirectAttributes, Model model) throws IOException, TesseractException {
byte[] bytes = file.getBytes();
Path path = Paths.get("E://simpleocr//src//main//resources//static//" + file.getOriginalFilename());
Files.write(path, bytes);
File convFile = convert(file);
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("E://DataScience//tessdata");
String text = tesseract.doOCR(convFile);
redirectAttributes.addFlashAttribute("file", file);
redirectAttributes.addFlashAttribute("text", text);
return new RedirectView("result");
}
@RequestMapping("/result")
public String result() {
return "result";
}
public static File convert(MultipartFile file) throws IOException {
File convFile = new File(file.getOriginalFilename());
convFile.createNewFile();
FileOutputStream fos = new FileOutputStream(convFile);
fos.write(file.getBytes());
fos.close();
return convFile;
}
}Tesseract 可以和Java的 File 類一起工作,但是不支持表單上傳的 MultipartFile 類。為了便于處理,我們添加了一個簡單的 convert() 方法,它將 MultipartFile 對象轉換成一個普通的 File 對象。
一旦我們利用 Tesseract 提取出了文本,我們只需將該文本和掃描的圖像一起添加到模型當中,然后附加到重定向的展示頁面 - result。
現在,讓我們定義一個包含簡單文件上傳表單的展示頁面:
<h2>Upload a file for OCR:</h2> <form method="POST" action="/upload" enctype="multipart/form-data"> <input type="file" name="file"><br><br> <input type="submit" value="Submit"> </form>
以及一個結果頁面:
<h2>Extracted Content:</h2>
<h3>><span th:text="${text}"></span></h3>
<p>From the image:</p>
<img th:src="'/' + ${file.getOriginalFilename()}" src="">運行這個應用程序將會有一個簡單的交互界面迎接我們: 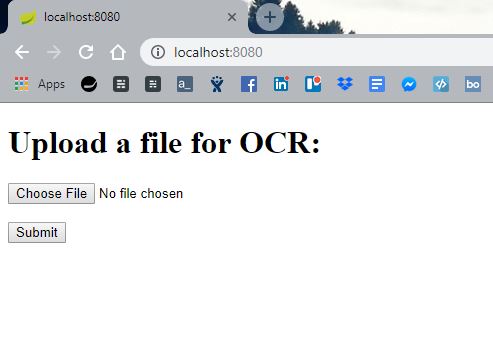
添加一個圖片并提交它,屏幕上的結果將會包含提取的文本和上傳的圖片: 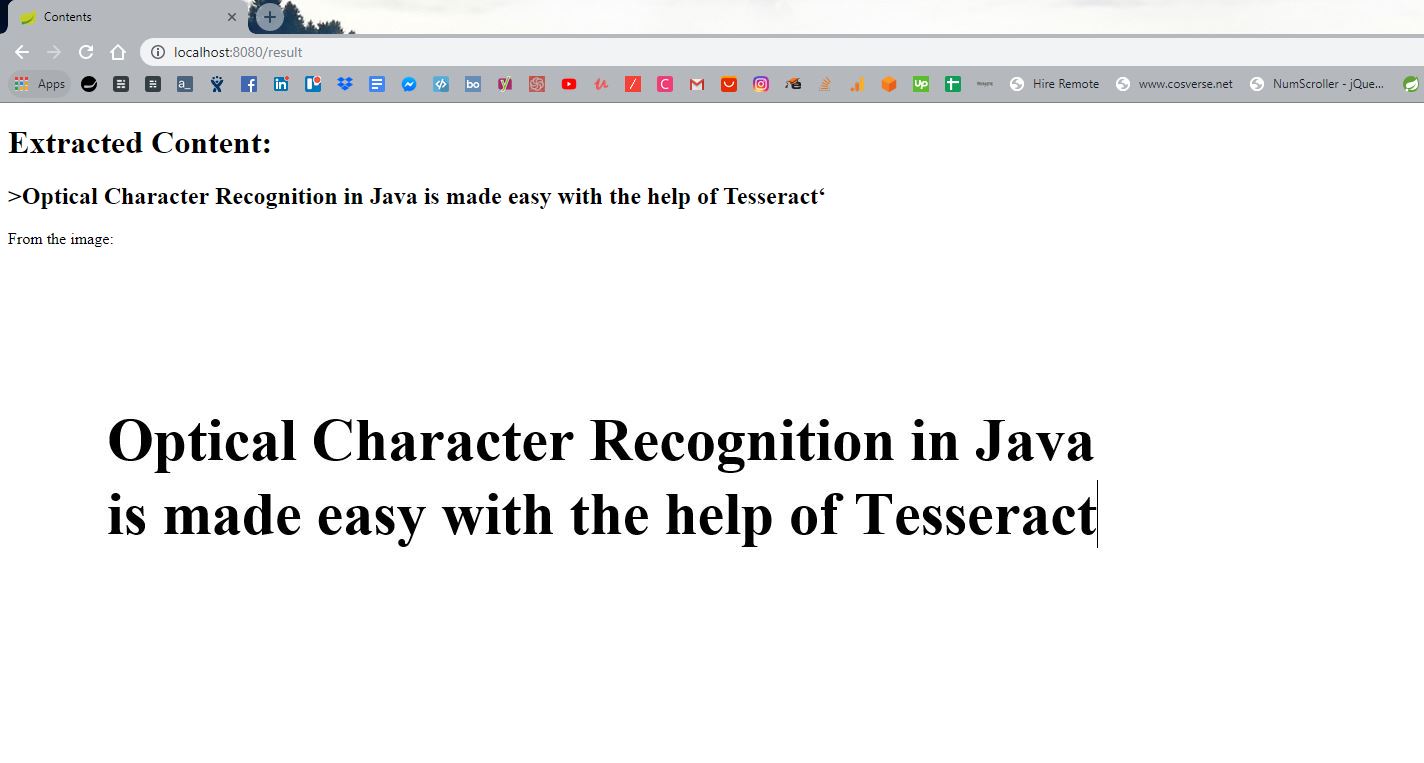
成功了!
利用谷歌的 Tesseract 引擎,我們搭建了一個十分簡單的應用,它接受從表單提交來的圖片,從中提取文本內容,最后將結果和圖片一起返回給我們。
由于我們只使用了 Tesseract 有限的功能,所以這不是一個特別有用的應用程序。而且該應用程序對于演示目的之外的任何其他用途都過于簡單,但是它可以作為一個有趣的工具來實現和測試。
“Java光學字符的識別方式”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





