溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何自定義ForkJoinPool提升并行流 ParallelStream執行速度,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
在 java8 中 添加了流Stream,可以讓你以一種聲明的方式處理數據。使用起來非常簡單優雅。ParallelStream 則是一個并行執行的流,采用 ForkJoinPool 并行執行任務,提高執行速度。<br> <br> 下面我們看看2個簡單的示例:
Arrays.asList(1,2,3,4,5,6)
.parallelStream()
.forEach((value) -> {
String name = Thread.currentThread().getName();
System.out.println("示例1 Thread:" + name + " value:" + value);
});<a name="951e1e2c"></a>
Stream.of(1,2,3,4,5,6)
.parallel()
.forEach((value) -> {
String name = Thread.currentThread().getName();
System.out.println("示例2 Thread:" + name + " value:" + value);
});筆者最近在做一些爬蟲相關的業務,其核心工具已開源 mica-http:https://gitee.com/596392912/mica/tree/master/mica-http ,經過2個版本的迭代已經發展成了一個強大非賬號爬蟲利器,趕緊來試試吧。
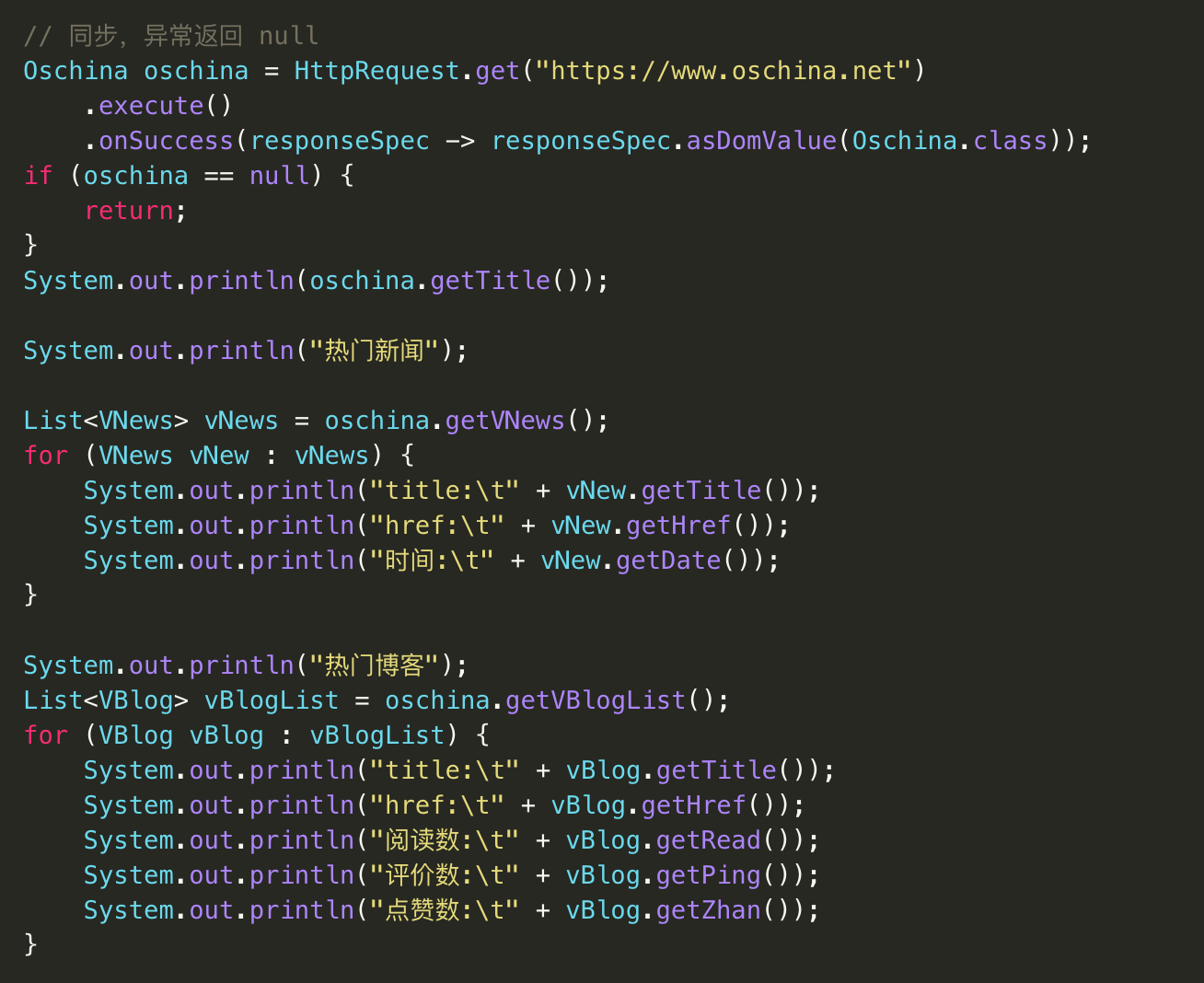

我們采集了大量的代理 ip 用來供爬蟲使用,其中有個定時任務每 5 分鐘去檢測代理是否失效,代理 ip 檢測比較費時,我們給每個檢測的請求 設定了 2s 的超時,這樣單線程的話 1000 個 ip 就得消耗半個多小時,當然筆者在校驗的時候采用的 parallel Stream 簡化開發。
然后發現效果并不明顯,代理 ip 數量上來之后 5 分鐘完全檢測不完,導致任務堆積。明明用了并發流為什么沒有明顯的提高執行速度呢?
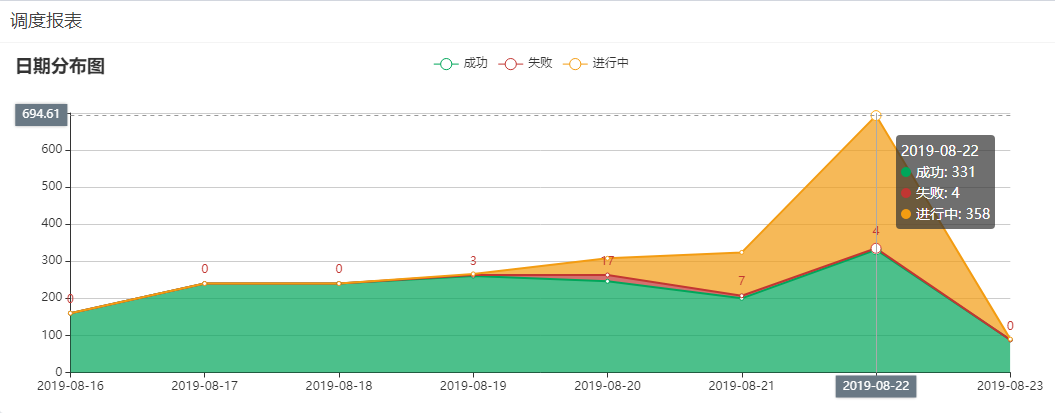
下面我們來看看剛剛的“示例”打印出的信息:
示例1 Thread:main value:4 示例1 Thread:ForkJoinPool.commonPool-worker-2 value:1 示例1 Thread:main value:6 示例1 Thread:ForkJoinPool.commonPool-worker-2 value:5 示例1 Thread:main value:3 示例1 Thread:ForkJoinPool.commonPool-worker-1 value:2 示例2 Thread:main value:4 示例2 Thread:ForkJoinPool.commonPool-worker-3 value:3 示例2 Thread:ForkJoinPool.commonPool-worker-2 value:5 示例2 Thread:ForkJoinPool.commonPool-worker-4 value:1 示例2 Thread:ForkJoinPool.commonPool-worker-5 value:2 示例2 Thread:ForkJoinPool.commonPool-worker-1 value:6
我們可以看到 Parallel Stream,默認采用的是一個 ForkJoinPool.commonPool 的線程池,這樣我們就算使用了 Parallel Stream, 整個 jvm 共用一個 common pool 線程池,一不小心就任務堆積了,在校驗代理 ip 的時候我們還有采集代理等其他的任務中也大量使用了并發流, 這樣也就印證了為什么會任務堆積了。
使用自定義 ForkJoinPool 執行速度。示例代碼如下:
// 示例:自定義線程池 ForkJoinPool forkJoinPool = new ForkJoinPool(8); // 這里是從數據庫里查出來的一批代理 ip List<proxylist> records = new ArrayList<>(); // 找出失效的代理 ip List<string> needDeleteList = forkJoinPool.submit(() -> records.parallelStream() .map(ProxyList::getIpPort) .filter(IProxyListTask::isFailed) .collect(Collectors.toList()) ).join(); // 刪除失效的代理
整個代碼依然比較優雅,在使用自定義的 ForkJoin 線程池之后,執行速度有了明顯的提升。以前 5 分鐘執行不完的任務現在 2 分鐘之內就能全部執行完畢。
java8 的并發流在大批量數據處理時可簡化多線程的使用,在遇到耗時業務或者重度使用并發流不妨根據業務情況采用自定義線程池來提示處理速度。
看完上述內容,你們對如何自定義ForkJoinPool提升并行流 ParallelStream執行速度有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





