溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
java 8已經發行好幾年了,前段時間java 12也已經問世,但平時的工作中,很多項目的環境還停留在java1.7中。而且java8的很多新特性都是革命性的,比如各種集合的優化、lambda表達式等,所以我們還是要去了解java8的魅力。
今天我們來學習java8的Stream,并不需要理論基礎,直接可以上手去用。
我接觸stream的原因,是我要搞一個用戶收入消費的數據分析。起初的統計篩選分組都是打算用sql語言直接從mysql里得到結果來展現的。但在操作中我們發現這樣頻繁地訪問數據庫,性能會受到很大的影響,分析速度會很慢。所以我們希望能通過訪問一次數據庫就拿到所有數據,然后放到內存中去進行數據分析統計過濾。
接著,我看了stream的API,發現這就是我想要的。
在java中我們稱Stream為『流』,我們經常會用流去對集合進行一些流水線的操作。stream就像工廠一樣,只需要把集合、命令還有一些參數灌輸到流水線中去,就可以加工成得出想要的結果。這樣的流水線能大大簡潔代碼,減少操作。
原集合 —> 流 —> 各種操作(過濾、分組、統計) —> 終端操作Stream流的操作流程一般都是這樣的,先將集合轉為流,然后經過各種操作,比如過濾、篩選、分組、計算。最后的終端操作,就是轉化成我們想要的數據,這個數據的形式一般還是集合,有時也會按照需求輸出count計數。下文會一一舉例。

首先,定義一個用戶對象,包含姓名、年齡、性別和籍貫四個成員變量:
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.log4j.Log4j;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Log4j
@Builder
public class User {
//姓名
private String name;
//年齡
private Integer age;
//性別
private Integer sex;
//所在省市
private String address;
}這里用lombok簡化了實體類的代碼。
然后創建需要的集合數據,也就是源數據:
//1.構建我們的list
List<User> list= Arrays.asList(
new User("鋼鐵俠",40,0,"華盛頓"),
new User("蜘蛛俠",20,0,"華盛頓"),
new User("趙麗穎",30,1,"湖北武漢市"),
new User("詹姆斯",35,0,"洛杉磯"),
new User("李世民",60,0,"山西省太原市"),
new User("蔡徐坤",20,1,"陜西西安市"),
new User("葫蘆娃的爺爺",70,0,"山西省太原市")
);
比如要過濾年齡在40歲以上的用戶,就可以這樣寫:
List<User> filterList = list.stream().filter(user -> user.getAge() >= 40)
.collect(toList());filter里面,->箭頭后面跟著的是一個boolean值,可以寫任何的過濾條件,就相當于sql中where后面的東西,換句話說,能用sql實現的功能這里都可以實現
打印結果:

和sql中的distinct關鍵字很相似。為了看到效果,此處在原集合中加入一個重復的人,就選擇鋼鐵俠吧,復聯4鋼鐵俠不幸遇害,大家還是比較傷心的。
List<User> list= Arrays.asList(
new User("鋼鐵俠",40,0,"華盛頓"),
new User("鋼鐵俠",40,0,"華盛頓"),
new User("蜘蛛俠",20,0,"華盛頓"),
new User("趙麗穎",30,1,"湖北武漢市"),
new User("詹姆斯",35,0,"洛杉磯"),
new User("李世民",60,0,"山西省太原市"),
new User("蔡徐坤”,18,1,"陜西西安市"),
new User("葫蘆娃的爺爺",70,0,"山西省太原市")
);//distinct 去重
List<User> distinctList = filterList.stream().distinct()
.collect(toList());打印結果:

如果流中的元素的類實現了 Comparable 接口,即有自己的排序規則,那么可以直接調用 sorted() 方法對元素進行排序,如:
Comparator.comparingInt反之, 需要調用 sorted((T, T) -> int) 實現 Comparator 接口。
//sorted()
List<User> sortedList = distinctList.stream().sorted(Comparator.comparingInt(User::getAge))
.collect(toList());打印結果:

結果按照年齡從小到大進行排序。
如果想知道這里面年齡最小的是誰,可作如下操作:
//limit 返回前n個元素
List<User> limitList = sortedList.stream().limit(1)
.collect(toList());
與limit恰恰相反,skip的意思是跳過,也就是去除前n個元素。
打印結果:

果然,前兩個人都被去除了,只剩下最老的葫蘆娃爺爺。
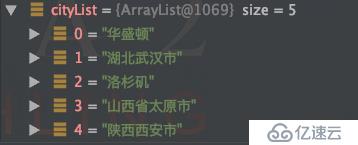
map是將T類型的數據轉為R類型的數據,比如我們想要設置一個新的list,存儲用戶所有的城市信息。
//map(T->R)
List<String> cityList = list.stream().map(User::getAddress).distinct().collect(toList());打印結果:
將流中的每一個元素 T 映射為一個流,再把每一個流連接成為一個流。
//flatMap(T -> Stream<R>)
List<String> flatList = new ArrayList<>();
flatList.add("唱,跳");
flatList.add("rape,籃球,music");
flatList = flatList.stream().map(s -> s.split(",")).flatMap(Arrays::stream).collect(toList());打印結果:

這里原集合中的數據由逗號分割,使用split進行拆分后,得到的是Stream<String[]>,字符串數組組成的流,要使用flatMap的
Arrays::stream
將Stream<String[]>轉為Stream<String>,然后把流相連接,組成了完整的唱、跳、rap、籃球和music。
檢測是否全部滿足參數行為,假如這些用戶是網吧上網的用戶名單,那就需要檢查是不是每個人都年滿18周歲了。
boolean isAdult = list.stream().allMatch(user -> user.getAge() >= 18);打印結果:
true檢測是否有任意元素滿足給定的條件,比如,想知道同學名單里是否有女生。
//anyMatch(T -> boolean) 是否有任意一個元素滿足給定的條件
boolean isGirl = list.stream().anyMatch(user -> user.getSex() == 1);打印結果:
true說明集合中有女生存在。
流中是否有元素匹配給定的 T -> boolean 條件。
比如檢測有沒有來自巴黎的用戶。
boolean isLSJ = list.stream().noneMatch(user -> user.getAddress().contains("巴黎"));打印結果:
true打印true說明沒有巴黎的用戶。
Optional<User> fristUser = list.stream().findFirst();打印結果:
User(name=鋼鐵俠, age=40, sex=0, address=華盛頓)Optional<User> anyUser = list.stream().findAny();打印結果:
User(name=鋼鐵俠, age=40, sex=0, address=華盛頓)這里我們發現findAny返回的也總是第一個元素,那么為什么還要進行區分呢?因為在并行流 parallelStream() 中找到的確實是任意一個元素。
Optional<User> anyParallelUser = list.parallelStream().findAny();打印結果 :
Optional[User(name=李世民, age=60, sex=0, address=山西省太原市)]long count = list.stream().collect(Collectors.counting());我們可以簡寫為:
long count = list.stream().count();運行結果:
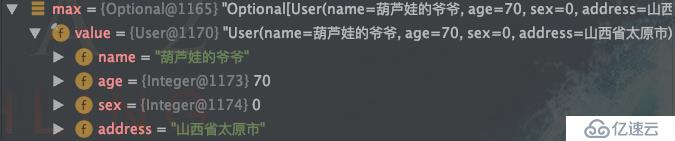
8// 求最大年齡
Optional<User> max = list.stream().collect(Collectors.maxBy(
Comparator.comparing(User::getAge)));
// 求最小年齡
Optional<User> min = list.stream().collect(Collectors.minBy(
Comparator.comparing(User::getAge)));運行結果:

// 求年齡總和
int totalAge = list.stream().collect(Collectors.summingInt(User::getAge));運行結果:
313我們經常會用BigDecimal來記錄金錢,假設想得到BigDecimal的總和:
// 獲得列表對象金額, 使用reduce聚合函數,實現累加器
BigDecimal sum = myList.stream() .map(User::getMoney)
.reduce(BigDecimal.ZERO,BigDecimal::add);//求年齡平均值
double avgAge = list.stream().collect(
Collectors.averagingInt(User::getAge));運行結果:
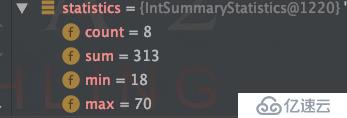
39.125IntSummaryStatistics statistics = list.stream().collect(
Collectors.summarizingInt(User::getAge));運行結果:
要將用戶的姓名連成一個字符串并用逗號分割。
String names = list.stream().map(User::getName)
.collect(Collectors.joining(", "));運行結果:
鋼鐵俠, 鋼鐵俠, 蜘蛛俠, 趙麗穎, 詹姆斯, 李世民, 蔡徐坤, 葫蘆娃的爺爺在數據庫操作中,我們經常通過GROUP BY關鍵字對查詢到的數據進行分組,java8的流式處理也提供了分組的功能。使用Collectors.groupingBy來進行分組。
Map<String, List<User>> cityMap = list.stream()
.collect(Collectors.groupingBy(User::getAddress));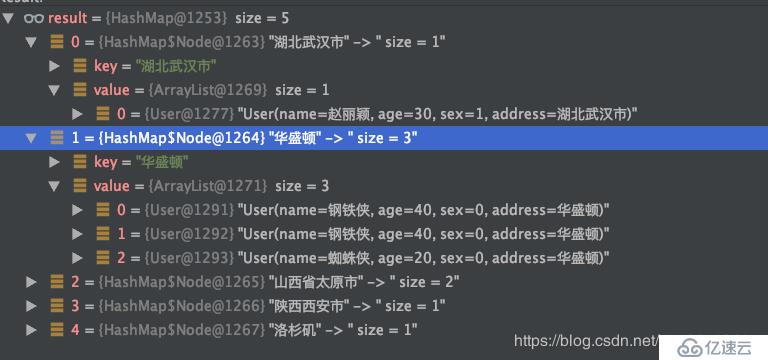
結果是一個map,key為不重復的城市名,value為屬于該城市的用戶列表。已經實現了分組。
Map<String, Map<Integer, List<User>>> group = list.stream().collect(
Collectors.groupingBy(User::getAddress, // 一級分組,按所在地區
Collectors.groupingBy(User::getSex))); // 二級分組,按性別運行結果:
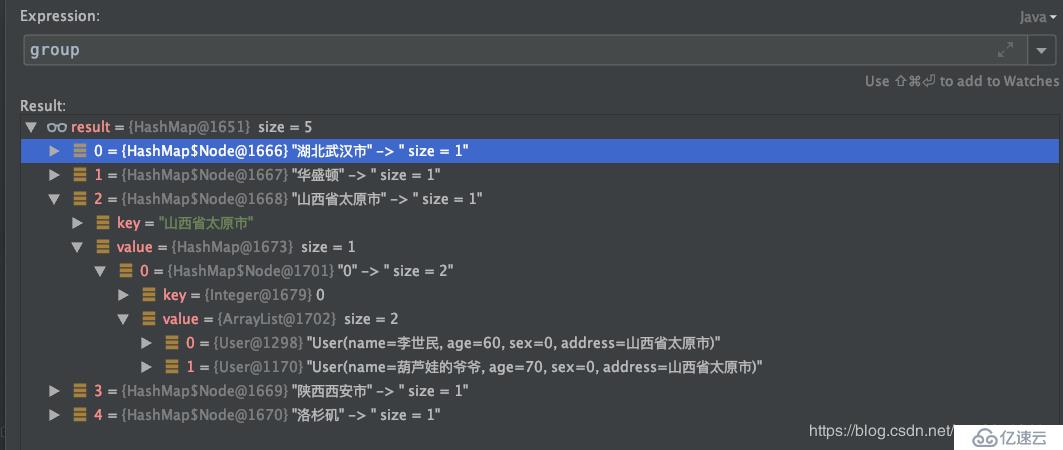
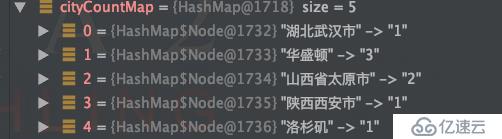
按城市分組并統計人數:
Map<String, Long> cityCountMap = list.stream()
.collect(Collectors.groupingBy(User::getAddress,Collectors.counting()));運行結果:
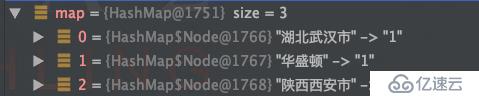
Map<String,Long> map = list.stream().filter(user -> user.getAge() <= 30)
.collect(Collectors.groupingBy(User::getAddress,Collectors.counting()));運行結果:
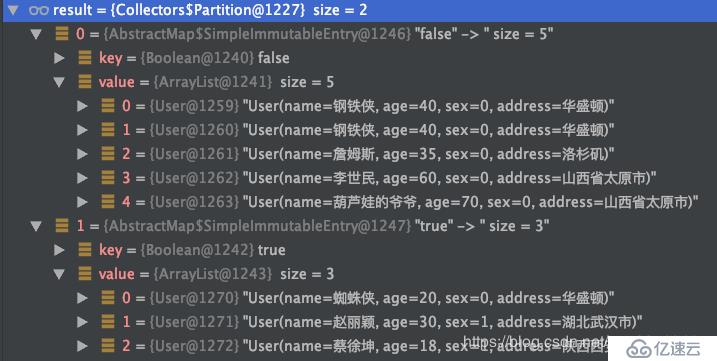
分區與分組的區別在于,分區是按照 true 和 false 來分的,因此partitioningBy 接受的參數的 lambda 也是 T -> boolean
//根據年齡是否小于等于30來分區
Map<Boolean, List<User>> part = list.stream()
.collect(partitioningBy(user -> user.getAge() <= 30));運行結果:
到目前為止,stream的功能我們已經用了很多了,感覺有點眼花繚亂卻無所不能,stream能做的事情遠遠不止這些。
我們可以多學習使用stream,把原來復雜的sql查詢,一遍又一遍地for循環的復雜代碼重構,讓代碼更簡潔易懂,可讀性強。
拓展閱讀:Redis專題(1):構建知識圖譜
Redis專題(2):Redis數據結構底層探秘
作者:楊亨
來源:宜信技術學院
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





