溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
線上nginx的no live upstreams while connecting to upstream 示例分析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
先描述一下環境,前段的負載均衡轉發給nginx,nginx再轉發給后端的應用服務器。
nginx配置文件如下:
upstream ads {
server ap1:8888 max_fails=1 fail_timeout=60s;
server ap2:8888 max_fails=1 fail_timeout=60s;
}
出現的現象是:
日志里面每隔一兩分鐘就會記錄一條類似 *379803415 no live upstreams while connecting to upstream 的日志,
此外,還有大量的“upstream prematurely closed connection while reading response header from upstream”的日志。
我們先看“no live upstreams”的問題。
看字面意思是nginx發現沒有存活的后端了,但是很奇怪的事情是,這段時間一直訪問都正常,并且用wireshark看到的也是有進來的,也有返回的。
現在只能從nginx源碼的角度來看了。
因為是upstream有關的報錯,所以在ngx_http_upstream.c中查找“no live upstreams”的關鍵字,可以找到如下代碼(其實,你會發現,如果在nginx全局代碼中找的話,也只有這個文件里面有這個關鍵字):
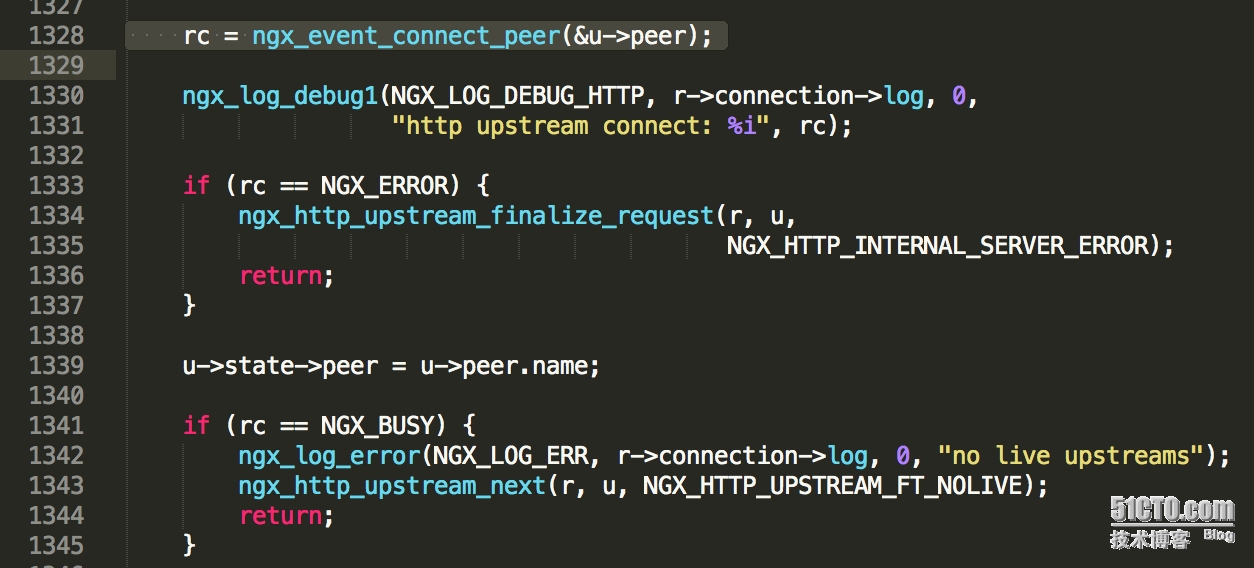
在這里可以看出,當rc等于NGX_BUSY的時候,就會記錄“no live upstreams”的錯誤。
往上看1328行,可以發現rc的值又是ngx_event_connect_peer這個函數返回的。
ngx_event_connect_peer是在event/ngx_event_connect.c中實現的。這個函數中,只有這個地方會返回NGX_BUSY,其他地方都是NGX_OK或者NGX_ERROR或者NGX_AGAIN之類的。
rc = pc->get(pc, pc->data);
if (rc != NGX_OK) {
return rc;
}
這里的pc是指向ngx_peer_connection_t結構體的指針, get是個ngx_event_get_peer_pt的函數指針,具體指向哪里,一時無從得知。接著翻看ngx_http_upstream.c
在ngx_http_upstream_init_main_conf中看到了,如下代碼:
uscfp = umcf->upstreams.elts;
for (i = 0; i < umcf->upstreams.nelts; i++) {
init = uscfp[i]->peer.init_upstream ? uscfp[i]->peer.init_upstream:
ngx_http_upstream_init_round_robin;
if (init(cf, uscfp[i]) != NGX_OK) {
return NGX_CONF_ERROR;
}
}
這里可以看到,默認的配置為輪詢(事實上負載均衡的各個模塊組成了一個鏈表,每次從鏈表到頭開始往后處理,從上面到配置文件可以看出,nginx不會在輪詢前調用其他的模塊),并且用ngx_http_upstream_init_round_robin初始化每個upstream。
再看ngx_http_upstream_init_round_robin函數,里面有如下行:
r->upstream->peer.get = ngx_http_upstream_get_round_robin_peer;
這里把get指針指向了ngx_http_upstream_get_round_robin_peer
在ngx_http_upstream_get_round_robin_peer中,可以看到:
if (peers->single) {
peer = &peers->peer[0];
if (peer->down) {
goto failed;
}
} else {
/* there are several peers */
peer = ngx_http_upstream_get_peer(rrp);
if (peer == NULL) {
goto failed;
}
再看看failed的部分:
failed:
if (peers->next) {
/* ngx_unlock_mutex(peers->mutex); */
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, pc->log, 0, "backup servers");
rrp->peers = peers->next;
n = (rrp->peers->number + (8 * sizeof(uintptr_t) - 1))
/ (8 * sizeof(uintptr_t));
for (i = 0; i < n; i++) {
rrp->tried[i] = 0;
}
rc = ngx_http_upstream_get_round_robin_peer(pc, rrp);
if (rc != NGX_BUSY) {
return rc;
}
/* ngx_lock_mutex(peers->mutex); */
}
/* all peers failed, mark them as live for quick recovery */
for (i = 0; i < peers->number; i++) {
peers->peer[i].fails = 0;
}
/* ngx_unlock_mutex(peers->mutex); */
pc->name = peers->name;
return NGX_BUSY;
這里就真相大白了,如果連接失敗了,就去嘗試連下一個,如果所有的都失敗了,就會進行quick recovery 把每個peer的失敗次數都重置為0,然后再返回一個NGX_BUSY,然后nginx就會打印一條no live upstreams ,最后又回到原始狀態,接著進行轉發了。
這就解釋了no live upstreams之后還能正常訪問。
重新看配置文件,如果其中一臺有一次失敗,nginx就會認為它已經死掉,然后就會把以后的流量全都打到另一臺上面,當另外一臺也有一次失敗的時候,就認為兩個都死掉了,然后quick recovery,然后打印一條日志。
這樣帶來的另一個問題是,如果幾臺同時認定一臺后端已經死掉的時候,會造成流量的不均衡,看zabbix監控的截圖也能看出來:
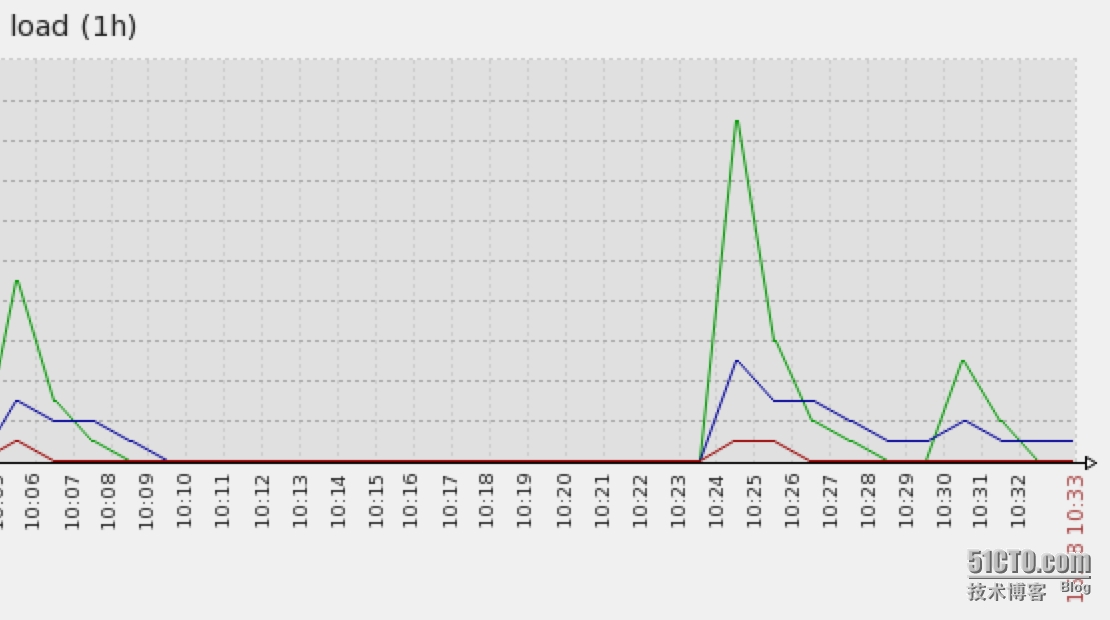
初步的解決方法:
把max_fails從1改成5,效果很明顯,“no live upstreams”出現的概率變少了很多,但卻沒有完全消失。
另外,日志里面還會有大量的“upstream prematurely closed connection while reading response header from upstream”。
這次從源碼上看,在執行ngx_http_upstream_process_header這個函數的時候,會報這個錯,但具體是網絡原因還是其他原因不是很明顯,下面就tcpdump抓一下包。
其中54是nginx前端的負載均衡的地址,171是nginx地址,32是ap1的地址,另外ap2的地址是201
如截圖所示:
請求由負載均衡發到nginx上,nginx先是回應ack給負載均衡,然后跟ap1進行三次握手,隨后發送了一個長度為614的數據包給ap1.然而卻收到了一個ack和fin+ack,從Ack=615可以看出,這兩個包都是針對長度為614的數據包的回應,后端app直接就把連接給關閉掉了!
再然后,nginx回應給后端的app一個ack和fin+ack,從Ack=2可以看出這是對fin+ack的回應。
再然后,nginx就向ap2發出了一個syn包,并且也收到了第一臺返回的ack。
第二張圖:
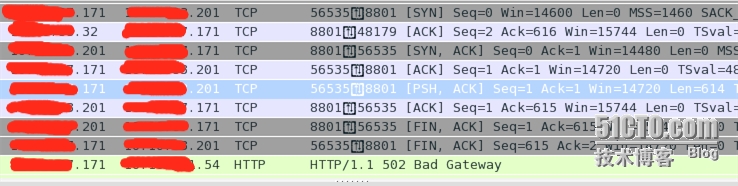
如圖,可以看出,nginx跟ap2三次握手后,也發送了一個請求的數據包,同樣被直接關閉連接了。
隨后,nginx就把502返回給了負載均衡。
這里的抓包又一次從側面支持了上面代碼的分析。
然后把問題反饋給做后端應用的同事了。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





